 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCaixing Wang
Minimax Optimal Transfer Learning for Kernel-based Nonparametric Regression
Oct 21, 2023
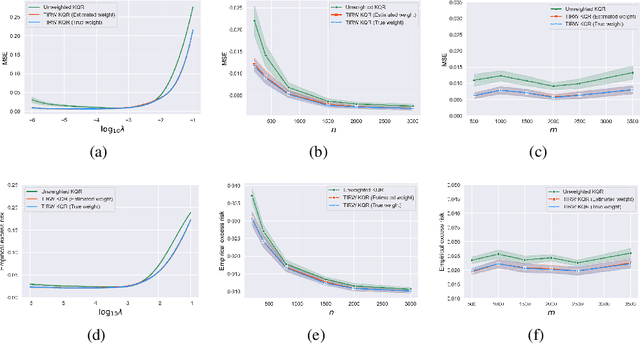
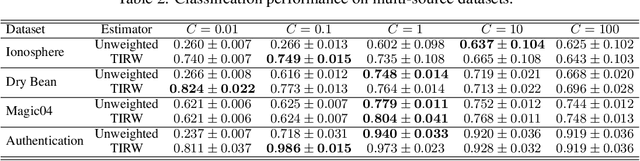
In recent years, transfer learning has garnered significant attention in the machine learning community. Its ability to leverage knowledge from related studies to improve generalization performance in a target study has made it highly appealing. This paper focuses on investigating the transfer learning problem within the context of nonparametric regression over a reproducing kernel Hilbert space. The aim is to bridge the gap between practical effectiveness and theoretical guarantees. We specifically consider two scenarios: one where the transferable sources are known and another where they are unknown. For the known transferable source case, we propose a two-step kernel-based estimator by solely using kernel ridge regression. For the unknown case, we develop a novel method based on an efficient aggregation algorithm, which can automatically detect and alleviate the effects of negative sources. This paper provides the statistical properties of the desired estimators and establishes the minimax optimal rate. Through extensive numerical experiments on synthetic data and real examples, we validate our theoretical findings and demonstrate the effectiveness of our proposed method.
Towards a Unified Analysis of Kernel-based Methods Under Covariate Shift
Oct 19, 2023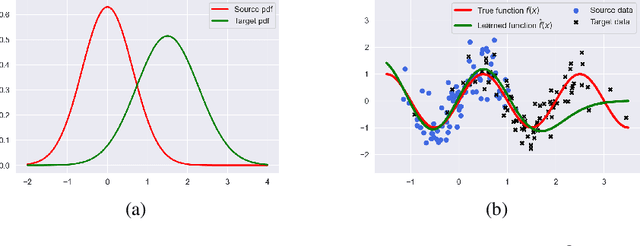

Covariate shift occurs prevalently in practice, where the input distributions of the source and target data are substantially different. Despite its practical importance in various learning problems, most of the existing methods only focus on some specific learning tasks and are not well validated theoretically and numerically. To tackle this problem, we propose a unified analysis of general nonparametric methods in a reproducing kernel Hilbert space (RKHS) under covariate shift. Our theoretical results are established for a general loss belonging to a rich loss function family, which includes many commonly used methods as special cases, such as mean regression, quantile regression, likelihood-based classification, and margin-based classification. Two types of covariate shift problems are the focus of this paper and the sharp convergence rates are established for a general loss function to provide a unified theoretical analysis, which concurs with the optimal results in literature where the squared loss is used. Extensive numerical studies on synthetic and real examples confirm our theoretical findings and further illustrate the effectiveness of our proposed method.