 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCameron Hickert
Cooperation for Scalable Supervision of Autonomy in Mixed Traffic
Dec 14, 2021




Improvements in autonomy offer the potential for positive outcomes in a number of domains, yet guaranteeing their safe deployment is difficult. This work investigates how humans can intelligently supervise agents to achieve some level of safety even when performance guarantees are elusive. The motivating research question is: In safety-critical settings, can we avoid the need to have one human supervise one machine at all times? The paper formalizes this 'scaling supervision' problem, and investigates its application to the safety-critical context of autonomous vehicles (AVs) merging into traffic. It proposes a conservative, reachability-based method to reduce the burden on the AVs' human supervisors, which allows for the establishment of high-confidence upper bounds on the supervision requirements in this setting. Order statistics and traffic simulations with deep reinforcement learning show analytically and numerically that teaming of AVs enables supervision time sublinear in AV adoption. A key takeaway is that, despite present imperfections of AVs, supervision becomes more tractable as AVs are deployed en masse. While this work focuses on AVs, the scalable supervision framework is relevant to a broader array of autonomous control challenges.
Autonomous Attack Mitigation for Industrial Control Systems
Nov 03, 2021

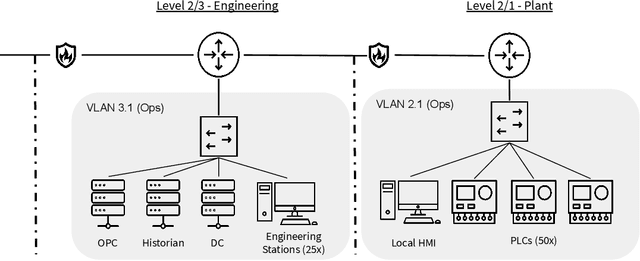

Defending computer networks from cyber attack requires timely responses to alerts and threat intelligence. Decisions about how to respond involve coordinating actions across multiple nodes based on imperfect indicators of compromise while minimizing disruptions to network operations. Currently, playbooks are used to automate portions of a response process, but often leave complex decision-making to a human analyst. In this work, we present a deep reinforcement learning approach to autonomous response and recovery in large industrial control networks. We propose an attention-based neural architecture that is flexible to the size of the network under protection. To train and evaluate the autonomous defender agent, we present an industrial control network simulation environment suitable for reinforcement learning. Experiments show that the learned agent can effectively mitigate advanced attacks that progress with few observable signals over several months before execution. The proposed deep reinforcement learning approach outperforms a fully automated playbook method in simulation, taking less disruptive actions while also defending more nodes on the network. The learned policy is also more robust to changes in attacker behavior than playbook approaches.
Stratified Experience Replay: Correcting Multiplicity Bias in Off-Policy Reinforcement Learning
Feb 22, 2021


Deep Reinforcement Learning (RL) methods rely on experience replay to approximate the minibatched supervised learning setting; however, unlike supervised learning where access to lots of training data is crucial to generalization, replay-based deep RL appears to struggle in the presence of extraneous data. Recent works have shown that the performance of Deep Q-Network (DQN) degrades when its replay memory becomes too large. This suggests that outdated experiences somehow impact the performance of deep RL, which should not be the case for off-policy methods like DQN. Consequently, we re-examine the motivation for sampling uniformly over a replay memory, and find that it may be flawed when using function approximation. We show that -- despite conventional wisdom -- sampling from the uniform distribution does not yield uncorrelated training samples and therefore biases gradients during training. Our theory prescribes a special non-uniform distribution to cancel this effect, and we propose a stratified sampling scheme to efficiently implement it.