 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCasper Wilstrup
Interpretable Symbolic Regression for Data Science: Analysis of the 2022 Competition
Apr 06, 2023
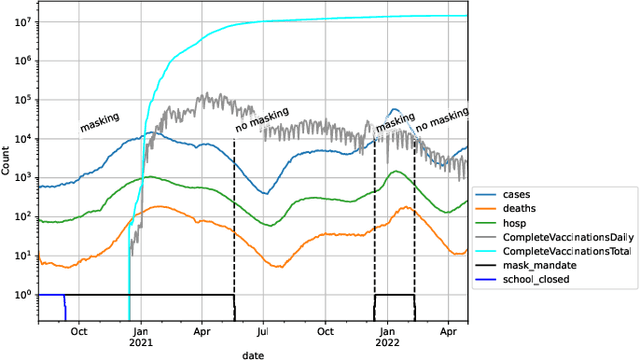

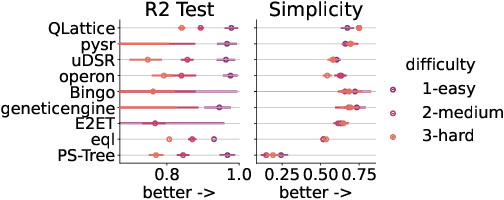
Symbolic regression searches for analytic expressions that accurately describe studied phenomena. The main attraction of this approach is that it returns an interpretable model that can be insightful to users. Historically, the majority of algorithms for symbolic regression have been based on evolutionary algorithms. However, there has been a recent surge of new proposals that instead utilize approaches such as enumeration algorithms, mixed linear integer programming, neural networks, and Bayesian optimization. In order to assess how well these new approaches behave on a set of common challenges often faced in real-world data, we hosted a competition at the 2022 Genetic and Evolutionary Computation Conference consisting of different synthetic and real-world datasets which were blind to entrants. For the real-world track, we assessed interpretability in a realistic way by using a domain expert to judge the trustworthiness of candidate models.We present an in-depth analysis of the results obtained in this competition, discuss current challenges of symbolic regression algorithms and highlight possible improvements for future competitions.
Symbolic regression outperforms other models for small data sets
Apr 16, 2021



Machine learning is often applied to obtain predictions and new understandings of complex phenomena and relationships, but an availability of sufficient data for model training is a widespread problem. Traditional machine learning techniques, such as random forests and gradient boosting, tend to overfit when working with data sets of only a few hundred observations. This study demonstrates that for small training sets of 250 observations, symbolic regression generalises better to out-of-sample data than traditional machine learning frameworks, as measured by the coefficient of determination $R^2$ on the validation set. In 132 out of 240 cases, symbolic regression achieves a higher $R^2$ than any of the other models on the out-of-sample data. Furthermore, symbolic regression also preserves the interpretability of linear models and decision trees, an added benefit to its superior generalization. The second best algorithm was found to be a random forest, which performs best in 37 of the 240 cases. When restricting the comparison to interpretable models, symbolic regression performs best in 184 out of 240 cases.
An Approach to Symbolic Regression Using Feyn
Apr 12, 2021



In this article we introduce the supervised machine learning tool called Feyn. The simulation engine that powers this tool is called the QLattice. The QLattice is a supervised machine learning tool inspired by Richard Feynman's path integral formulation, that explores many potential models that solves a given problem. It formulates these models as graphs that can be interpreted as mathematical equations, allowing the user to completely decide on the trade-off between interpretability, complexity and model performance. We touch briefly upon the inner workings of the QLattice, and show how to apply the python package, Feyn, to scientific problems. We show how it differs from traditional machine learning approaches, what it has in common with them, as well as some of its commonalities with symbolic regression. We describe the benefits of this approach as opposed to black box models. To illustrate this, we go through an investigative workflow using a basic data set and show how the QLattice can help you reason about the relationships between your features and do data discovery.