 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCezary Kaliszyk
Learning Guided Automated Reasoning: A Brief Survey
Mar 06, 2024
Automated theorem provers and formal proof assistants are general reasoning systems that are in theory capable of proving arbitrarily hard theorems, thus solving arbitrary problems reducible to mathematics and logical reasoning. In practice, such systems however face large combinatorial explosion, and therefore include many heuristics and choice points that considerably influence their performance. This is an opportunity for trained machine learning predictors, which can guide the work of such reasoning systems. Conversely, deductive search supported by the notion of logically valid proof allows one to train machine learning systems on large reasoning corpora. Such bodies of proof are usually correct by construction and when combined with more and more precise trained guidance they can be boostrapped into very large corpora, with increasingly long reasoning chains and possibly novel proof ideas. In this paper we provide an overview of several automated reasoning and theorem proving domains and the learning and AI methods that have been so far developed for them. These include premise selection, proof guidance in several settings, AI systems and feedback loops iterating between reasoning and learning, and symbolic classification problems.
MizAR 60 for Mizar 50
Mar 12, 2023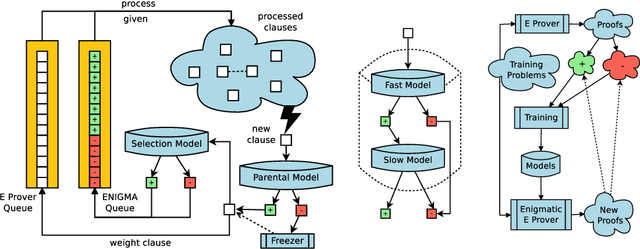
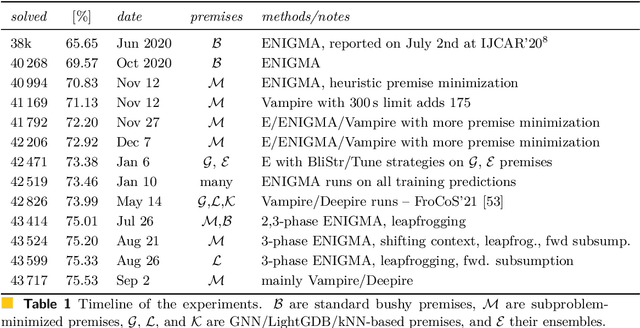
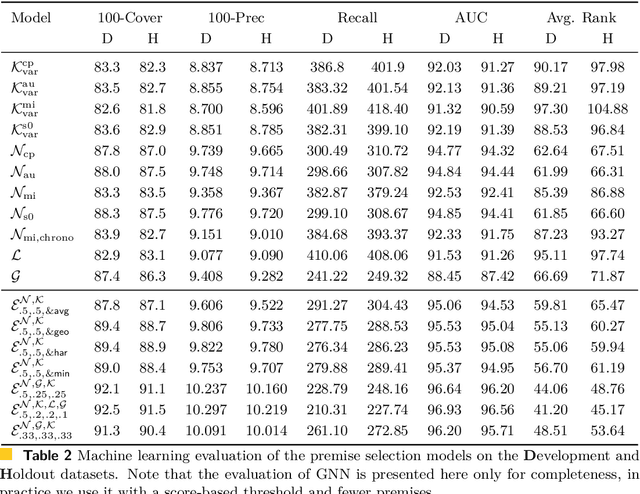

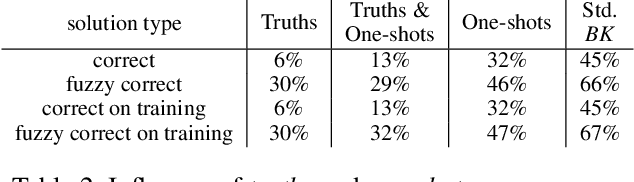
As a present to Mizar on its 50th anniversary, we develop an AI/TP system that automatically proves about 60\% of the Mizar theorems in the hammer setting. We also automatically prove 75\% of the Mizar theorems when the automated provers are helped by using only the premises used in the human-written Mizar proofs. We describe the methods and large-scale experiments leading to these results. This includes in particular the E and Vampire provers, their ENIGMA and Deepire learning modifications, a number of learning-based premise selection methods, and the incremental loop that interleaves growing a corpus of millions of ATP proofs with training increasingly strong AI/TP systems on them. We also present a selection of Mizar problems that were proved automatically.
Differentiable Inductive Logic Programming in High-Dimensional Space
Aug 13, 2022

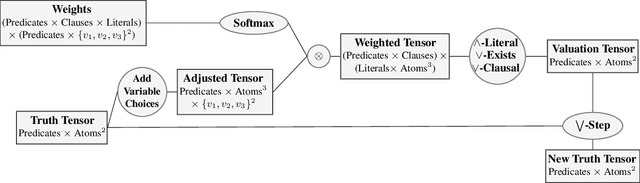
Synthesizing large logic programs through Inductive Logic Programming (ILP) typically requires intermediate definitions. However, cluttering the hypothesis space with intensional predicates often degrades performance. In contrast, gradient descent provides an efficient way to find solutions within such high-dimensional spaces. Neuro-symbolic ILP approaches have not fully exploited this so far. We propose an approach to ILP-based synthesis benefiting from large-scale predicate invention exploiting the efficacy of high-dimensional gradient descent. We find symbolic solutions containing upwards of ten auxiliary definitions. This is beyond the achievements of existing neuro-symbolic ILP systems, thus constituting a milestone in the field.
The Isabelle ENIGMA
May 04, 2022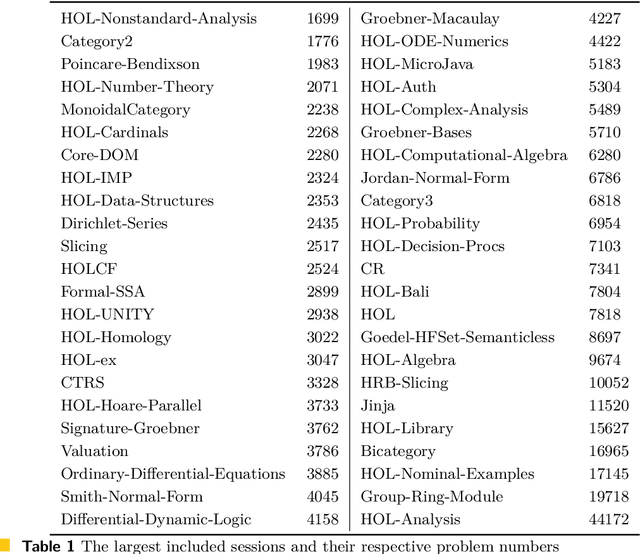



We significantly improve the performance of the E automated theorem prover on the Isabelle Sledgehammer problems by combining learning and theorem proving in several ways. In particular, we develop targeted versions of the ENIGMA guidance for the Isabelle problems, targeted versions of neural premise selection, and targeted strategies for E. The methods are trained in several iterations over hundreds of thousands untyped and typed first-order problems extracted from Isabelle. Our final best single-strategy ENIGMA and premise selection system improves the best previous version of E by 25.3% in 15 seconds, outperforming also all other previous ATP and SMT systems.
Adversarial Learning to Reason in an Arbitrary Logic
Apr 06, 2022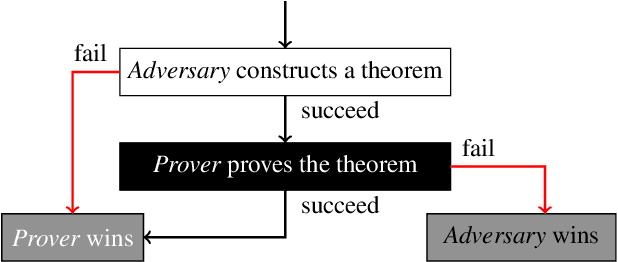

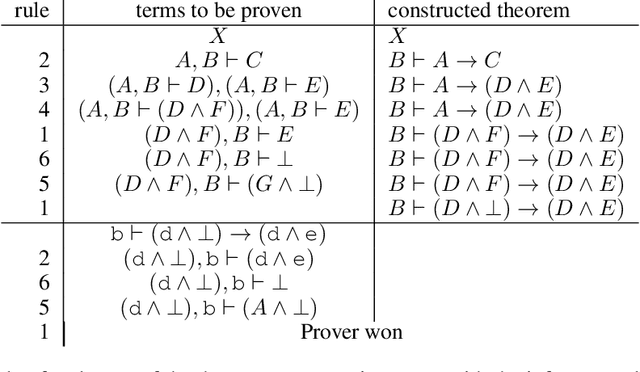
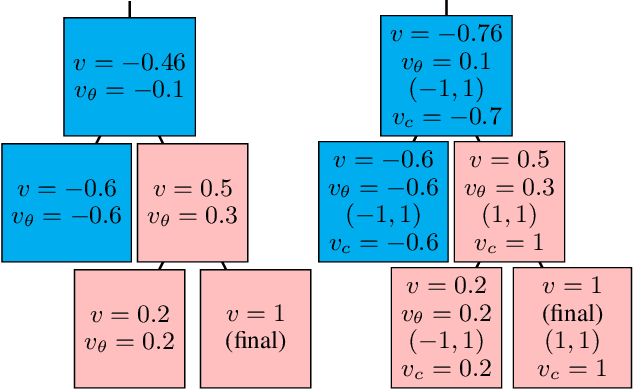
Existing approaches to learning to prove theorems focus on particular logics and datasets. In this work, we propose Monte-Carlo simulations guided by reinforcement learning that can work in an arbitrarily specified logic, without any human knowledge or set of problems. Since the algorithm does not need any training dataset, it is able to learn to work with any logical foundation, even when there is no body of proofs or even conjectures available. We practically demonstrate the feasibility of the approach in multiple logical systems. The approach is stronger than training on randomly generated data but weaker than the approaches trained on tailored axiom and conjecture sets. It however allows us to apply machine learning to automated theorem proving for many logics, where no such attempts have been tried to date, such as intuitionistic logic or linear logic.
Learning Higher-Order Programs without Meta-Interpretive Learning
Jan 14, 2022
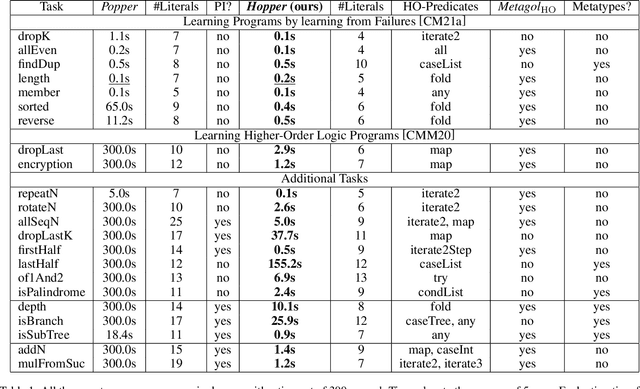
Learning complex programs through inductive logic programming (ILP) remains a formidable challenge. Existing higher-order enabled ILP systems show improved accuracy and learning performance, though remain hampered by the limitations of the underlying learning mechanism. Experimental results show that our extension of the versatile Learning From Failures paradigm by higher-order definitions significantly improves learning performance without the burdensome human guidance required by existing systems. Our theoretical framework captures a class of higher-order definitions preserving soundness of existing subsumption-based pruning methods.
JEFL: Joint Embedding of Formal Proof Libraries
Jul 21, 2021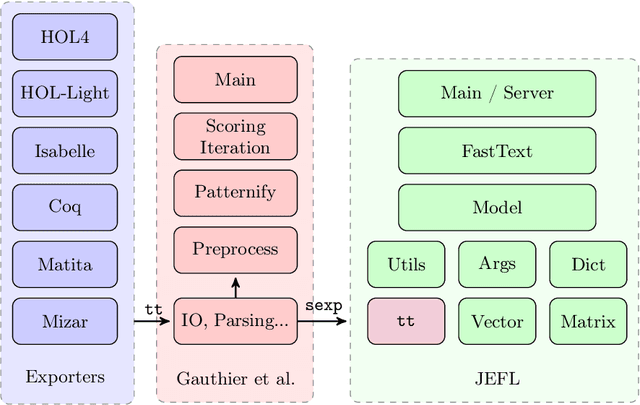

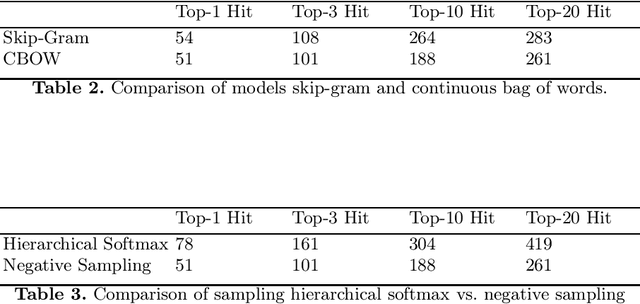
The heterogeneous nature of the logical foundations used in different interactive proof assistant libraries has rendered discovery of similar mathematical concepts among them difficult. In this paper, we compare a previously proposed algorithm for matching concepts across libraries with our unsupervised embedding approach that can help us retrieve similar concepts. Our approach is based on the fasttext implementation of Word2Vec, on top of which a tree traversal module is added to adapt its algorithm to the representation format of our data export pipeline. We compare the explainability, customizability, and online-servability of the approaches and argue that the neural embedding approach has more potential to be integrated into an interactive proof assistant.
Online Machine Learning Techniques for Coq: A Comparison
Apr 12, 2021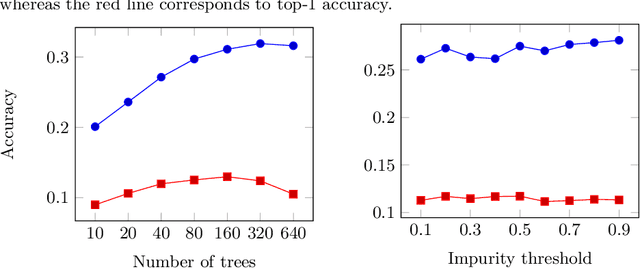
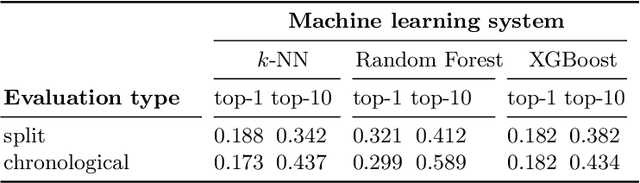
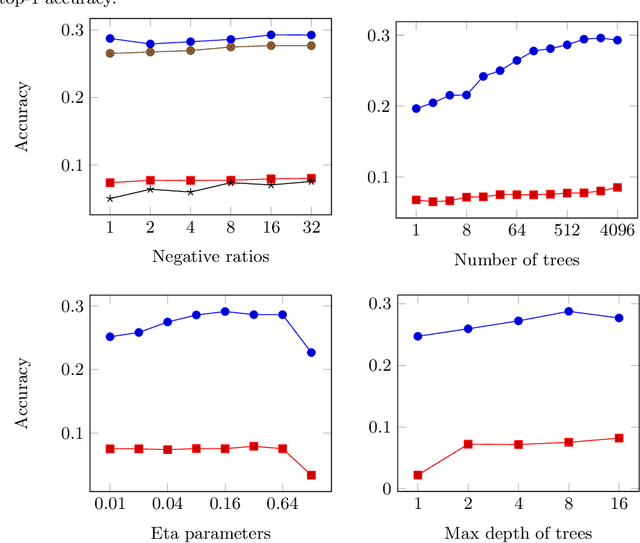
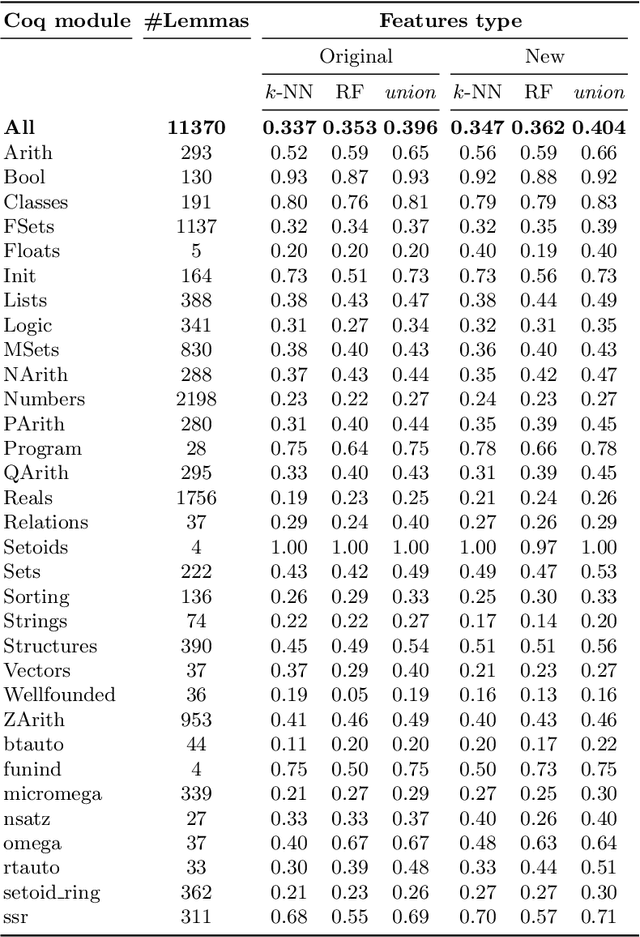
We present a comparison of several online machine learning techniques for tactical learning and proving in the Coq proof assistant. This work builds on top of Tactician, a plugin for Coq that learns from proofs written by the user to synthesize new proofs. This learning happens in an online manner -- meaning that Tactician's machine learning model is updated immediately every time the user performs a step in an interactive proof. This has important advantages compared to the more studied offline learning systems: (1) it provides the user with a seamless, interactive experience with Tactician and, (2) it takes advantage of locality of proof similarity, which means that proofs similar to the current proof are likely to be found close by. We implement two online methods, namely approximate $k$-nearest neighbors based on locality sensitive hashing forests and random decision forests. Additionally, we conduct experiments with gradient boosted trees in an offline setting using XGBoost. We compare the relative performance of Tactician using these three learning methods on Coq's standard library.
Disambiguating Symbolic Expressions in Informal Documents
Jan 25, 2021

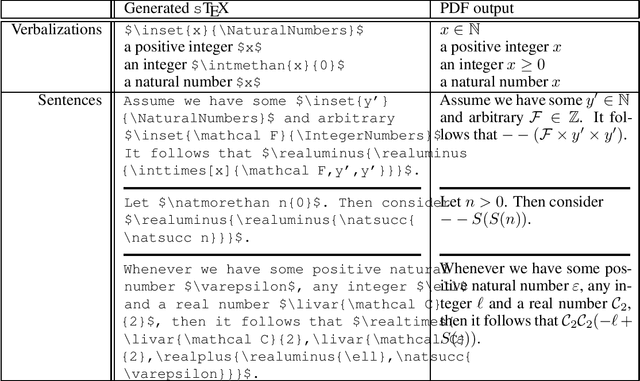
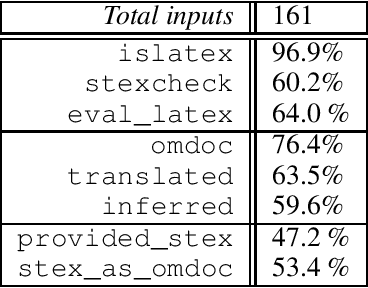
We propose the task of disambiguating symbolic expressions in informal STEM documents in the form of LaTeX files - that is, determining their precise semantics and abstract syntax tree - as a neural machine translation task. We discuss the distinct challenges involved and present a dataset with roughly 33,000 entries. We evaluated several baseline models on this dataset, which failed to yield even syntactically valid LaTeX before overfitting. Consequently, we describe a methodology using a transformer language model pre-trained on sources obtained from arxiv.org, which yields promising results despite the small size of the dataset. We evaluate our model using a plurality of dedicated techniques, taking the syntax and semantics of symbolic expressions into account.
A Study of Continuous Vector Representationsfor Theorem Proving
Jan 22, 2021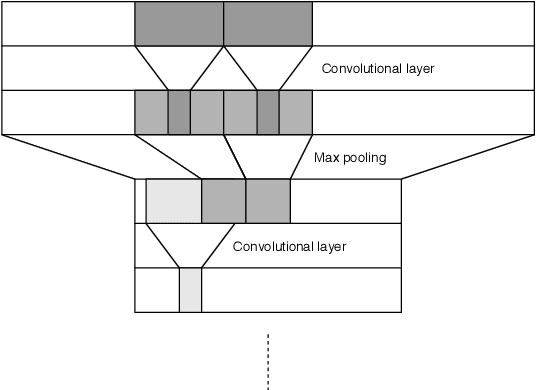
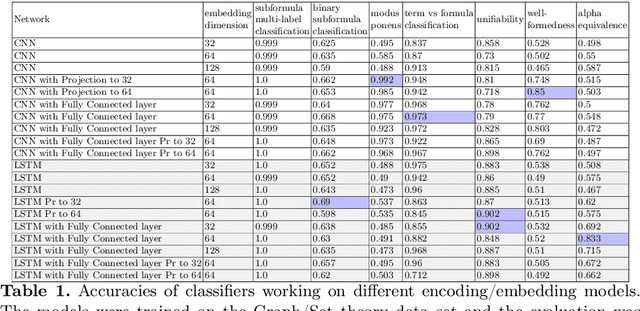
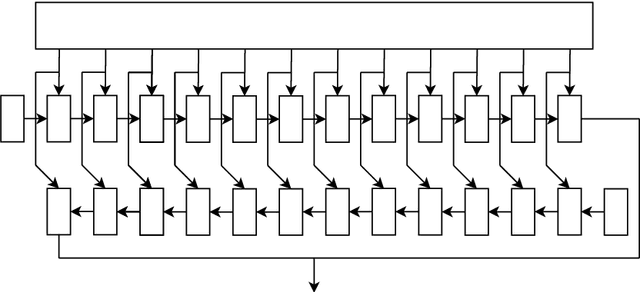
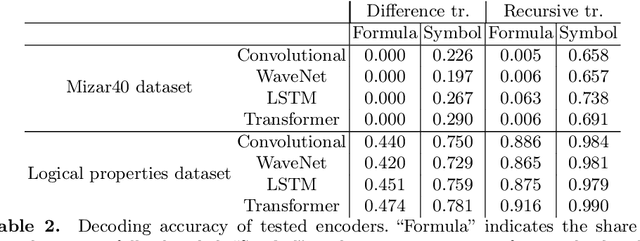
Applying machine learning to mathematical terms and formulas requires a suitable representation of formulas that is adequate for AI methods. In this paper, we develop an encoding that allows for logical properties to be preserved and is additionally reversible. This means that the tree shape of a formula including all symbols can be reconstructed from the dense vector representation. We do that by training two decoders: one that extracts the top symbol of the tree and one that extracts embedding vectors of subtrees. The syntactic and semantic logical properties that we aim to reserve include both structural formula properties, applicability of natural deduction steps, and even more complex operations like unifiability. We propose datasets that can be used to train these syntactic and semantic properties. We evaluate the viability of the developed encoding across the proposed datasets as well as for the practical theorem proving problem of premise selection in the Mizar corpus.