 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChan Young Park
CulturalTeaming: AI-Assisted Interactive Red-Teaming for Challenging LLMs' (Lack of) Multicultural Knowledge
Apr 10, 2024
Frontier large language models (LLMs) are developed by researchers and practitioners with skewed cultural backgrounds and on datasets with skewed sources. However, LLMs' (lack of) multicultural knowledge cannot be effectively assessed with current methods for developing benchmarks. Existing multicultural evaluations primarily rely on expensive and restricted human annotations or potentially outdated internet resources. Thus, they struggle to capture the intricacy, dynamics, and diversity of cultural norms. LLM-generated benchmarks are promising, yet risk propagating the same biases they are meant to measure. To synergize the creativity and expert cultural knowledge of human annotators and the scalability and standardizability of LLM-based automation, we introduce CulturalTeaming, an interactive red-teaming system that leverages human-AI collaboration to build truly challenging evaluation dataset for assessing the multicultural knowledge of LLMs, while improving annotators' capabilities and experiences. Our study reveals that CulturalTeaming's various modes of AI assistance support annotators in creating cultural questions, that modern LLMs fail at, in a gamified manner. Importantly, the increased level of AI assistance (e.g., LLM-generated revision hints) empowers users to create more difficult questions with enhanced perceived creativity of themselves, shedding light on the promises of involving heavier AI assistance in modern evaluation dataset creation procedures. Through a series of 1-hour workshop sessions, we gather CULTURALBENCH-V0.1, a compact yet high-quality evaluation dataset with users' red-teaming attempts, that different families of modern LLMs perform with accuracy ranging from 37.7% to 72.2%, revealing a notable gap in LLMs' multicultural proficiency.
What Constitutes a Faithful Summary? Preserving Author Perspectives in News Summarization
Nov 16, 2023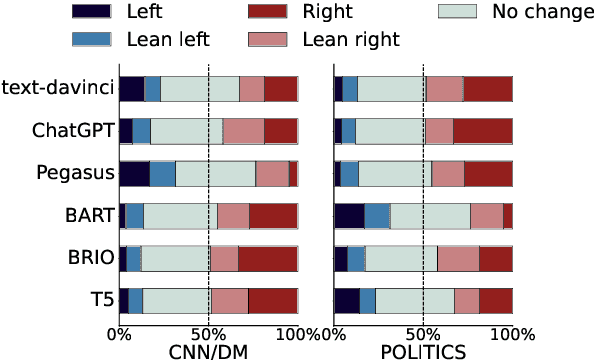

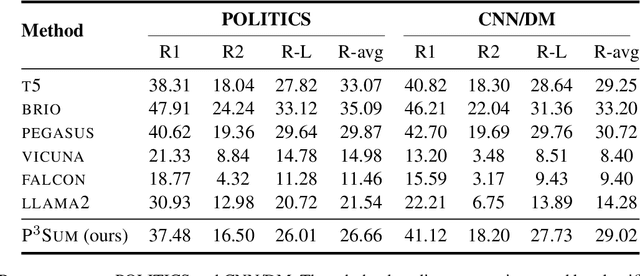
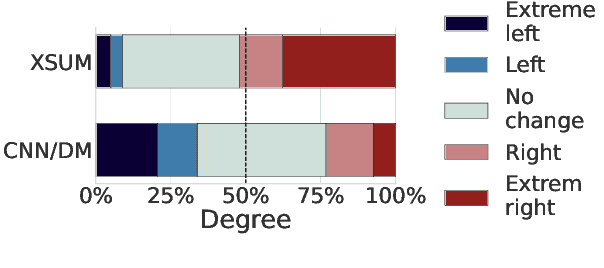
In this work, we take a first step towards designing summarization systems that are faithful to the author's opinions and perspectives. Focusing on a case study of preserving political perspectives in news summarization, we find that existing approaches alter the political opinions and stances of news articles in more than 50% of summaries, misrepresenting the intent and perspectives of the news authors. We thus propose P^3Sum, a diffusion model-based summarization approach controlled by political perspective classifiers. In P^3Sum, the political leaning of a generated summary is iteratively evaluated at each decoding step, and any drift from the article's original stance incurs a loss back-propagated to the embedding layers, steering the political stance of the summary at inference time. Extensive experiments on three news summarization datasets demonstrate that P^3Sum outperforms state-of-the-art summarization systems and large language models by up to 11.4% in terms of the success rate of stance preservation, with on-par performance on standard summarization utility metrics. These findings highlight the lacunae that even for state-of-the-art models it is still challenging to preserve author perspectives in news summarization, while P^3Sum presents an important first step towards evaluating and developing summarization systems that are faithful to author intent and perspectives.
Gen-Z: Generative Zero-Shot Text Classification with Contextualized Label Descriptions
Nov 13, 2023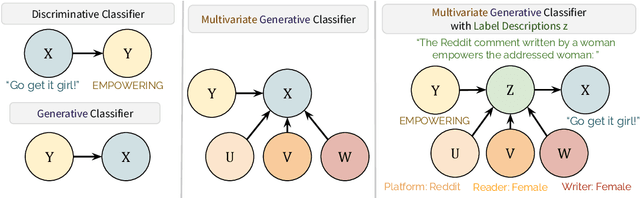
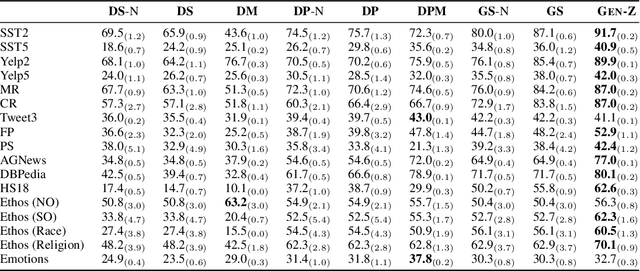
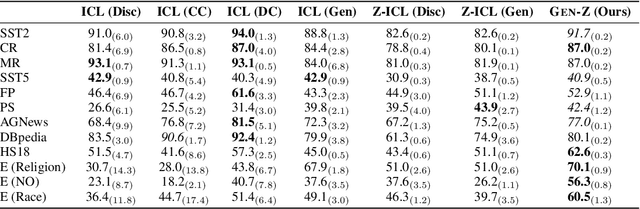
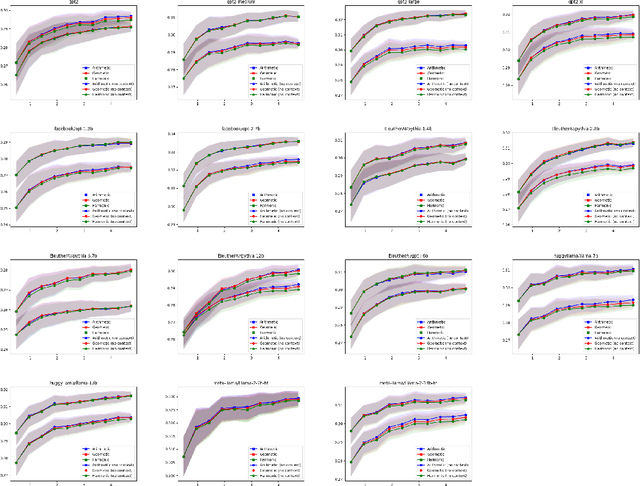
Language model (LM) prompting--a popular paradigm for solving NLP tasks--has been shown to be susceptible to miscalibration and brittleness to slight prompt variations, caused by its discriminative prompting approach, i.e., predicting the label given the input. To address these issues, we propose Gen-Z--a generative prompting framework for zero-shot text classification. GEN-Z is generative, as it measures the LM likelihood of input text, conditioned on natural language descriptions of labels. The framework is multivariate, as label descriptions allow us to seamlessly integrate additional contextual information about the labels to improve task performance. On various standard classification benchmarks, with six open-source LM families, we show that zero-shot classification with simple contextualization of the data source of the evaluation set consistently outperforms both zero-shot and few-shot baselines while improving robustness to prompt variations. Further, our approach enables personalizing classification in a zero-shot manner by incorporating author, subject, or reader information in the label descriptions.
TalkUp: A Novel Dataset Paving the Way for Understanding Empowering Language
May 23, 2023



Empowering language is important in many real-world contexts, from education to workplace dynamics to healthcare. Though language technologies are growing more prevalent in these contexts, empowerment has not been studied in NLP, and moreover, it is inherently challenging to operationalize because of its subtle, implicit nature. This work presents the first computational exploration of empowering language. We first define empowerment detection as a new task, grounding it in linguistic and social psychology literature. We then crowdsource a novel dataset of Reddit posts labeled for empowerment, reasons why these posts are empowering to readers, and the social relationships between posters and readers. Our preliminary analyses show that this dataset, which we call TalkUp, can be used to train language models that capture empowering and disempowering language. More broadly, as it is rich with the ambiguities and diverse interpretations of real-world language, TalkUp provides an avenue to explore implication, presuppositions, and how social context influences the meaning of language.
Analyzing Norm Violations in Live-Stream Chat
May 18, 2023
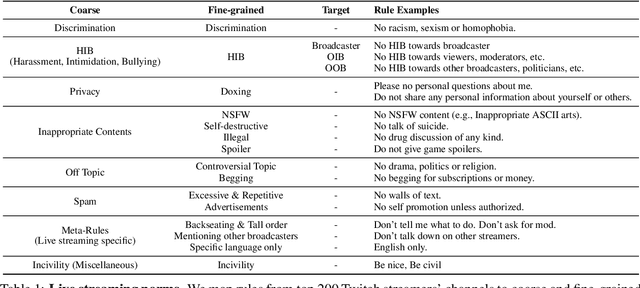
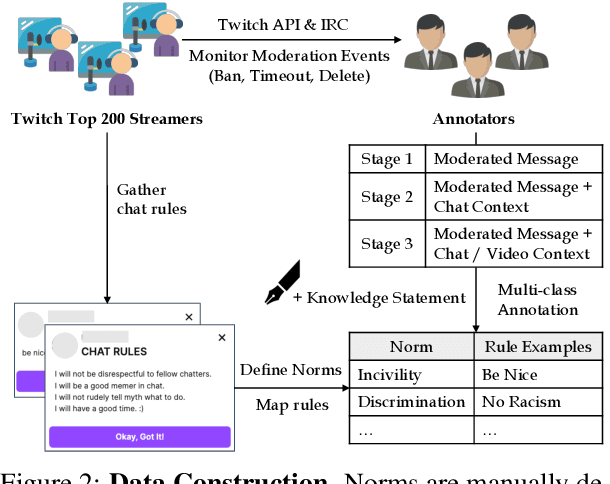

Toxic language, such as hate speech, can deter users from participating in online communities and enjoying popular platforms. Previous approaches to detecting toxic language and norm violations have been primarily concerned with conversations from online forums and social media, such as Reddit and Twitter. These approaches are less effective when applied to conversations on live-streaming platforms, such as Twitch and YouTube Live, as each comment is only visible for a limited time and lacks a thread structure that establishes its relationship with other comments. In this work, we share the first NLP study dedicated to detecting norm violations in conversations on live-streaming platforms. We define norm violation categories in live-stream chats and annotate 4,583 moderated comments from Twitch. We articulate several facets of live-stream data that differ from other forums, and demonstrate that existing models perform poorly in this setting. By conducting a user study, we identify the informational context humans use in live-stream moderation, and train models leveraging context to identify norm violations. Our results show that appropriate contextual information can boost moderation performance by 35\%.
From Pretraining Data to Language Models to Downstream Tasks: Tracking the Trails of Political Biases Leading to Unfair NLP Models
May 15, 2023



Large language models (LMs) are pretrained on diverse data sources: news, discussion forums, books, online encyclopedias. A significant portion of this data includes facts and opinions which, on one hand, celebrate democracy and diversity of ideas, and on the other hand are inherently socially biased. Our work develops new methods to (1) measure media biases in LMs trained on such corpora, along the social and economic axes, and (2) measure the fairness of downstream NLP models trained on top of politically biased LMs. We focus on hate speech and misinformation detection, aiming to empirically quantify the effects of political (social, economic) biases in pretraining data on the fairness of high-stakes social-oriented tasks. Our findings reveal that pretrained LMs do have political leanings which reinforce the polarization present in pretraining corpora, propagating social biases into hate speech predictions and media biases into misinformation detectors. We discuss the implications of our findings for NLP research and propose future directions to mitigate the unfairness.
VoynaSlov: A Data Set of Russian Social Media Activity during the 2022 Ukraine-Russia War
May 24, 2022



In this report, we describe a new data set called VoynaSlov which contains 21M+ Russian-language social media activities (i.e. tweets, posts, comments) made by Russian media outlets and by the general public during the time of war between Ukraine and Russia. We scraped the data from two major platforms that are widely used in Russia: Twitter and VKontakte (VK), a Russian social media platform based in Saint Petersburg commonly referred to as "Russian Facebook". We provide descriptions of our data collection process and data statistics that compare state-affiliated and independent Russian media, and also the two platforms, VK and Twitter. The main differences that distinguish our data from previously released data related to the ongoing war are its focus on Russian media and consideration of state-affiliation as well as the inclusion of data from VK, which is more suitable than Twitter for understanding Russian public sentiment considering its wide use within Russia. We hope our data set can facilitate future research on information warfare and ultimately enable the reduction and prevention of disinformation and opinion manipulation campaigns. The data set is available at https://github.com/chan0park/VoynaSlov and will be regularly updated as we continuously collect more data.
Detecting Community Sensitive Norm Violations in Online Conversations
Oct 09, 2021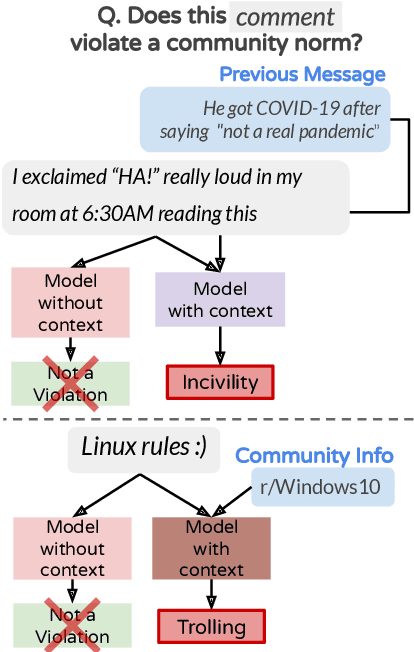
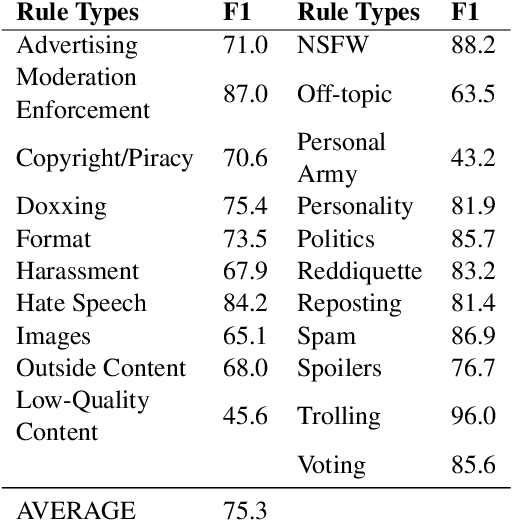

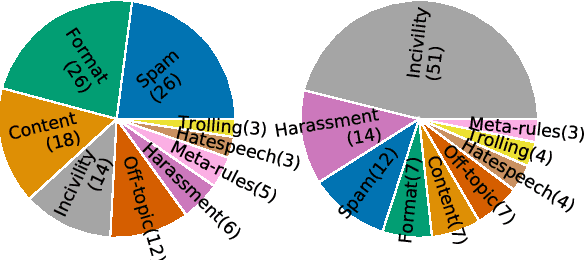
Online platforms and communities establish their own norms that govern what behavior is acceptable within the community. Substantial effort in NLP has focused on identifying unacceptable behaviors and, recently, on forecasting them before they occur. However, these efforts have largely focused on toxicity as the sole form of community norm violation. Such focus has overlooked the much larger set of rules that moderators enforce. Here, we introduce a new dataset focusing on a more complete spectrum of community norms and their violations in the local conversational and global community contexts. We introduce a series of models that use this data to develop context- and community-sensitive norm violation detection, showing that these changes give high performance.
Controlled Analyses of Social Biases in Wikipedia Bios
Dec 31, 2020



Social biases on Wikipedia, a widely-read global platform, could greatly influence public opinion. While prior research has examined man/woman gender bias in biography articles, possible influences of confounding variables limit conclusions. In this work, we present a methodology for reducing the effects of confounding variables in analyses of Wikipedia biography pages. Given a target corpus for analysis (e.g. biography pages about women), we present a method for constructing a comparison corpus that matches the target corpus in as many attributes as possible, except the target attribute (e.g. the gender of the subject). We evaluate our methodology by developing metrics to measure how well the comparison corpus aligns with the target corpus. We then examine how articles about gender and racial minorities (cisgender women, non-binary people, transgender women, and transgender men; African American, Asian American, and Hispanic/Latinx American people) differ from other articles, including analyses driven by social theories like intersectionality. In addition to identifying suspect social biases, our results show that failing to control for confounding variables can result in different conclusions and mask biases. Our contributions include methodology that facilitates further analyses of bias in Wikipedia articles, findings that can aid Wikipedia editors in reducing biases, and framework and evaluation metrics to guide future work in this area.
Multilingual Contextual Affective Analysis of LGBT People Portrayals in Wikipedia
Oct 21, 2020



Specific lexical choices in how people are portrayed both reflect the writer's attitudes towards people in the narrative and influence the audience's reactions. Prior work has examined descriptions of people in English using contextual affective analysis, a natural language processing (NLP) technique that seeks to analyze how people are portrayed along dimensions of power, agency, and sentiment. Our work presents an extension of this methodology to multilingual settings, which is enabled by a new corpus that we collect and a new multilingual model. We additionally show how word connotations differ across languages and cultures, which makes existing English datasets and methods difficult to generalize. We then demonstrate the usefulness of our method by analyzing Wikipedia biography pages of members of the LGBT community across three languages: English, Russian, and Spanish. Our results show systematic differences in how the LGBT community is portrayed across languages, surfacing cultural differences in narratives and signs of social biases. Practically, this model can be used to surface Wikipedia articles for further manual analysis---articles that might contain content gaps or an imbalanced representation of particular social groups.