 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChang Ye
Open RL Benchmark: Comprehensive Tracked Experiments for Reinforcement Learning
Feb 05, 2024
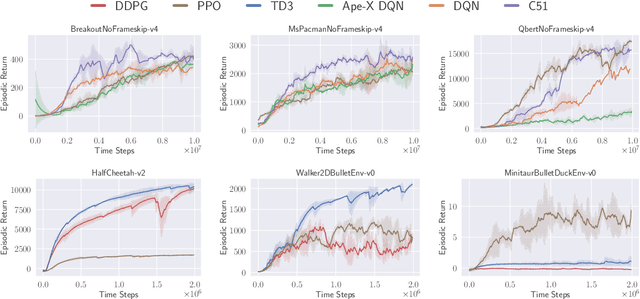
In many Reinforcement Learning (RL) papers, learning curves are useful indicators to measure the effectiveness of RL algorithms. However, the complete raw data of the learning curves are rarely available. As a result, it is usually necessary to reproduce the experiments from scratch, which can be time-consuming and error-prone. We present Open RL Benchmark, a set of fully tracked RL experiments, including not only the usual data such as episodic return, but also all algorithm-specific and system metrics. Open RL Benchmark is community-driven: anyone can download, use, and contribute to the data. At the time of writing, more than 25,000 runs have been tracked, for a cumulative duration of more than 8 years. Open RL Benchmark covers a wide range of RL libraries and reference implementations. Special care is taken to ensure that each experiment is precisely reproducible by providing not only the full parameters, but also the versions of the dependencies used to generate it. In addition, Open RL Benchmark comes with a command-line interface (CLI) for easy fetching and generating figures to present the results. In this document, we include two case studies to demonstrate the usefulness of Open RL Benchmark in practice. To the best of our knowledge, Open RL Benchmark is the first RL benchmark of its kind, and the authors hope that it will improve and facilitate the work of researchers in the field.
CleanRL: High-quality Single-file Implementations of Deep Reinforcement Learning Algorithms
Nov 16, 2021
CleanRL is an open-source library that provides high-quality single-file implementations of Deep Reinforcement Learning algorithms. It provides a simpler yet scalable developing experience by having a straightforward codebase and integrating production tools to help interact and scale experiments. In CleanRL, we put all details of an algorithm into a single file, making these performance-relevant details easier to recognize. Additionally, an experiment tracking feature is available to help log metrics, hyperparameters, videos of an agent's gameplay, dependencies, and more to the cloud. Despite succinct implementations, we have also designed tools to help scale, at one point orchestrating experiments on more than 2000 machines simultaneously via Docker and cloud providers. Finally, we have ensured the quality of the implementations by benchmarking against a variety of environments. The source code of CleanRL can be found at https://github.com/vwxyzjn/cleanrl
Rotation, Translation, and Cropping for Zero-Shot Generalization
Jan 27, 2020



Deep Reinforcement Learning (DRL) has shown impressive performance on domains with visual inputs, in particular various games. However, the agent is usually trained on a fixed environment, e.g. a fixed number of levels. A growing mass of evidence suggests that these trained models fail to generalize to even slight variations of the environments they were trained on. This paper advances the hypothesis that the lack of generalization is partly due to the input representation, and explores how rotation, cropping and translation could increase generality. We show that a cropped, translated and rotated observation can get better generalization on unseen levels of a two-dimensional arcade game. The generality of the agent is evaluated on a set of human-designed levels.