 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChangyang She
Intelligent Mode-switching Framework for Teleoperation
Feb 08, 2024
Teleoperation can be very difficult due to limited perception, high communication latency, and limited degrees of freedom (DoFs) at the operator side. Autonomous teleoperation is proposed to overcome this difficulty by predicting user intentions and performing some parts of the task autonomously to decrease the demand on the operator and increase the task completion rate. However, decision-making for mode-switching is generally assumed to be done by the operator, which brings an extra DoF to be controlled by the operator and introduces extra mental demand. On the other hand, the communication perspective is not investigated in the current literature, although communication imperfections and resource limitations are the main bottlenecks for teleoperation. In this study, we propose an intelligent mode-switching framework by jointly considering mode-switching and communication systems. User intention recognition is done at the operator side. Based on user intention recognition, a deep reinforcement learning (DRL) agent is trained and deployed at the operator side to seamlessly switch between autonomous and teleoperation modes. A real-world data set is collected from our teleoperation testbed to train both user intention recognition and DRL algorithms. Our results show that the proposed framework can achieve up to 50% communication load reduction with improved task completion probability.
Secure Deep Reinforcement Learning for Dynamic Resource Allocation in Wireless MEC Networks
Dec 13, 2023This paper proposes a blockchain-secured deep reinforcement learning (BC-DRL) optimization framework for {data management and} resource allocation in decentralized {wireless mobile edge computing (MEC)} networks. In our framework, {we design a low-latency reputation-based proof-of-stake (RPoS) consensus protocol to select highly reliable blockchain-enabled BSs to securely store MEC user requests and prevent data tampering attacks.} {We formulate the MEC resource allocation optimization as a constrained Markov decision process that balances minimum processing latency and denial-of-service (DoS) probability}. {We use the MEC aggregated features as the DRL input to significantly reduce the high-dimensionality input of the remaining service processing time for individual MEC requests. Our designed constrained DRL effectively attains the optimal resource allocations that are adapted to the dynamic DoS requirements. We provide extensive simulation results and analysis to} validate that our BC-DRL framework achieves higher security, reliability, and resource utilization efficiency than benchmark blockchain consensus protocols and {MEC} resource allocation algorithms.
Graph Neural Network-Based Bandwidth Allocation for Secure Wireless Communications
Dec 13, 2023This paper designs a graph neural network (GNN) to improve bandwidth allocations for multiple legitimate wireless users transmitting to a base station in the presence of an eavesdropper. To improve the privacy and prevent eavesdropping attacks, we propose a user scheduling algorithm to schedule users satisfying an instantaneous minimum secrecy rate constraint. Based on this, we optimize the bandwidth allocations with three algorithms namely iterative search (IvS), GNN-based supervised learning (GNN-SL), and GNN-based unsupervised learning (GNN-USL). We present a computational complexity analysis which shows that GNN-SL and GNN-USL can be more efficient compared to IvS which is limited by the bandwidth block size. Numerical simulation results highlight that our proposed GNN-based resource allocations can achieve a comparable sum secrecy rate compared to IvS with significantly lower computational complexity. Furthermore, we observe that the GNN approach is more robust to uncertainties in the eavesdropper's channel state information, especially compared with the best channel allocation scheme.
Task-Oriented Cross-System Design for Timely and Accurate Modeling in the Metaverse
Sep 11, 2023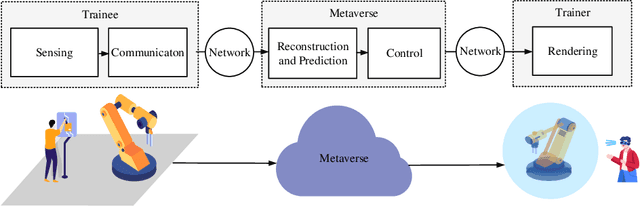
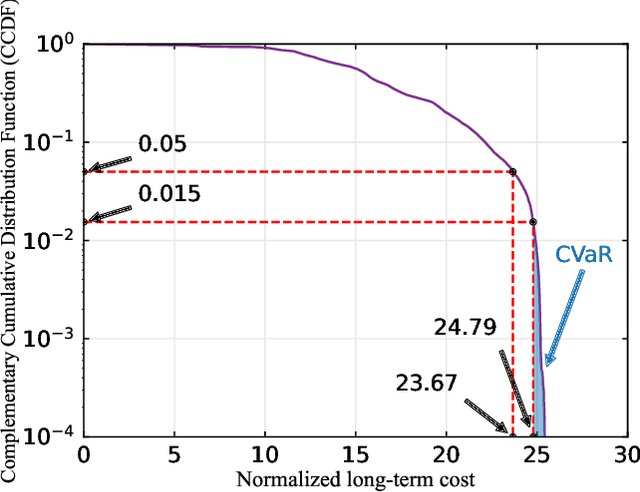

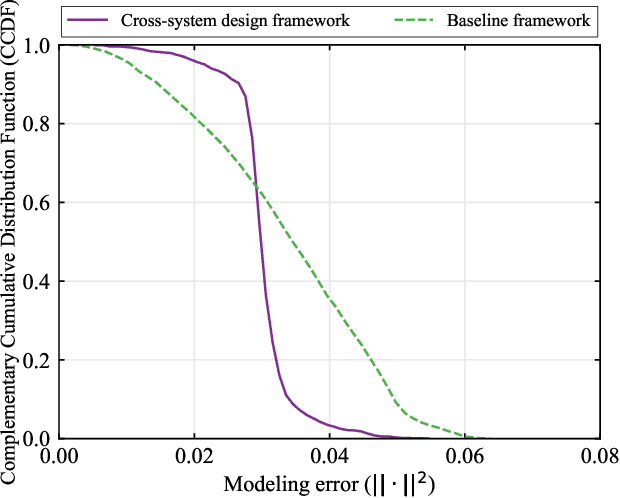
In this paper, we establish a task-oriented cross-system design framework to minimize the required packet rate for timely and accurate modeling of a real-world robotic arm in the Metaverse, where sensing, communication, prediction, control, and rendering are considered. To optimize a scheduling policy and prediction horizons, we design a Constraint Proximal Policy Optimization(C-PPO) algorithm by integrating domain knowledge from relevant systems into the advanced reinforcement learning algorithm, Proximal Policy Optimization(PPO). Specifically, the Jacobian matrix for analyzing the motion of the robotic arm is included in the state of the C-PPO algorithm, and the Conditional Value-at-Risk(CVaR) of the state-value function characterizing the long-term modeling error is adopted in the constraint. Besides, the policy is represented by a two-branch neural network determining the scheduling policy and the prediction horizons, respectively. To evaluate our algorithm, we build a prototype including a real-world robotic arm and its digital model in the Metaverse. The experimental results indicate that domain knowledge helps to reduce the convergence time and the required packet rate by up to 50%, and the cross-system design framework outperforms a baseline framework in terms of the required packet rate and the tail distribution of the modeling error.
Task-Oriented Metaverse Design in the 6G Era
Jun 05, 2023



As an emerging concept, the Metaverse has the potential to revolutionize the social interaction in the post-pandemic era by establishing a digital world for online education, remote healthcare, immersive business, intelligent transportation, and advanced manufacturing. The goal is ambitious, yet the methodologies and technologies to achieve the full vision of the Metaverse remain unclear. In this paper, we first introduce the three infrastructure pillars that lay the foundation of the Metaverse, i.e., human-computer interfaces, sensing and communication systems, and network architectures. Then, we depict the roadmap towards the Metaverse that consists of four stages with different applications. To support diverse applications in the Metaverse, we put forward a novel design methodology: task-oriented design, and further review the challenges and the potential solutions. In the case study, we develop a prototype to illustrate how to synchronize a real-world device and its digital model in the Metaverse by task-oriented design, where a deep reinforcement learning algorithm is adopted to minimize the required communication throughput by optimizing the sampling and prediction systems subject to a synchronization error constraint.
Task-Oriented Prediction and Communication Co-Design for Haptic Communications
Feb 21, 2023



Prediction has recently been considered as a promising approach to meet low-latency and high-reliability requirements in long-distance haptic communications. However, most of the existing methods did not take features of tasks and the relationship between prediction and communication into account. In this paper, we propose a task-oriented prediction and communication co-design framework, where the reliability of the system depends on prediction errors and packet losses in communications. The goal is to minimize the required radio resources subject to the low-latency and high-reliability requirements of various tasks. Specifically, we consider the just noticeable difference (JND) as a performance metric for the haptic communication system. We collect experiment data from a real-world teleoperation testbed and use time-series generative adversarial networks (TimeGAN) to generate a large amount of synthetic data. This allows us to obtain the relationship between the JND threshold, prediction horizon, and the overall reliability including communication reliability and prediction reliability. We take 5G New Radio as an example to demonstrate the proposed framework and optimize bandwidth allocation and data rates of devices. Our numerical and experimental results show that the proposed framework can reduce wireless resource consumption up to 77.80% compared with a task-agnostic benchmark.
A Scalable Graph Neural Network Decoder for Short Block Codes
Nov 13, 2022



In this work, we propose a novel decoding algorithm for short block codes based on an edge-weighted graph neural network (EW-GNN). The EW-GNN decoder operates on the Tanner graph with an iterative message-passing structure, which algorithmically aligns with the conventional belief propagation (BP) decoding method. In each iteration, the "weight" on the message passed along each edge is obtained from a fully connected neural network that has the reliability information from nodes/edges as its input. Compared to existing deep-learning-based decoding schemes, the EW-GNN decoder is characterised by its scalability, meaning that 1) the number of trainable parameters is independent of the codeword length, and 2) an EW-GNN decoder trained with shorter/simple codes can be directly used for longer/sophisticated codes of different code rates. Furthermore, simulation results show that the EW-GNN decoder outperforms the BP and deep-learning-based BP methods from the literature in terms of the decoding error rate.
Sampling, Communication, and Prediction Co-Design for Synchronizing the Real-World Device and Digital Model in Metaverse
Jul 31, 2022



The metaverse has the potential to revolutionize the next generation of the Internet by supporting highly interactive services with the help of Mixed Reality (MR) technologies; still, to provide a satisfactory experience for users, the synchronization between the physical world and its digital models is crucial. This work proposes a sampling, communication and prediction co-design framework to minimize the communication load subject to a constraint on tracking the Mean Squared Error (MSE) between a real-world device and its digital model in the metaverse. To optimize the sampling rate and the prediction horizon, we exploit expert knowledge and develop a constrained Deep Reinforcement Learning (DRL) algorithm, named Knowledge-assisted Constrained Twin-Delayed Deep Deterministic (KC-TD3) policy gradient algorithm. We validate our framework on a prototype composed of a real-world robotic arm and its digital model. Compared with existing approaches: (1) When the tracking error constraint is stringent (MSE=0.002 degrees), our policy degenerates into the policy in the sampling-communication co-design framework. (2) When the tracking error constraint is mild (MSE=0.007 degrees), our policy degenerates into the policy in the prediction-communication co-design framework. (3) Our framework achieves a better trade-off between the average MSE and the average communication load compared with a communication system without sampling and prediction. For example, the average communication load can be reduced up to 87% when the track error constraint is 0.002 degrees. (4) Our policy outperforms the benchmark with the static sampling rate and prediction horizon optimized by exhaustive search, in terms of the tail probability of the tracking error. Furthermore, with the assistance of expert knowledge, the proposed algorithm KC-TD3 achieves better convergence time, stability, and final policy performance.
Interference-Limited Ultra-Reliable and Low-Latency Communications: Graph Neural Networks or Stochastic Geometry?
Jul 19, 2022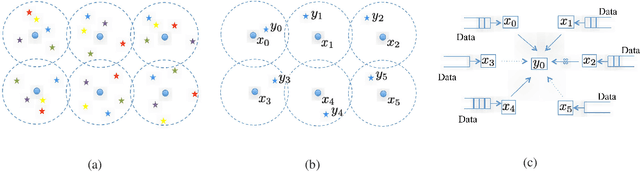
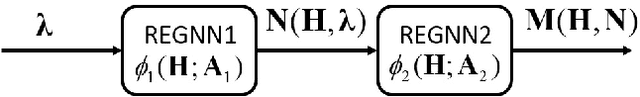
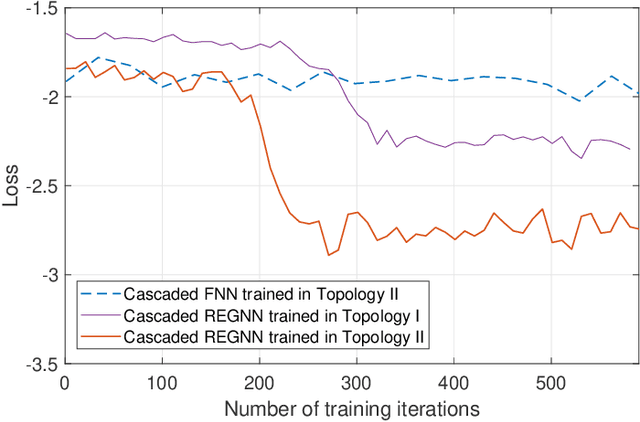
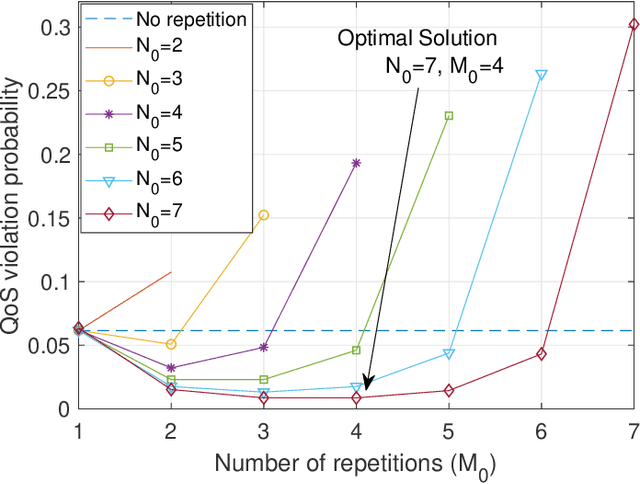
In this paper, we aim to improve the Quality-of-Service (QoS) of Ultra-Reliability and Low-Latency Communications (URLLC) in interference-limited wireless networks. To obtain time diversity within the channel coherence time, we first put forward a random repetition scheme that randomizes the interference power. Then, we optimize the number of reserved slots and the number of repetitions for each packet to minimize the QoS violation probability, defined as the percentage of users that cannot achieve URLLC. We build a cascaded Random Edge Graph Neural Network (REGNN) to represent the repetition scheme and develop a model-free unsupervised learning method to train it. We analyze the QoS violation probability using stochastic geometry in a symmetric scenario and apply a model-based Exhaustive Search (ES) method to find the optimal solution. Simulation results show that in the symmetric scenario, the QoS violation probabilities achieved by the model-free learning method and the model-based ES method are nearly the same. In more general scenarios, the cascaded REGNN generalizes very well in wireless networks with different scales, network topologies, cell densities, and frequency reuse factors. It outperforms the model-based ES method in the presence of the model mismatch.
Distributed Graph Neural Networks for Optimizing Wireless Networks: Message Passing Over-the-Air
Jul 18, 2022



Distributed power allocation is important for interference-limited wireless networks with dense transceiver pairs. In this paper, we aim to design low signaling overhead distributed power allocation schemes by using graph neural networks (GNNs), which are scalable to the number of wireless links. We first apply the message passing neural network (MPNN), a unified framework of GNN, to solve the problem. We show that the signaling overhead grows quadratically as the network size increases. Inspired from the over-the-air computation (AirComp), we then propose an Air-MPNN framework, where the messages from neighboring nodes are represented by the transmit power of pilots and can be aggregated efficiently by evaluating the total interference power. The signaling overhead of Air-MPNN grows linearly as the network size increases, and we prove that Air-MPNN is permutation invariant. To further reduce the signaling overhead, we propose the Air message passing recurrent neural network (Air-MPRNN), where each node utilizes the graph embedding and local state in the previous frame to update the graph embedding in the current frame. Since existing communication systems send a pilot during each frame, Air-MPRNN can be integrated into the existing standards by adjusting pilot power. Simulation results validate the scalability of the proposed frameworks, and show that they outperform the existing power allocation algorithms in terms of sum-rate for various system parameters.