 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChao Ban
ProTA: Probabilistic Token Aggregation for Text-Video Retrieval
Apr 18, 2024
Text-video retrieval aims to find the most relevant cross-modal samples for a given query. Recent methods focus on modeling the whole spatial-temporal relations. However, since video clips contain more diverse content than captions, the model aligning these asymmetric video-text pairs has a high risk of retrieving many false positive results. In this paper, we propose Probabilistic Token Aggregation (\textit{ProTA}) to handle cross-modal interaction with content asymmetry. Specifically, we propose dual partial-related aggregation to disentangle and re-aggregate token representations in both low-dimension and high-dimension spaces. We propose token-based probabilistic alignment to generate token-level probabilistic representation and maintain the feature representation diversity. In addition, an adaptive contrastive loss is proposed to learn compact cross-modal distribution space. Based on extensive experiments, \textit{ProTA} achieves significant improvements on MSR-VTT (50.9%), LSMDC (25.8%), and DiDeMo (47.2%).
Mask to reconstruct: Cooperative Semantics Completion for Video-text Retrieval
May 13, 2023



Recently, masked video modeling has been widely explored and significantly improved the model's understanding ability of visual regions at a local level. However, existing methods usually adopt random masking and follow the same reconstruction paradigm to complete the masked regions, which do not leverage the correlations between cross-modal content. In this paper, we present Mask for Semantics Completion (MASCOT) based on semantic-based masked modeling. Specifically, after applying attention-based video masking to generate high-informed and low-informed masks, we propose Informed Semantics Completion to recover masked semantics information. The recovery mechanism is achieved by aligning the masked content with the unmasked visual regions and corresponding textual context, which makes the model capture more text-related details at a patch level. Additionally, we shift the emphasis of reconstruction from irrelevant backgrounds to discriminative parts to ignore regions with low-informed masks. Furthermore, we design dual-mask co-learning to incorporate video cues under different masks and learn more aligned video representation. Our MASCOT performs state-of-the-art performance on four major text-video retrieval benchmarks, including MSR-VTT, LSMDC, ActivityNet, and DiDeMo. Extensive ablation studies demonstrate the effectiveness of the proposed schemes.
Multi-Granularity Network with Modal Attention for Dense Affective Understanding
Jun 18, 2021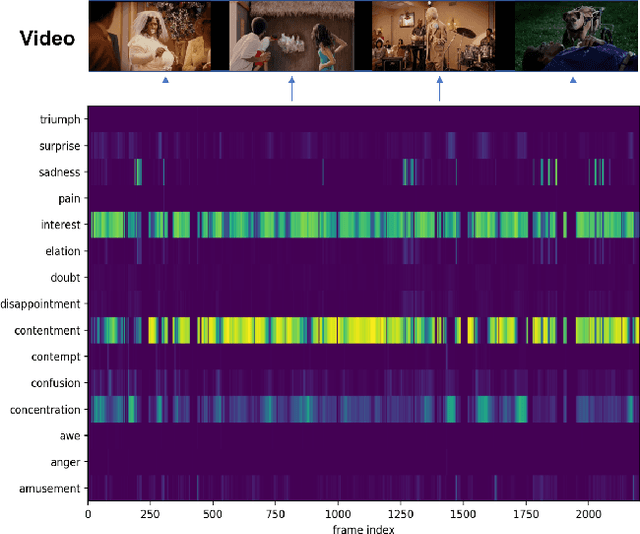

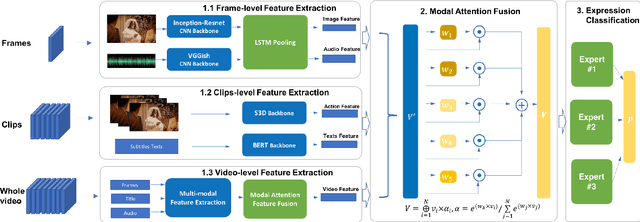
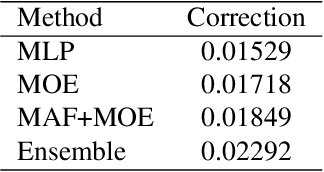
Video affective understanding, which aims to predict the evoked expressions by the video content, is desired for video creation and recommendation. In the recent EEV challenge, a dense affective understanding task is proposed and requires frame-level affective prediction. In this paper, we propose a multi-granularity network with modal attention (MGN-MA), which employs multi-granularity features for better description of the target frame. Specifically, the multi-granularity features could be divided into frame-level, clips-level and video-level features, which corresponds to visual-salient content, semantic-context and video theme information. Then the modal attention fusion module is designed to fuse the multi-granularity features and emphasize more affection-relevant modals. Finally, the fused feature is fed into a Mixtures Of Experts (MOE) classifier to predict the expressions. Further employing model-ensemble post-processing, the proposed method achieves the correlation score of 0.02292 in the EEV challenge.