 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChao Ni
Exploring ChatGPT's Ability to Rank Content: A Preliminary Study on Consistency with Human Preferences
Mar 14, 2023
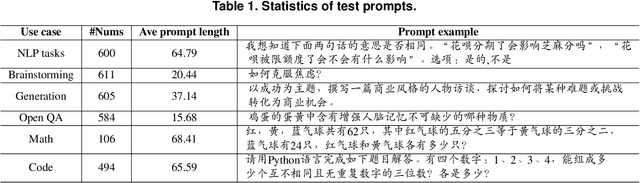
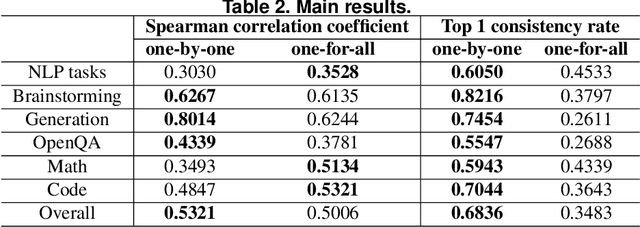
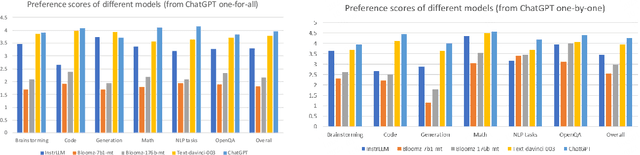
As a natural language assistant, ChatGPT is capable of performing various tasks, including but not limited to article generation, code completion, and data analysis. Furthermore, ChatGPT has consistently demonstrated a remarkable level of accuracy and reliability in terms of content evaluation, exhibiting the capability of mimicking human preferences. To further explore ChatGPT's potential in this regard, a study is conducted to assess its ability to rank content. In order to do so, a test set consisting of prompts is created, covering a wide range of use cases, and five models are utilized to generate corresponding responses. ChatGPT is then instructed to rank the responses generated by these models. The results on the test set show that ChatGPT's ranking preferences are consistent with human to a certain extent. This preliminary experimental finding implies that ChatGPT's zero-shot ranking capability could be used to reduce annotation pressure in a number of ranking tasks.
Fast and Compute-efficient Sampling-based Local Exploration Planning via Distribution Learning
Feb 28, 2022
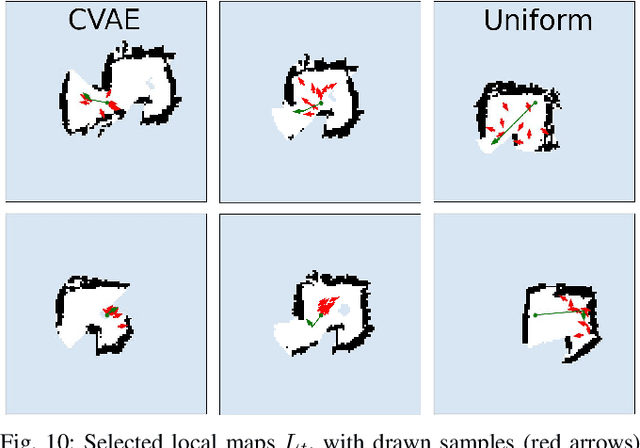
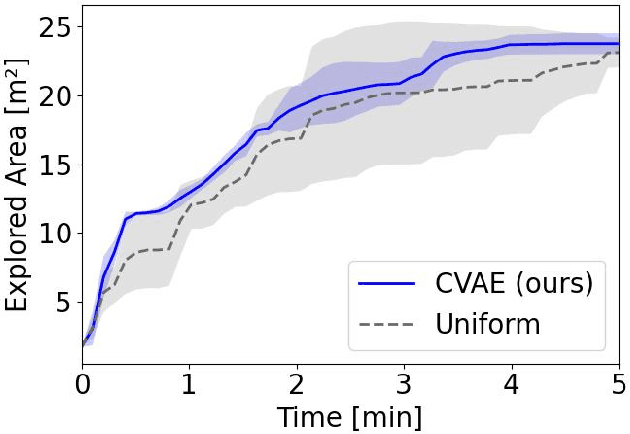
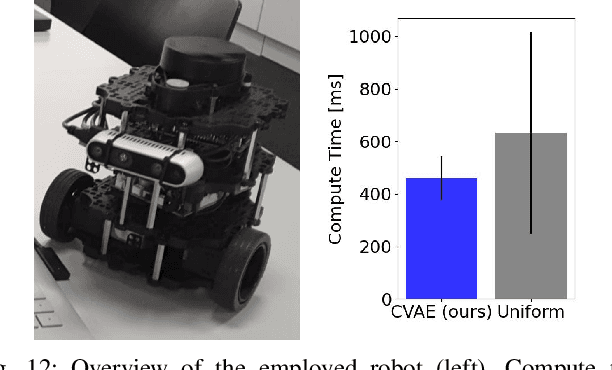
Exploration is a fundamental problem in robotics. While sampling-based planners have shown high performance, they are oftentimes compute intensive and can exhibit high variance. To this end, we propose to directly learn the underlying distribution of informative views based on the spatial context in the robot's map. We further explore a variety of methods to also learn the information gain. We show in thorough experimental evaluation that our proposed system improves exploration performance by up to 28\% over classical methods, and find that learning the gains in addition to the sampling distribution can provide favorable performance vs. compute trade-offs for compute-constrained systems. We demonstrate in simulation and on a low-cost mobile robot that our system generalizes well to varying environments.