 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCharlotte M. Deane
Large scale paired antibody language models
Mar 26, 2024




Antibodies are proteins produced by the immune system that can identify and neutralise a wide variety of antigens with high specificity and affinity, and constitute the most successful class of biotherapeutics. With the advent of next-generation sequencing, billions of antibody sequences have been collected in recent years, though their application in the design of better therapeutics has been constrained by the sheer volume and complexity of the data. To address this challenge, we present IgBert and IgT5, the best performing antibody-specific language models developed to date which can consistently handle both paired and unpaired variable region sequences as input. These models are trained comprehensively using the more than two billion unpaired sequences and two million paired sequences of light and heavy chains present in the Observed Antibody Space dataset. We show that our models outperform existing antibody and protein language models on a diverse range of design and regression tasks relevant to antibody engineering. This advancement marks a significant leap forward in leveraging machine learning, large scale data sets and high-performance computing for enhancing antibody design for therapeutic development.
Inverse folding for antibody sequence design using deep learning
Oct 30, 2023We consider the problem of antibody sequence design given 3D structural information. Building on previous work, we propose a fine-tuned inverse folding model that is specifically optimised for antibody structures and outperforms generic protein models on sequence recovery and structure robustness when applied on antibodies, with notable improvement on the hypervariable CDR-H3 loop. We study the canonical conformations of complementarity-determining regions and find improved encoding of these loops into known clusters. Finally, we consider the applications of our model to drug discovery and binder design and evaluate the quality of proposed sequences using physics-based methods.
Ranking of Communities in Multiplex Spatiotemporal Models of Brain Dynamics
Mar 17, 2022



As a relatively new field, network neuroscience has tended to focus on aggregate behaviours of the brain averaged over many successive experiments or over long recordings in order to construct robust brain models. These models are limited in their ability to explain dynamic state changes in the brain which occurs spontaneously as a result of normal brain function. Hidden Markov Models (HMMs) trained on neuroimaging time series data have since arisen as a method to produce dynamical models that are easy to train but can be difficult to fully parametrise or analyse. We propose an interpretation of these neural HMMs as multiplex brain state graph models we term Hidden Markov Graph Models (HMGMs). This interpretation allows for dynamic brain activity to be analysed using the full repertoire of network analysis techniques. Furthermore, we propose a general method for selecting HMM hyperparameters in the absence of external data, based on the principle of maximum entropy, and use this to select the number of layers in the multiplex model. We produce a new tool for determining important communities of brain regions using a spatiotemporal random walk-based procedure that takes advantage of the underlying Markov structure of the model. Our analysis of real multi-subject fMRI data provides new results that corroborate the modular processing hypothesis of the brain at rest as well as contributing new evidence of functional overlap between and within dynamic brain state communities. Our analysis pipeline provides a way to characterise dynamic network activity of the brain under novel behaviours or conditions.
* Part of the Special Issue on Community Structure in Networks 2021 (35 Pages, first 22 for main text)
The prospects of quantum computing in computational molecular biology
May 26, 2020

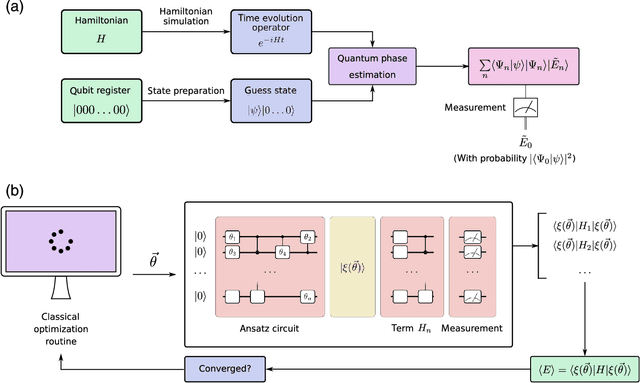

Quantum computers can in principle solve certain problems exponentially more quickly than their classical counterparts. We have not yet reached the advent of useful quantum computation, but when we do, it will affect nearly all scientific disciplines. In this review, we examine how current quantum algorithms could revolutionize computational biology and bioinformatics. There are potential benefits across the entire field, from the ability to process vast amounts of information and run machine learning algorithms far more efficiently, to algorithms for quantum simulation that are poised to improve computational calculations in drug discovery, to quantum algorithms for optimization that may advance fields from protein structure prediction to network analysis. However, these exciting prospects are susceptible to "hype", and it is also important to recognize the caveats and challenges in this new technology. Our aim is to introduce the promise and limitations of emerging quantum computing technologies in the areas of computational molecular biology and bioinformatics.
* 23 pages, 3 figures
Identifying networks with common organizational principles
Apr 02, 2017



Many complex systems can be represented as networks, and the problem of network comparison is becoming increasingly relevant. There are many techniques for network comparison, from simply comparing network summary statistics to sophisticated but computationally costly alignment-based approaches. Yet it remains challenging to accurately cluster networks that are of a different size and density, but hypothesized to be structurally similar. In this paper, we address this problem by introducing a new network comparison methodology that is aimed at identifying common organizational principles in networks. The methodology is simple, intuitive and applicable in a wide variety of settings ranging from the functional classification of proteins to tracking the evolution of a world trade network.