 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChen Wei
CoCoG: Controllable Visual Stimuli Generation based on Human Concept Representations
Apr 25, 2024
A central question for cognitive science is to understand how humans process visual objects, i.e, to uncover human low-dimensional concept representation space from high-dimensional visual stimuli. Generating visual stimuli with controlling concepts is the key. However, there are currently no generative models in AI to solve this problem. Here, we present the Concept based Controllable Generation (CoCoG) framework. CoCoG consists of two components, a simple yet efficient AI agent for extracting interpretable concept and predicting human decision-making in visual similarity judgment tasks, and a conditional generation model for generating visual stimuli given the concepts. We quantify the performance of CoCoG from two aspects, the human behavior prediction accuracy and the controllable generation ability. The experiments with CoCoG indicate that 1) the reliable concept embeddings in CoCoG allows to predict human behavior with 64.07\% accuracy in the THINGS-similarity dataset; 2) CoCoG can generate diverse objects through the control of concepts; 3) CoCoG can manipulate human similarity judgment behavior by intervening key concepts. CoCoG offers visual objects with controlling concepts to advance our understanding of causality in human cognition. The code of CoCoG is available at \url{https://github.com/ncclab-sustech/CoCoG}.
AiOS: All-in-One-Stage Expressive Human Pose and Shape Estimation
Mar 26, 2024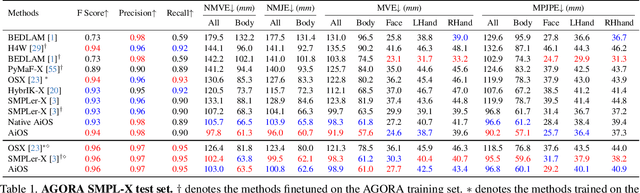
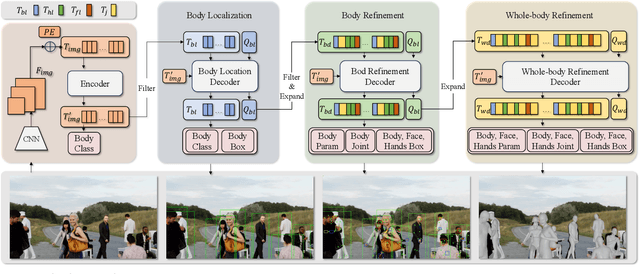

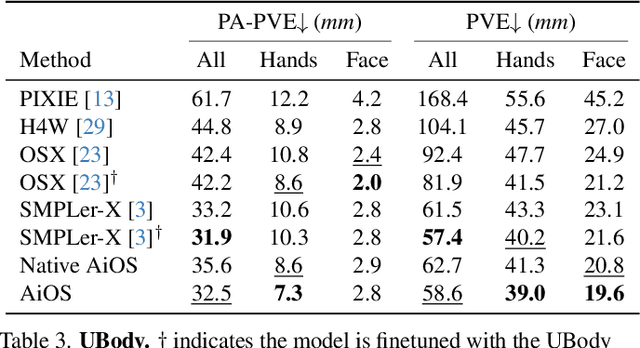
Expressive human pose and shape estimation (a.k.a. 3D whole-body mesh recovery) involves the human body, hand, and expression estimation. Most existing methods have tackled this task in a two-stage manner, first detecting the human body part with an off-the-shelf detection model and inferring the different human body parts individually. Despite the impressive results achieved, these methods suffer from 1) loss of valuable contextual information via cropping, 2) introducing distractions, and 3) lacking inter-association among different persons and body parts, inevitably causing performance degradation, especially for crowded scenes. To address these issues, we introduce a novel all-in-one-stage framework, AiOS, for multiple expressive human pose and shape recovery without an additional human detection step. Specifically, our method is built upon DETR, which treats multi-person whole-body mesh recovery task as a progressive set prediction problem with various sequential detection. We devise the decoder tokens and extend them to our task. Specifically, we first employ a human token to probe a human location in the image and encode global features for each instance, which provides a coarse location for the later transformer block. Then, we introduce a joint-related token to probe the human joint in the image and encoder a fine-grained local feature, which collaborates with the global feature to regress the whole-body mesh. This straightforward but effective model outperforms previous state-of-the-art methods by a 9% reduction in NMVE on AGORA, a 30% reduction in PVE on EHF, a 10% reduction in PVE on ARCTIC, and a 3% reduction in PVE on EgoBody.
WHAC: World-grounded Humans and Cameras
Mar 19, 2024
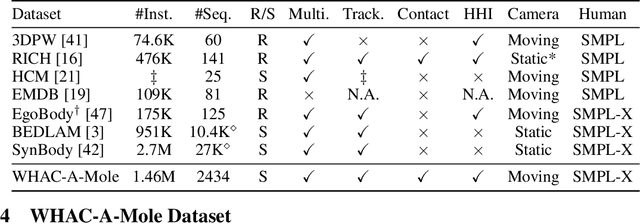
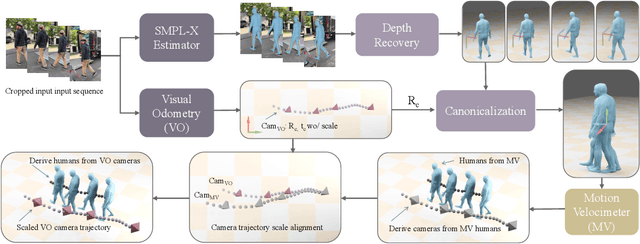

Estimating human and camera trajectories with accurate scale in the world coordinate system from a monocular video is a highly desirable yet challenging and ill-posed problem. In this study, we aim to recover expressive parametric human models (i.e., SMPL-X) and corresponding camera poses jointly, by leveraging the synergy between three critical players: the world, the human, and the camera. Our approach is founded on two key observations. Firstly, camera-frame SMPL-X estimation methods readily recover absolute human depth. Secondly, human motions inherently provide absolute spatial cues. By integrating these insights, we introduce a novel framework, referred to as WHAC, to facilitate world-grounded expressive human pose and shape estimation (EHPS) alongside camera pose estimation, without relying on traditional optimization techniques. Additionally, we present a new synthetic dataset, WHAC-A-Mole, which includes accurately annotated humans and cameras, and features diverse interactive human motions as well as realistic camera trajectories. Extensive experiments on both standard and newly established benchmarks highlight the superiority and efficacy of our framework. We will make the code and dataset publicly available.
Visual Decoding and Reconstruction via EEG Embeddings with Guided Diffusion
Mar 14, 2024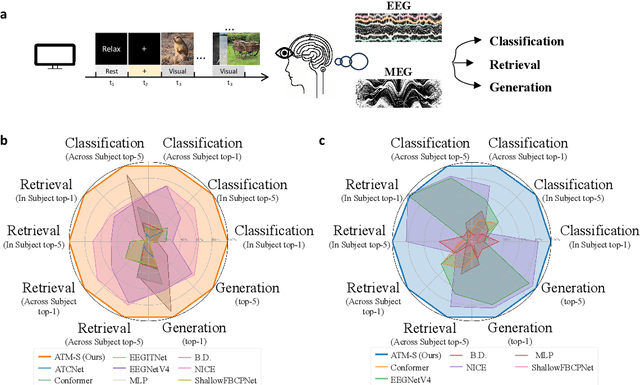


How to decode human vision through neural signals has attracted a long-standing interest in neuroscience and machine learning. Modern contrastive learning and generative models improved the performance of fMRI-based visual decoding and reconstruction. However, the high cost and low temporal resolution of fMRI limit their applications in brain-computer interfaces (BCIs), prompting a high need for EEG-based visual reconstruction. In this study, we present an EEG-based visual reconstruction framework. It consists of a plug-and-play EEG encoder called the Adaptive Thinking Mapper (ATM), which is aligned with image embeddings, and a two-stage EEG guidance image generator that first transforms EEG features into image priors and then reconstructs the visual stimuli with a pre-trained image generator. Our approach allows EEG embeddings to achieve superior performance in image classification and retrieval tasks. Our two-stage image generation strategy vividly reconstructs images seen by humans. Furthermore, we analyzed the impact of signals from different time windows and brain regions on decoding and reconstruction. The versatility of our framework is demonstrated in the magnetoencephalogram (MEG) data modality. We report that EEG-based visual decoding achieves SOTA performance, highlighting the portability, low cost, and high temporal resolution of EEG, enabling a wide range of BCI applications. The code of ATM is available at https://github.com/dongyangli-del/EEG_Image_decode.
Towards Generalizable Tumor Synthesis
Feb 29, 2024Tumor synthesis enables the creation of artificial tumors in medical images, facilitating the training of AI models for tumor detection and segmentation. However, success in tumor synthesis hinges on creating visually realistic tumors that are generalizable across multiple organs and, furthermore, the resulting AI models being capable of detecting real tumors in images sourced from different domains (e.g., hospitals). This paper made a progressive stride toward generalizable tumor synthesis by leveraging a critical observation: early-stage tumors (< 2cm) tend to have similar imaging characteristics in computed tomography (CT), whether they originate in the liver, pancreas, or kidneys. We have ascertained that generative AI models, e.g., Diffusion Models, can create realistic tumors generalized to a range of organs even when trained on a limited number of tumor examples from only one organ. Moreover, we have shown that AI models trained on these synthetic tumors can be generalized to detect and segment real tumors from CT volumes, encompassing a broad spectrum of patient demographics, imaging protocols, and healthcare facilities.
Both Matter: Enhancing the Emotional Intelligence of Large Language Models without Compromising the General Intelligence
Feb 15, 2024Emotional Intelligence (EI), consisting of emotion perception, emotion cognition and emotion expression, plays the critical roles in improving user interaction experience for the current large language model (LLM) based conversational general AI assistants. Previous works mainly focus on raising the emotion perception ability of them via naive fine-tuning on EI-related classification or regression tasks. However, this leads to the incomplete enhancement of EI and catastrophic forgetting of the general intelligence (GI). To this end, we first introduce \textsc{EiBench}, a large-scale collection of EI-related tasks in the text-to-text formation with task instructions that covers all three aspects of EI, which lays a solid foundation for the comprehensive EI enhancement of LLMs. Then a novel \underline{\textbf{Mo}}dular \underline{\textbf{E}}motional \underline{\textbf{I}}ntelligence enhancement method (\textbf{MoEI}), consisting of Modular Parameter Expansion and intra-inter modulation, is proposed to comprehensively enhance the EI of LLMs without compromise their GI. Extensive experiments on two representative LLM-based assistants, Flan-T5 and LLaMA-2-Chat, demonstrate the effectiveness of MoEI to improving EI while maintain GI.
Integration of cognitive tasks into artificial general intelligence test for large models
Feb 04, 2024During the evolution of large models, performance evaluation is necessarily performed on the intermediate models to assess their capabilities, and on the well-trained model to ensure safety before practical application. However, current model evaluations mainly rely on specific tasks and datasets, lacking a united framework for assessing the multidimensional intelligence of large models. In this perspective, we advocate for a comprehensive framework of artificial general intelligence (AGI) test, aimed at fulfilling the testing needs of large language models and multi-modal large models with enhanced capabilities. The AGI test framework bridges cognitive science and natural language processing to encompass the full spectrum of intelligence facets, including crystallized intelligence, a reflection of amassed knowledge and experience; fluid intelligence, characterized by problem-solving and adaptive reasoning; social intelligence, signifying comprehension and adaptation within multifaceted social scenarios; and embodied intelligence, denoting the ability to interact with its physical environment. To assess the multidimensional intelligence of large models, the AGI test consists of a battery of well-designed cognitive tests adopted from human intelligence tests, and then naturally encapsulates into an immersive virtual community. We propose that the complexity of AGI testing tasks should increase commensurate with the advancements in large models. We underscore the necessity for the interpretation of test results to avoid false negatives and false positives. We believe that cognitive science-inspired AGI tests will effectively guide the targeted improvement of large models in specific dimensions of intelligence and accelerate the integration of large models into human society.
Advancing EEG/MEG Source Imaging with Geometric-Informed Basis Functions
Jan 31, 2024Electroencephalography (EEG) and Magnetoencephalography (MEG) are pivotal in understanding brain activity but are limited by their poor spatial resolution. EEG/MEG source imaging (ESI) infers the high-resolution electric field distribution in the brain based on the low-resolution scalp EEG/MEG observations. However, the ESI problem is ill-posed, and how to bring neuroscience priors into ESI method is the key. Here, we present a novel method which utilizes the Brain Geometric-informed Basis Functions (GBFs) as priors to enhance EEG/MEG source imaging. Through comprehensive experiments on both synthetic data and real task EEG data, we demonstrate the superiority of GBFs over traditional spatial basis functions (e.g., Harmonic and MSP), as well as existing ESI methods (e.g., dSPM, MNE, sLORETA, eLORETA). GBFs provide robust ESI results under different noise levels, and result in biologically interpretable EEG sources. We believe the high-resolution EEG source imaging from GBFs will greatly advance neuroscience research.
Tuning LayerNorm in Attention: Towards Efficient Multi-Modal LLM Finetuning
Dec 18, 2023This paper introduces an efficient strategy to transform Large Language Models (LLMs) into Multi-Modal Large Language Models (MLLMs). By conceptualizing this transformation as a domain adaptation process, i.e., transitioning from text understanding to embracing multiple modalities, we intriguingly note that, within each attention block, tuning LayerNorm suffices to yield strong performance. Moreover, when benchmarked against other tuning approaches like full parameter finetuning or LoRA, its benefits on efficiency are substantial. For example, when compared to LoRA on a 13B model scale, performance can be enhanced by an average of over 20% across five multi-modal tasks, and meanwhile, results in a significant reduction of trainable parameters by 41.9% and a decrease in GPU memory usage by 17.6%. On top of this LayerNorm strategy, we showcase that selectively tuning only with conversational data can improve efficiency further. Beyond these empirical outcomes, we provide a comprehensive analysis to explore the role of LayerNorm in adapting LLMs to the multi-modal domain and improving the expressive power of the model.
Digital Life Project: Autonomous 3D Characters with Social Intelligence
Dec 07, 2023
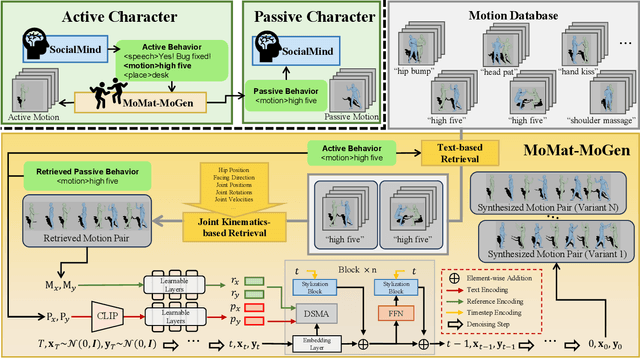
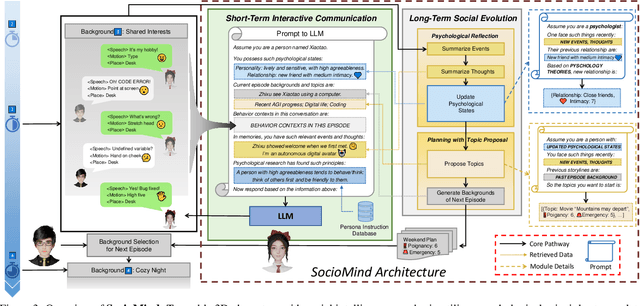
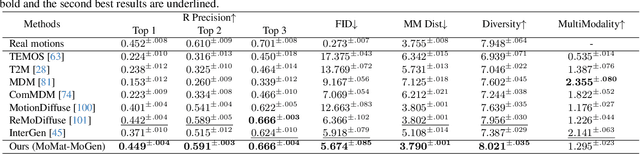
In this work, we present Digital Life Project, a framework utilizing language as the universal medium to build autonomous 3D characters, who are capable of engaging in social interactions and expressing with articulated body motions, thereby simulating life in a digital environment. Our framework comprises two primary components: 1) SocioMind: a meticulously crafted digital brain that models personalities with systematic few-shot exemplars, incorporates a reflection process based on psychology principles, and emulates autonomy by initiating dialogue topics; 2) MoMat-MoGen: a text-driven motion synthesis paradigm for controlling the character's digital body. It integrates motion matching, a proven industry technique to ensure motion quality, with cutting-edge advancements in motion generation for diversity. Extensive experiments demonstrate that each module achieves state-of-the-art performance in its respective domain. Collectively, they enable virtual characters to initiate and sustain dialogues autonomously, while evolving their socio-psychological states. Concurrently, these characters can perform contextually relevant bodily movements. Additionally, a motion captioning module further allows the virtual character to recognize and appropriately respond to human players' actions. Homepage: https://digital-life-project.com/