 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChen Yan
SafeGen: Mitigating Unsafe Content Generation in Text-to-Image Models
Apr 10, 2024
Text-to-image (T2I) models, such as Stable Diffusion, have exhibited remarkable performance in generating high-quality images from text descriptions in recent years. However, text-to-image models may be tricked into generating not-safe-for-work (NSFW) content, particularly in sexual scenarios. Existing countermeasures mostly focus on filtering inappropriate inputs and outputs, or suppressing improper text embeddings, which can block explicit NSFW-related content (e.g., naked or sexy) but may still be vulnerable to adversarial prompts inputs that appear innocent but are ill-intended. In this paper, we present SafeGen, a framework to mitigate unsafe content generation by text-to-image models in a text-agnostic manner. The key idea is to eliminate unsafe visual representations from the model regardless of the text input. In this way, the text-to-image model is resistant to adversarial prompts since unsafe visual representations are obstructed from within. Extensive experiments conducted on four datasets demonstrate SafeGen's effectiveness in mitigating unsafe content generation while preserving the high-fidelity of benign images. SafeGen outperforms eight state-of-the-art baseline methods and achieves 99.1% sexual content removal performance. Furthermore, our constructed benchmark of adversarial prompts provides a basis for future development and evaluation of anti-NSFW-generation methods.
Inaudible Adversarial Perturbation: Manipulating the Recognition of User Speech in Real Time
Aug 03, 2023



Automatic speech recognition (ASR) systems have been shown to be vulnerable to adversarial examples (AEs). Recent success all assumes that users will not notice or disrupt the attack process despite the existence of music/noise-like sounds and spontaneous responses from voice assistants. Nonetheless, in practical user-present scenarios, user awareness may nullify existing attack attempts that launch unexpected sounds or ASR usage. In this paper, we seek to bridge the gap in existing research and extend the attack to user-present scenarios. We propose VRIFLE, an inaudible adversarial perturbation (IAP) attack via ultrasound delivery that can manipulate ASRs as a user speaks. The inherent differences between audible sounds and ultrasounds make IAP delivery face unprecedented challenges such as distortion, noise, and instability. In this regard, we design a novel ultrasonic transformation model to enhance the crafted perturbation to be physically effective and even survive long-distance delivery. We further enable VRIFLE's robustness by adopting a series of augmentation on user and real-world variations during the generation process. In this way, VRIFLE features an effective real-time manipulation of the ASR output from different distances and under any speech of users, with an alter-and-mute strategy that suppresses the impact of user disruption. Our extensive experiments in both digital and physical worlds verify VRIFLE's effectiveness under various configurations, robustness against six kinds of defenses, and universality in a targeted manner. We also show that VRIFLE can be delivered with a portable attack device and even everyday-life loudspeakers.
Enrollment-stage Backdoor Attacks on Speaker Recognition Systems via Adversarial Ultrasound
Jun 28, 2023



Automatic Speaker Recognition Systems (SRSs) have been widely used in voice applications for personal identification and access control. A typical SRS consists of three stages, i.e., training, enrollment, and recognition. Previous work has revealed that SRSs can be bypassed by backdoor attacks at the training stage or by adversarial example attacks at the recognition stage. In this paper, we propose TUNER, a new type of backdoor attack against the enrollment stage of SRS via adversarial ultrasound modulation, which is inaudible, synchronization-free, content-independent, and black-box. Our key idea is to first inject the backdoor into the SRS with modulated ultrasound when a legitimate user initiates the enrollment, and afterward, the polluted SRS will grant access to both the legitimate user and the adversary with high confidence. Our attack faces a major challenge of unpredictable user articulation at the enrollment stage. To overcome this challenge, we generate the ultrasonic backdoor by augmenting the optimization process with random speech content, vocalizing time, and volume of the user. Furthermore, to achieve real-world robustness, we improve the ultrasonic signal over traditional methods using sparse frequency points, pre-compensation, and single-sideband (SSB) modulation. We extensively evaluate TUNER on two common datasets and seven representative SRS models. Results show that our attack can successfully bypass speaker recognition systems while remaining robust to various speakers, speech content, et
Improving Multimodal Interactive Agents with Reinforcement Learning from Human Feedback
Nov 21, 2022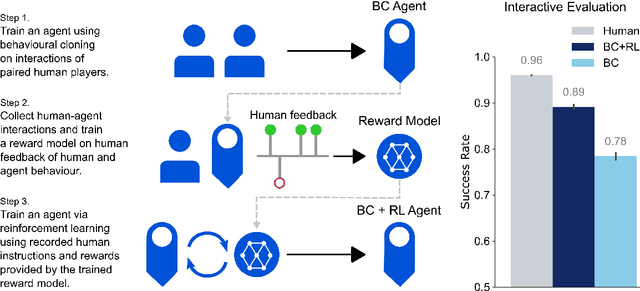
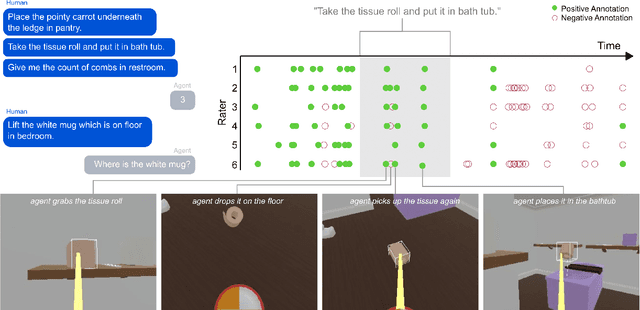
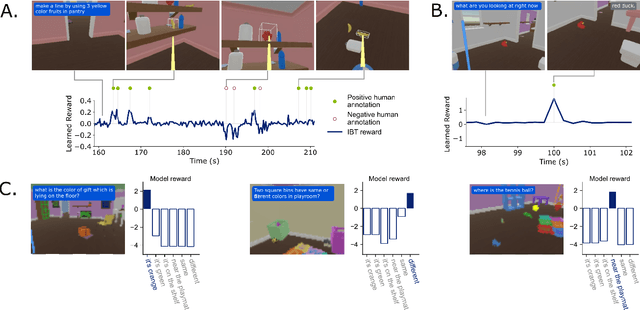
An important goal in artificial intelligence is to create agents that can both interact naturally with humans and learn from their feedback. Here we demonstrate how to use reinforcement learning from human feedback (RLHF) to improve upon simulated, embodied agents trained to a base level of competency with imitation learning. First, we collected data of humans interacting with agents in a simulated 3D world. We then asked annotators to record moments where they believed that agents either progressed toward or regressed from their human-instructed goal. Using this annotation data we leveraged a novel method - which we call "Inter-temporal Bradley-Terry" (IBT) modelling - to build a reward model that captures human judgments. Agents trained to optimise rewards delivered from IBT reward models improved with respect to all of our metrics, including subsequent human judgment during live interactions with agents. Altogether our results demonstrate how one can successfully leverage human judgments to improve agent behaviour, allowing us to use reinforcement learning in complex, embodied domains without programmatic reward functions. Videos of agent behaviour may be found at https://youtu.be/v_Z9F2_eKk4.
Intra-agent speech permits zero-shot task acquisition
Jun 07, 2022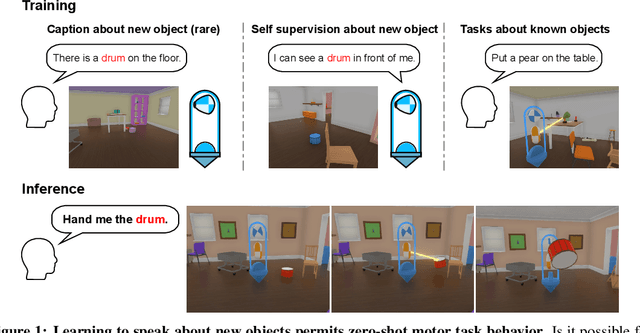
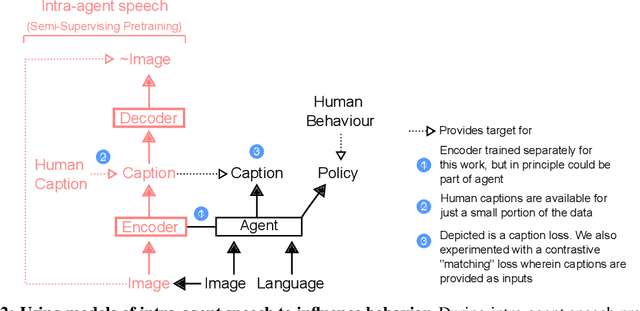

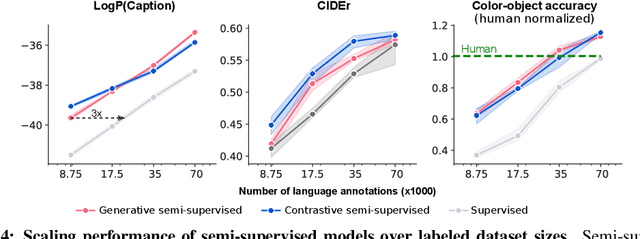
Human language learners are exposed to a trickle of informative, context-sensitive language, but a flood of raw sensory data. Through both social language use and internal processes of rehearsal and practice, language learners are able to build high-level, semantic representations that explain their perceptions. Here, we take inspiration from such processes of "inner speech" in humans (Vygotsky, 1934) to better understand the role of intra-agent speech in embodied behavior. First, we formally pose intra-agent speech as a semi-supervised problem and develop two algorithms that enable visually grounded captioning with little labeled language data. We then experimentally compute scaling curves over different amounts of labeled data and compare the data efficiency against a supervised learning baseline. Finally, we incorporate intra-agent speech into an embodied, mobile manipulator agent operating in a 3D virtual world, and show that with as few as 150 additional image captions, intra-agent speech endows the agent with the ability to manipulate and answer questions about a new object without any related task-directed experience (zero-shot). Taken together, our experiments suggest that modelling intra-agent speech is effective in enabling embodied agents to learn new tasks efficiently and without direct interaction experience.
Evaluating Multimodal Interactive Agents
May 26, 2022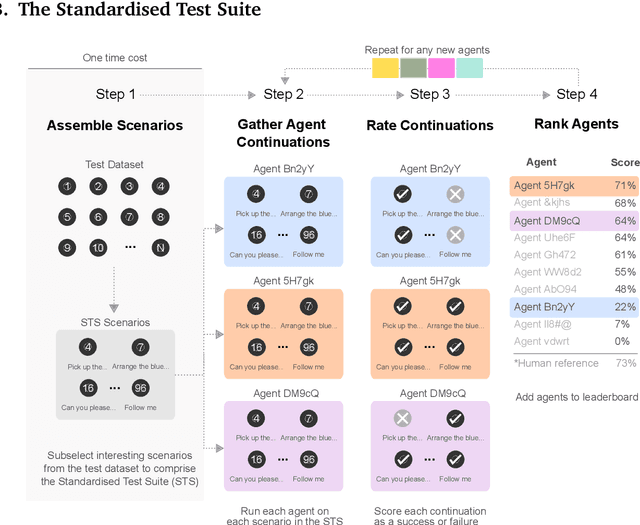
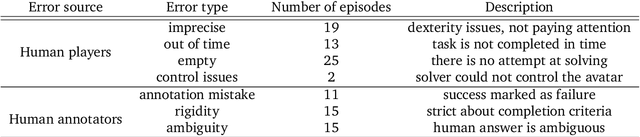
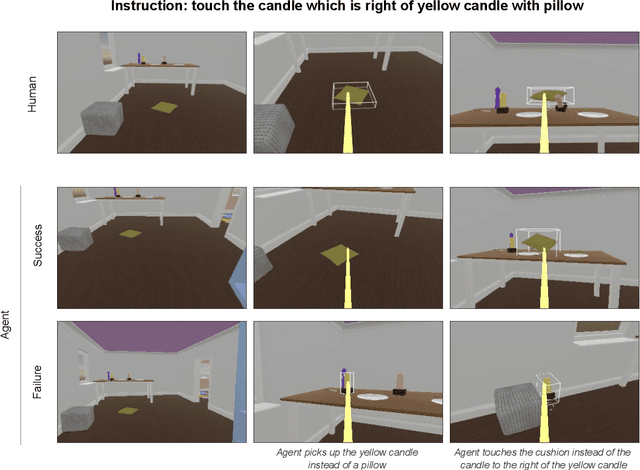
Creating agents that can interact naturally with humans is a common goal in artificial intelligence (AI) research. However, evaluating these interactions is challenging: collecting online human-agent interactions is slow and expensive, yet faster proxy metrics often do not correlate well with interactive evaluation. In this paper, we assess the merits of these existing evaluation metrics and present a novel approach to evaluation called the Standardised Test Suite (STS). The STS uses behavioural scenarios mined from real human interaction data. Agents see replayed scenario context, receive an instruction, and are then given control to complete the interaction offline. These agent continuations are recorded and sent to human annotators to mark as success or failure, and agents are ranked according to the proportion of continuations in which they succeed. The resulting STS is fast, controlled, interpretable, and representative of naturalistic interactions. Altogether, the STS consolidates much of what is desirable across many of our standard evaluation metrics, allowing us to accelerate research progress towards producing agents that can interact naturally with humans. https://youtu.be/YR1TngGORGQ
Private Eye: On the Limits of Textual Screen Peeking via Eyeglass Reflections in Video Conferencing
May 08, 2022



Personal video conferencing has become the new norm after COVID-19 caused a seismic shift from in-person meetings and phone calls to video conferencing for daily communications and sensitive business. Video leaks participants' on-screen information because eyeglasses and other reflective objects unwittingly expose partial screen contents. Using mathematical modeling and human subjects experiments, this research explores the extent to which emerging webcams might leak recognizable textual information gleamed from eyeglass reflections captured by webcams. The primary goal of our work is to measure, compute, and predict the factors, limits, and thresholds of recognizability as webcam technology evolves in the future. Our work explores and characterizes the viable threat models based on optical attacks using multi-frame super resolution techniques on sequences of video frames. Our experimental results and models show it is possible to reconstruct and recognize on-screen text with a height as small as 10 mm with a 720p webcam. We further apply this threat model to web textual content with varying attacker capabilities to find thresholds at which text becomes recognizable. Our user study with 20 participants suggests present-day 720p webcams are sufficient for adversaries to reconstruct textual content on big-font websites. Our models further show that the evolution toward 4K cameras will tip the threshold of text leakage to reconstruction of most header texts on popular websites. Our research proposes near-term mitigations, and justifies the importance of following the principle of least privilege for long-term defense against this attack. For privacy-sensitive scenarios, it's further recommended to develop technologies that blur all objects by default, then only unblur what is absolutely necessary to facilitate natural-looking conversations.
Rolling Colors: Adversarial Laser Exploits against Traffic Light Recognition
Apr 06, 2022



Traffic light recognition is essential for fully autonomous driving in urban areas. In this paper, we investigate the feasibility of fooling traffic light recognition mechanisms by shedding laser interference on the camera. By exploiting the rolling shutter of CMOS sensors, we manage to inject a color stripe overlapped on the traffic light in the image, which can cause a red light to be recognized as a green light or vice versa. To increase the success rate, we design an optimization method to search for effective laser parameters based on empirical models of laser interference. Our evaluation in emulated and real-world setups on 2 state-of-the-art recognition systems and 5 cameras reports a maximum success rate of 30% and 86.25% for Red-to-Green and Green-to-Red attacks. We observe that the attack is effective in continuous frames from more than 40 meters away against a moving vehicle, which may cause end-to-end impacts on self-driving such as running a red light or emergency stop. To mitigate the threat, we propose redesigning the rolling shutter mechanism.
Tell me why! -- Explanations support learning of relational and causal structure
Dec 08, 2021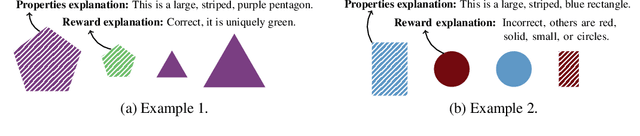
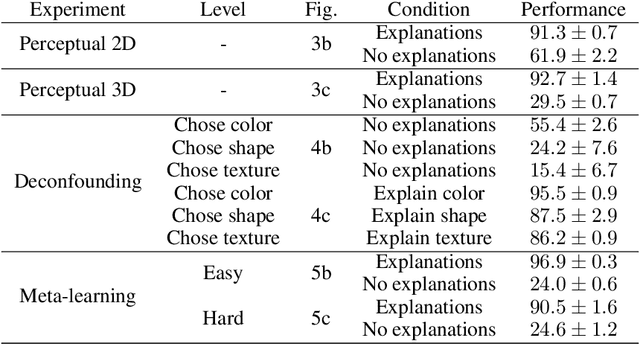
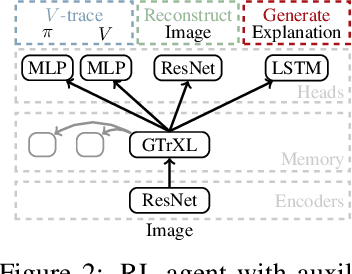
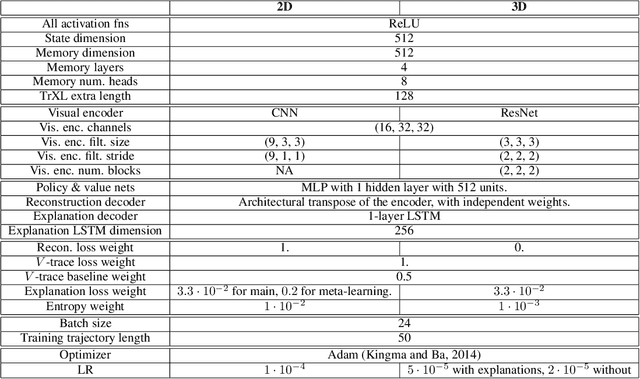
Explanations play a considerable role in human learning, especially in areas that remain major challenges for AI -- forming abstractions, and learning about the relational and causal structure of the world. Here, we explore whether reinforcement learning agents might likewise benefit from explanations. We outline a family of relational tasks that involve selecting an object that is the odd one out in a set (i.e., unique along one of many possible feature dimensions). Odd-one-out tasks require agents to reason over multi-dimensional relationships among a set of objects. We show that agents do not learn these tasks well from reward alone, but achieve >90% performance when they are also trained to generate language explaining object properties or why a choice is correct or incorrect. In further experiments, we show how predicting explanations enables agents to generalize appropriately from ambiguous, causally-confounded training, and even to meta-learn to perform experimental interventions to identify causal structure. We show that explanations help overcome the tendency of agents to fixate on simple features, and explore which aspects of explanations make them most beneficial. Our results suggest that learning from explanations is a powerful principle that could offer a promising path towards training more robust and general machine learning systems.
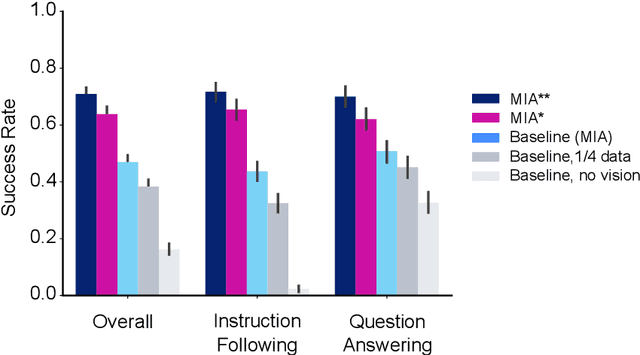
Creating Multimodal Interactive Agents with Imitation and Self-Supervised Learning
Dec 07, 2021
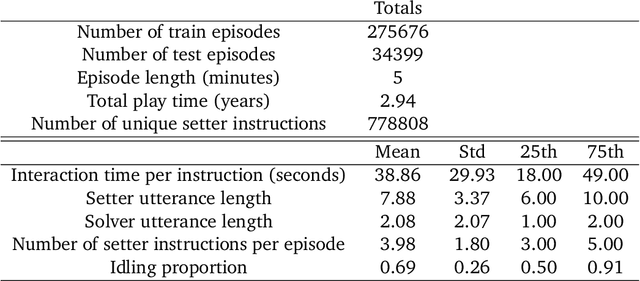
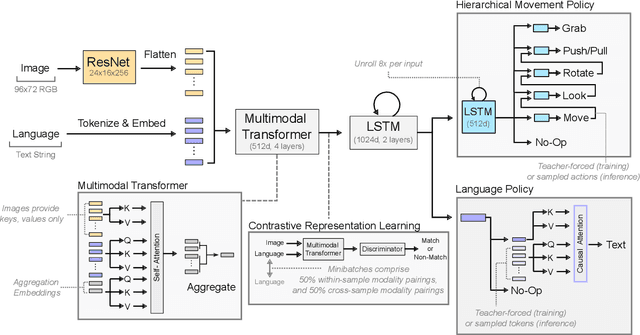
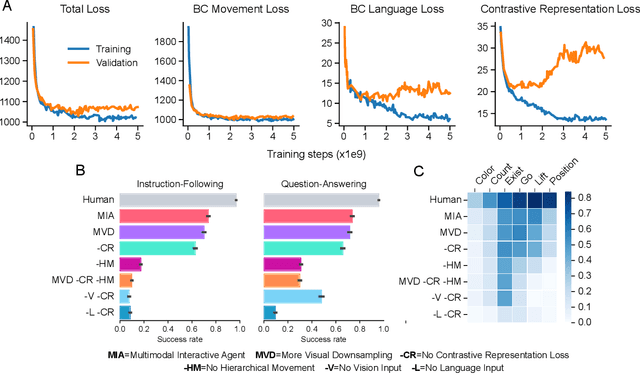
A common vision from science fiction is that robots will one day inhabit our physical spaces, sense the world as we do, assist our physical labours, and communicate with us through natural language. Here we study how to design artificial agents that can interact naturally with humans using the simplification of a virtual environment. We show that imitation learning of human-human interactions in a simulated world, in conjunction with self-supervised learning, is sufficient to produce a multimodal interactive agent, which we call MIA, that successfully interacts with non-adversarial humans 75% of the time. We further identify architectural and algorithmic techniques that improve performance, such as hierarchical action selection. Altogether, our results demonstrate that imitation of multi-modal, real-time human behaviour may provide a straightforward and surprisingly effective means of imbuing agents with a rich behavioural prior from which agents might then be fine-tuned for specific purposes, thus laying a foundation for training capable agents for interactive robots or digital assistants. A video of MIA's behaviour may be found at https://youtu.be/ZFgRhviF7mY