 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCheng Zeng
Analyze the Robustness of Classifiers under Label Noise
Dec 12, 2023
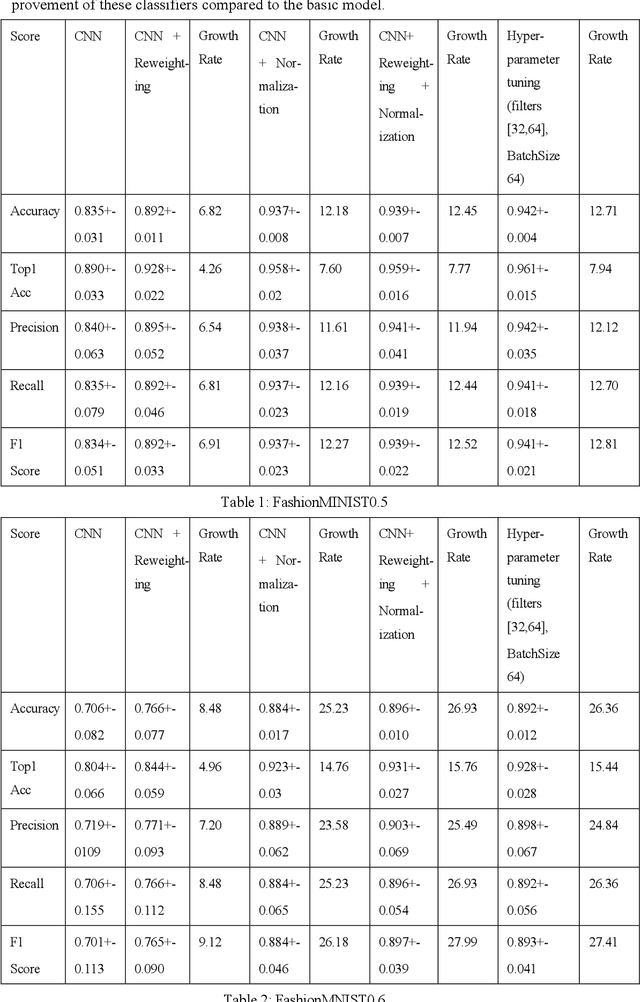

This study explores the robustness of label noise classifiers, aiming to enhance model resilience against noisy data in complex real-world scenarios. Label noise in supervised learning, characterized by erroneous or imprecise labels, significantly impairs model performance. This research focuses on the increasingly pertinent issue of label noise's impact on practical applications. Addressing the prevalent challenge of inaccurate training data labels, we integrate adversarial machine learning (AML) and importance reweighting techniques. Our approach involves employing convolutional neural networks (CNN) as the foundational model, with an emphasis on parameter adjustment for individual training samples. This strategy is designed to heighten the model's focus on samples critically influencing performance.
Analyze the robustness of three NMF algorithms (Robust NMF with L1 norm, L2-1 norm NMF, L2 NMF)
Dec 03, 2023Non-negative matrix factorization (NMF) and its variants have been widely employed in clustering and classification tasks (Long, & Jian , 2021). However, noises can seriously affect the results of our experiments. Our research is dedicated to investigating the noise robustness of non-negative matrix factorization (NMF) in the face of different types of noise. Specifically, we adopt three different NMF algorithms, namely L1 NMF, L2 NMF, and L21 NMF, and use the ORL and YaleB data sets to simulate a series of experiments with salt-and-pepper noise and Block-occlusion noise separately. In the experiment, we use a variety of evaluation indicators, including root mean square error (RMSE), accuracy (ACC), and normalized mutual information (NMI), to evaluate the performance of different NMF algorithms in noisy environments. Through these indicators, we quantify the resistance of NMF algorithms to noise and gain insights into their feasibility in practical applications.
Depth-NeuS: Neural Implicit Surfaces Learning for Multi-view Reconstruction Based on Depth Information Optimization
Mar 30, 2023
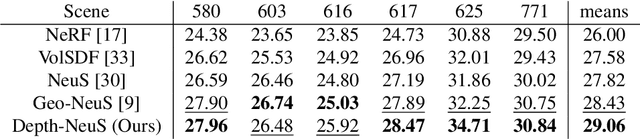
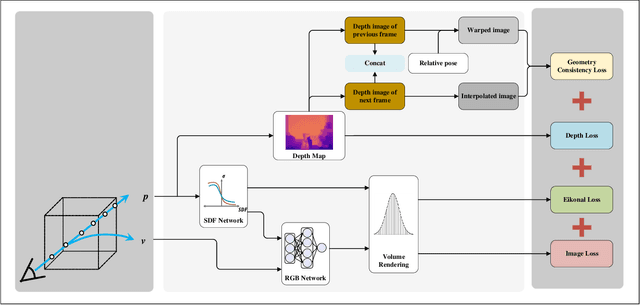
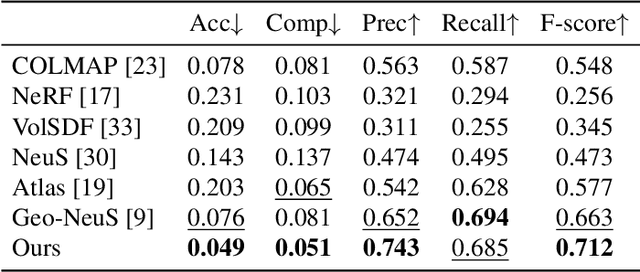
Recently, methods for neural surface representation and rendering, for example NeuS, have shown that learning neural implicit surfaces through volume rendering is becoming increasingly popular and making good progress. However, these methods still face some challenges. Existing methods lack a direct representation of depth information, which makes object reconstruction unrestricted by geometric features, resulting in poor reconstruction of objects with texture and color features. This is because existing methods only use surface normals to represent implicit surfaces without using depth information. Therefore, these methods cannot model the detailed surface features of objects well. To address this problem, we propose a neural implicit surface learning method called Depth-NeuS based on depth information optimization for multi-view reconstruction. In this paper, we introduce depth loss to explicitly constrain SDF regression and introduce geometric consistency loss to optimize for low-texture areas. Specific experiments show that Depth-NeuS outperforms existing technologies in multiple scenarios and achieves high-quality surface reconstruction in multiple scenarios.
FedTADBench: Federated Time-Series Anomaly Detection Benchmark
Dec 19, 2022
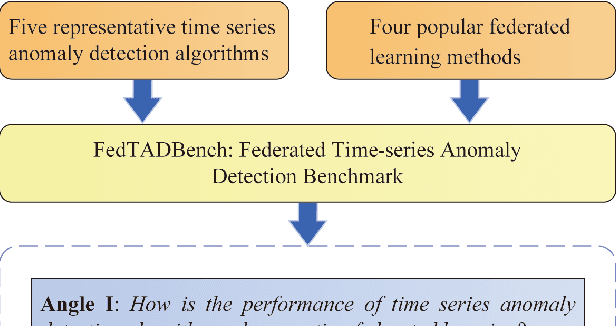
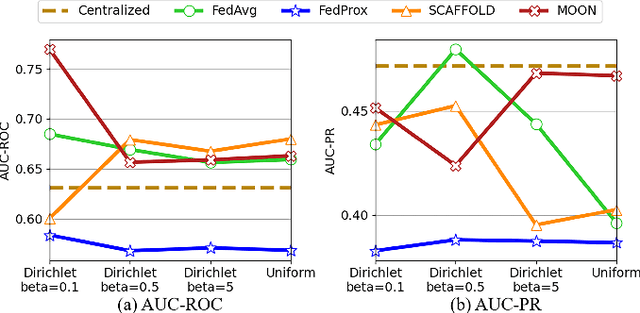
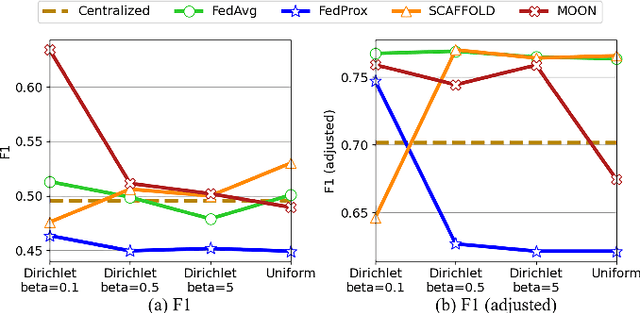
Time series anomaly detection strives to uncover potential abnormal behaviors and patterns from temporal data, and has fundamental significance in diverse application scenarios. Constructing an effective detection model usually requires adequate training data stored in a centralized manner, however, this requirement sometimes could not be satisfied in realistic scenarios. As a prevailing approach to address the above problem, federated learning has demonstrated its power to cooperate with the distributed data available while protecting the privacy of data providers. However, it is still unclear that how existing time series anomaly detection algorithms perform with decentralized data storage and privacy protection through federated learning. To study this, we conduct a federated time series anomaly detection benchmark, named FedTADBench, which involves five representative time series anomaly detection algorithms and four popular federated learning methods. We would like to answer the following questions: (1)How is the performance of time series anomaly detection algorithms when meeting federated learning? (2) Which federated learning method is the most appropriate one for time series anomaly detection? (3) How do federated time series anomaly detection approaches perform on different partitions of data in clients? Numbers of results as well as corresponding analysis are provided from extensive experiments with various settings. The source code of our benchmark is publicly available at https://github.com/fanxingliu2020/FedTADBench.
Many could be better than all: A novel instance-oriented algorithm for Multi-modal Multi-label problem
Jul 27, 2019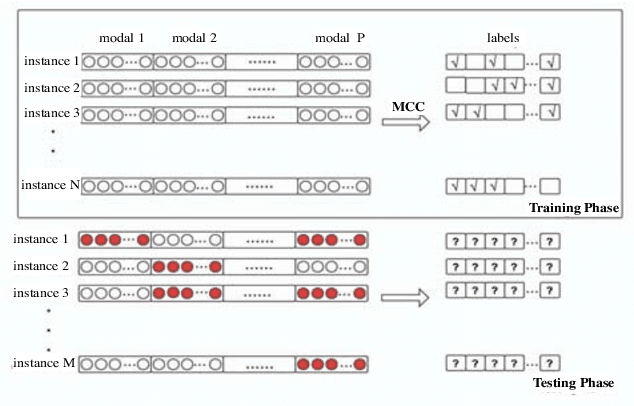
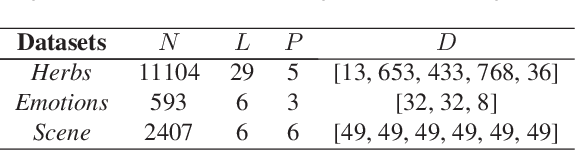
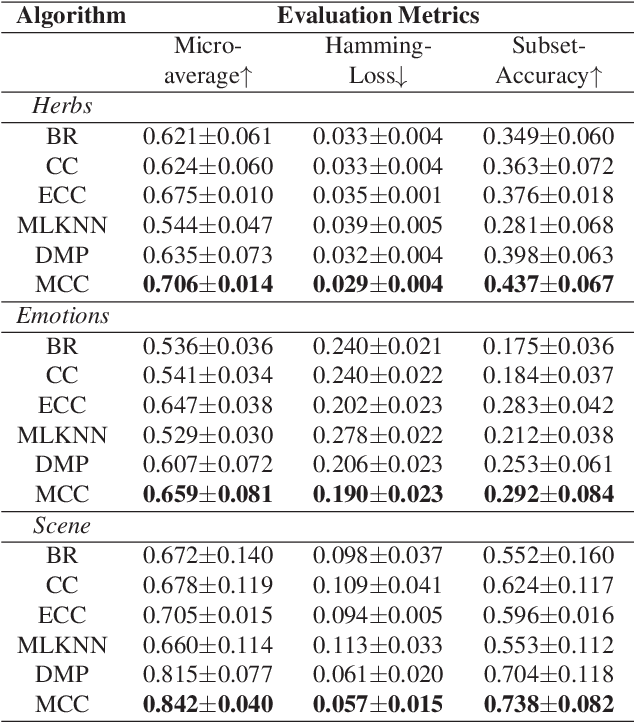

With the emergence of diverse data collection techniques, objects in real applications can be represented as multi-modal features. What's more, objects may have multiple semantic meanings. Multi-modal and Multi-label (MMML) problem becomes a universal phenomenon. The quality of data collected from different channels are inconsistent and some of them may not benefit for prediction. In real life, not all the modalities are needed for prediction. As a result, we propose a novel instance-oriented Multi-modal Classifier Chains (MCC) algorithm for MMML problem, which can make convince prediction with partial modalities. MCC extracts different modalities for different instances in the testing phase. Extensive experiments are performed on one real-world herbs dataset and two public datasets to validate our proposed algorithm, which reveals that it may be better to extract many instead of all of the modalities at hand.
A Logarithmic Barrier Method For Proximal Policy Optimization
Dec 16, 2018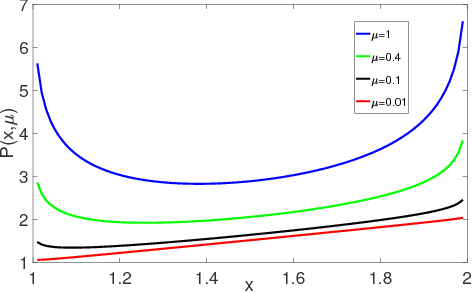
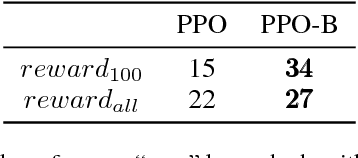

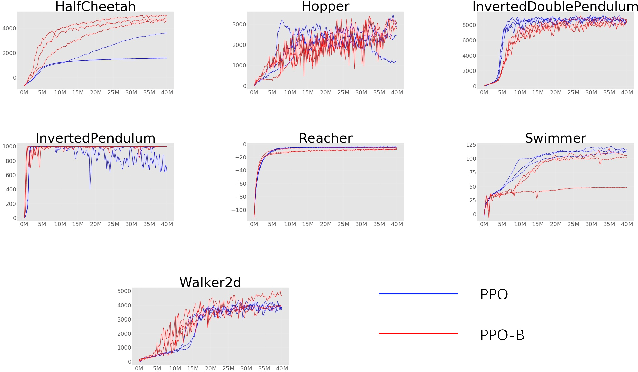
Proximal policy optimization(PPO) has been proposed as a first-order optimization method for reinforcement learning. We should notice that an exterior penalty method is used in it. Often, the minimizers of the exterior penalty functions approach feasibility only in the limits as the penalty parameter grows increasingly large. Therefore, it may result in the low level of sampling efficiency. This method, which we call proximal policy optimization with barrier method (PPO-B), keeps almost all advantageous spheres of PPO such as easy implementation and good generalization. Specifically, a new surrogate objective with interior penalty method is proposed to avoid the defect arose from exterior penalty method. Conclusions can be draw that PPO-B is able to outperform PPO in terms of sampling efficiency since PPO-B achieved clearly better performance on Atari and Mujoco environment than PPO.