 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChengwei Qin
Relevant or Random: Can LLMs Truly Perform Analogical Reasoning?
Apr 19, 2024
Analogical reasoning is a unique ability of humans to address unfamiliar challenges by transferring strategies from relevant past experiences. One key finding in psychology is that compared with irrelevant past experiences, recalling relevant ones can help humans better handle new tasks. Coincidentally, the NLP community has also recently found that self-generating relevant examples in the context can help large language models (LLMs) better solve a given problem than hand-crafted prompts. However, it is yet not clear whether relevance is the key factor eliciting such capability, i.e., can LLMs benefit more from self-generated relevant examples than irrelevant ones? In this work, we systematically explore whether LLMs can truly perform analogical reasoning on a diverse set of reasoning tasks. With extensive experiments and analysis, we show that self-generated random examples can surprisingly achieve comparable or even better performance, e.g., 4% performance boost on GSM8K with random biological examples. We find that the accuracy of self-generated examples is the key factor and subsequently design two improved methods with significantly reduced inference costs. Overall, we aim to advance a deeper understanding of LLM analogical reasoning and hope this work stimulates further research in the design of self-generated contexts.
Lifelong Event Detection with Embedding Space Separation and Compaction
Apr 03, 2024To mitigate forgetting, existing lifelong event detection methods typically maintain a memory module and replay the stored memory data during the learning of a new task. However, the simple combination of memory data and new-task samples can still result in substantial forgetting of previously acquired knowledge, which may occur due to the potential overlap between the feature distribution of new data and the previously learned embedding space. Moreover, the model suffers from overfitting on the few memory samples rather than effectively remembering learned patterns. To address the challenges of forgetting and overfitting, we propose a novel method based on embedding space separation and compaction. Our method alleviates forgetting of previously learned tasks by forcing the feature distribution of new data away from the previous embedding space. It also mitigates overfitting by a memory calibration mechanism that encourages memory data to be close to its prototype to enhance intra-class compactness. In addition, the learnable parameters of the new task are initialized by drawing upon acquired knowledge from the previously learned task to facilitate forward knowledge transfer. With extensive experiments, we demonstrate that our method can significantly outperform previous state-of-the-art approaches.
How Much are LLMs Contaminated? A Comprehensive Survey and the LLMSanitize Library
Mar 31, 2024With the rise of Large Language Models (LLMs) in recent years, new opportunities are emerging, but also new challenges, and contamination is quickly becoming critical. Business applications and fundraising in AI have reached a scale at which a few percentage points gained on popular question-answering benchmarks could translate into dozens of millions of dollars, placing high pressure on model integrity. At the same time, it is becoming harder and harder to keep track of the data that LLMs have seen; if not impossible with closed-source models like GPT-4 and Claude-3 not divulging any information on the training set. As a result, contamination becomes a critical issue: LLMs' performance may not be reliable anymore, as the high performance may be at least partly due to their previous exposure to the data. This limitation jeopardizes the entire progress in the field of NLP, yet, there remains a lack of methods on how to efficiently address contamination, or a clear consensus on prevention, mitigation and classification of contamination. In this paper, we survey all recent work on contamination with LLMs, and help the community track contamination levels of LLMs by releasing an open-source Python library named LLMSanitize implementing major contamination detection algorithms, which link is: https://github.com/ntunlp/LLMSanitize.
Data Augmentation using LLMs: Data Perspectives, Learning Paradigms and Challenges
Mar 05, 2024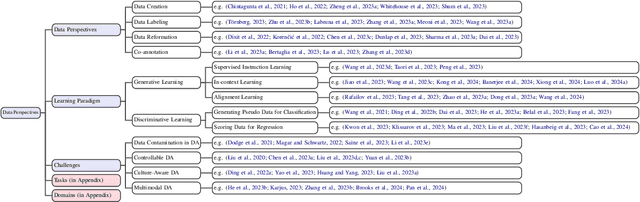
In the rapidly evolving field of machine learning (ML), data augmentation (DA) has emerged as a pivotal technique for enhancing model performance by diversifying training examples without the need for additional data collection. This survey explores the transformative impact of Large Language Models (LLMs) on DA, particularly addressing the unique challenges and opportunities they present in the context of natural language processing (NLP) and beyond. From a data perspective and a learning perspective, we examine various strategies that utilize Large Language Models for data augmentation, including a novel exploration of learning paradigms where LLM-generated data is used for further training. Additionally, this paper delineates the primary challenges faced in this domain, ranging from controllable data augmentation to multi modal data augmentation. This survey highlights the paradigm shift introduced by LLMs in DA, aims to serve as a foundational guide for researchers and practitioners in this field.
Learning Planning-based Reasoning by Trajectories Collection and Process Reward Synthesizing
Feb 01, 2024Large Language Models (LLMs) have demonstrated significant potential in handling complex reasoning tasks through step-by-step rationale generation. However, recent studies have raised concerns regarding the hallucination and flaws in their reasoning process. Substantial efforts are being made to improve the reliability and faithfulness of the generated rationales. Some approaches model reasoning as planning, while others focus on annotating for process supervision. Nevertheless, the planning-based search process often results in high latency due to the frequent assessment of intermediate reasoning states and the extensive exploration space. Additionally, supervising the reasoning process with human annotation is costly and challenging to scale for LLM training. To address these issues, in this paper, we propose a framework to learn planning-based reasoning through direct preference optimization (DPO) on collected trajectories, which are ranked according to synthesized process rewards. Our results on challenging logical reasoning benchmarks demonstrate the effectiveness of our learning framework, showing that our 7B model can surpass the strong counterparts like GPT-3.5-Turbo.
Chain of LoRA: Efficient Fine-tuning of Language Models via Residual Learning
Jan 08, 2024Fine-tuning is the primary methodology for tailoring pre-trained large language models to specific tasks. As the model's scale and the diversity of tasks expand, parameter-efficient fine-tuning methods are of paramount importance. One of the most widely used family of methods is low-rank adaptation (LoRA) and its variants. LoRA encodes weight update as the product of two low-rank matrices. Despite its advantages, LoRA falls short of full-parameter fine-tuning in terms of generalization error for certain tasks. We introduce Chain of LoRA (COLA), an iterative optimization framework inspired by the Frank-Wolfe algorithm, to bridge the gap between LoRA and full parameter fine-tuning, without incurring additional computational costs or memory overheads. COLA employs a residual learning procedure where it merges learned LoRA modules into the pre-trained language model parameters and re-initilize optimization for new born LoRA modules. We provide theoretical convergence guarantees as well as empirical results to validate the effectiveness of our algorithm. Across various models (OPT and llama-2) and seven benchmarking tasks, we demonstrate that COLA can consistently outperform LoRA without additional computational or memory costs.
Improving In-context Learning via Bidirectional Alignment
Dec 28, 2023Large language models (LLMs) have shown impressive few-shot generalization on many tasks via in-context learning (ICL). Despite their success in showing such emergent abilities, the scale and complexity of larger models also lead to unprecedentedly high computational demands and deployment challenges. In reaction, researchers explore transferring the powerful capabilities of larger models to more efficient and compact models by typically aligning the output of smaller models with that of larger models. Existing methods either train smaller models on the generated outputs of larger models or to imitate their token-level probability distributions. However, these distillation methods pay little to no attention to the input part, which also plays a crucial role in ICL. Based on the finding that the performance of ICL is highly sensitive to the selection of demonstration examples, we propose Bidirectional Alignment (BiAlign) to fully leverage the models' preferences for ICL examples to improve the ICL abilities of smaller models. Specifically, we introduce the alignment of input preferences between smaller and larger models by incorporating a novel ranking loss, in addition to aligning the token-level output distribution. With extensive experiments and analysis, we demonstrate that BiAlign can consistently outperform existing baselines on a variety of tasks including language understanding, reasoning, and coding.
ChatGPT's One-year Anniversary: Are Open-Source Large Language Models Catching up?
Dec 05, 2023Upon its release in late 2022, ChatGPT has brought a seismic shift in the entire landscape of AI, both in research and commerce. Through instruction-tuning a large language model (LLM) with supervised fine-tuning and reinforcement learning from human feedback, it showed that a model could answer human questions and follow instructions on a broad panel of tasks. Following this success, interests in LLMs have intensified, with new LLMs flourishing at frequent interval across academia and industry, including many start-ups focused on LLMs. While closed-source LLMs (e.g., OpenAI's GPT, Anthropic's Claude) generally outperform their open-source counterparts, the progress on the latter has been rapid with claims of achieving parity or even better on certain tasks. This has crucial implications not only on research but also on business. In this work, on the first anniversary of ChatGPT, we provide an exhaustive overview of this success, surveying all tasks where an open-source LLM has claimed to be on par or better than ChatGPT.
In-Context Learning with Iterative Demonstration Selection
Oct 22, 2023Spurred by advancements in scale, large language models (LLMs) have demonstrated strong few-shot learning ability via in-context learning (ICL). However, the performance of ICL has been shown to be highly sensitive to the selection of few-shot demonstrations. Selecting the most suitable examples as context remains an ongoing challenge and an open problem. Existing literature has highlighted the importance of selecting examples that are diverse or semantically similar to the test sample while ignoring the fact that the optimal selection dimension, i.e., diversity or similarity, is task-specific. Leveraging the merits of both dimensions, we propose Iterative Demonstration Selection (IDS). Using zero-shot chain-of-thought reasoning (Zero-shot-CoT), IDS iteratively selects examples that are diverse but still strongly correlated with the test sample as ICL demonstrations. Specifically, IDS applies Zero-shot-CoT to the test sample before demonstration selection. The output reasoning path is then used to choose demonstrations that are prepended to the test sample for inference. The generated answer is accompanied by its corresponding reasoning path for extracting a new set of demonstrations in the next iteration. After several iterations, IDS adopts majority voting to obtain the final result. Through extensive experiments on tasks including commonsense reasoning, question answering, topic classification, and sentiment analysis, we demonstrate that IDS can consistently outperform existing ICL demonstration selection methods.
Lifelong Sequence Generation with Dynamic Module Expansion and Adaptation
Oct 20, 2023Lifelong sequence generation (LSG), a problem in continual learning, aims to continually train a model on a sequence of generation tasks to learn constantly emerging new generation patterns while avoiding the forgetting of previous knowledge. Existing LSG methods mainly focus on maintaining old knowledge while paying little attention to knowledge transfer across tasks. In contrast, humans can better learn new tasks by leveraging previously acquired knowledge from similar tasks. Inspired by the learning paradigm of humans, we propose Dynamic Module Expansion and Adaptation (DMEA), which enables the model to dynamically determine the architecture for acquiring new knowledge based on task correlation and select the most similar previous tasks to facilitate adaptation to new tasks. In addition, as the learning process can easily be biased towards the current task which might cause more severe forgetting of previously learned knowledge, we propose dynamic gradient scaling to balance the learning of the current task and replayed tasks. With extensive experiments, we demonstrate that DMEA can consistently outperform existing methods in different LSG settings.