 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChengyu Du
Enhancing Confidence Expression in Large Language Models Through Learning from Past Experience
Apr 16, 2024
Large Language Models (LLMs) have exhibited remarkable performance across various downstream tasks, but they may generate inaccurate or false information with a confident tone. One of the possible solutions is to empower the LLM confidence expression capability, in which the confidence expressed can be well-aligned with the true probability of the generated answer being correct. However, leveraging the intrinsic ability of LLMs or the signals from the output logits of answers proves challenging in accurately capturing the response uncertainty in LLMs. Therefore, drawing inspiration from cognitive diagnostics, we propose a method of Learning from Past experience (LePe) to enhance the capability for confidence expression. Specifically, we first identify three key problems: (1) How to capture the inherent confidence of the LLM? (2) How to teach the LLM to express confidence? (3) How to evaluate the confidence expression of the LLM? Then we devise three stages in LePe to deal with these problems. Besides, to accurately capture the confidence of an LLM when constructing the training data, we design a complete pipeline including question preparation and answer sampling. We also conduct experiments using the Llama family of LLMs to verify the effectiveness of our proposed method on four datasets.
Large Language Model Can Continue Evolving From Mistakes
Apr 11, 2024Large Language Models (LLMs) demonstrate impressive performance in various downstream tasks. However, they may still generate incorrect responses in certain scenarios due to the knowledge deficiencies and the flawed pre-training data. Continual Learning (CL) is a commonly used method to address this issue. Traditional CL is task-oriented, using novel or factually accurate data to retrain LLMs from scratch. However, this method requires more task-related training data and incurs expensive training costs. To address this challenge, we propose the Continue Evolving from Mistakes (CEM) method, inspired by the 'summarize mistakes' learning skill, to achieve iterative refinement of LLMs. Specifically, the incorrect responses of LLMs indicate knowledge deficiencies related to the questions. Therefore, we collect corpora with these knowledge from multiple data sources and follow it up with iterative supplementary training for continuous, targeted knowledge updating and supplementation. Meanwhile, we developed two strategies to construct supplementary training sets to enhance the LLM's understanding of the corpus and prevent catastrophic forgetting. We conducted extensive experiments to validate the effectiveness of this CL method. In the best case, our method resulted in a 17.00\% improvement in the accuracy of the LLM.
Emotion Action Detection and Emotion Inference: the Task and Dataset
Mar 16, 2019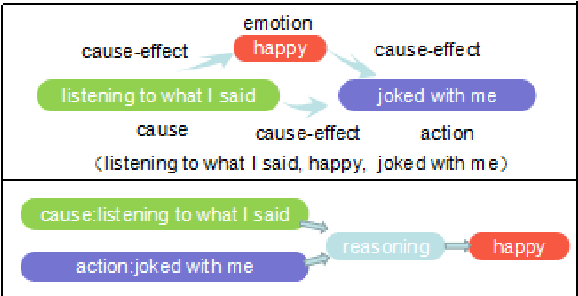


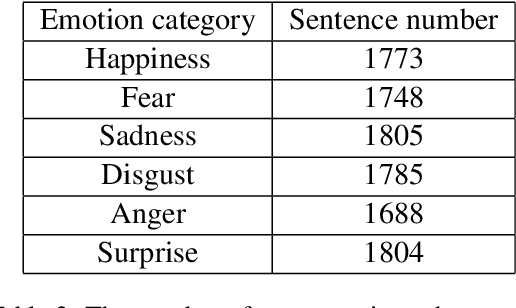
Many Natural Language Processing works on emotion analysis only focus on simple emotion classification without exploring the potentials of putting emotion into "event context", and ignore the analysis of emotion-related events. One main reason is the lack of this kind of corpus. Here we present Cause-Emotion-Action Corpus, which manually annotates not only emotion, but also cause events and action events. We propose two new tasks based on the data-set: emotion causality and emotion inference. The first task is to extract a triple (cause, emotion, action). The second task is to infer the probable emotion. We are currently releasing the data-set with 10,603 samples and 15,892 events, basic statistic analysis and baseline on both emotion causality and emotion inference tasks. Baseline performance demonstrates that there is much room for both tasks to be improved.