 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChengzhengxu Li
StablePT: Towards Stable Prompting for Few-shot Learning via Input Separation
Apr 30, 2024
Large language models have shown their ability to become effective few-shot learners with prompting, revoluting the paradigm of learning with data scarcity. However, this approach largely depends on the quality of prompt initialization, and always exhibits large variability among different runs. Such property makes prompt tuning highly unreliable and vulnerable to poorly constructed prompts, which limits its extension to more real-world applications. To tackle this issue, we propose to treat the hard prompt and soft prompt as separate inputs to mitigate noise brought by the prompt initialization. Furthermore, we optimize soft prompts with contrastive learning for utilizing class-aware information in the training process to maintain model performance. Experimental results demonstrate that \sysname outperforms state-of-the-art methods by 7.20% in accuracy and reduces the standard deviation by 2.02 on average. Furthermore, extensive experiments underscore its robustness and stability across 7 datasets covering various tasks.
Does DetectGPT Fully Utilize Perturbation? Selective Perturbation on Model-Based Contrastive Learning Detector would be Better
Feb 04, 2024The burgeoning capabilities of large language models (LLMs) have raised growing concerns about abuse. DetectGPT, a zero-shot metric-based unsupervised machine-generated text detector, first introduces perturbation and shows great performance improvement. However, DetectGPT's random perturbation strategy might introduce noise, limiting the distinguishability and further performance improvements. Moreover, its logit regression module relies on setting the threshold, which harms the generalizability and applicability of individual or small-batch inputs. Hence, we propose a novel detector, Pecola, which uses selective strategy perturbation to relieve the information loss caused by random masking, and multi-pair contrastive learning to capture the implicit pattern information during perturbation, facilitating few-shot performance. The experiments show that Pecola outperforms the SOTA method by 1.20% in accuracy on average on four public datasets. We further analyze the effectiveness, robustness, and generalization of our perturbation method.
Dialogue for Prompting: a Policy-Gradient-Based Discrete Prompt Optimization for Few-shot Learning
Aug 14, 2023
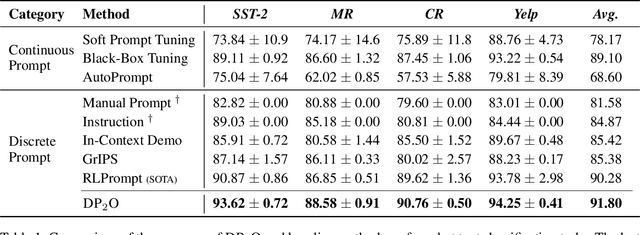

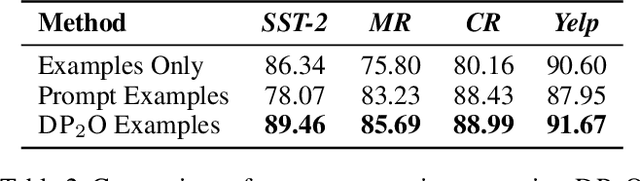
Prompt-based pre-trained language models (PLMs) paradigm have succeeded substantially in few-shot natural language processing (NLP) tasks. However, prior discrete prompt optimization methods require expert knowledge to design the base prompt set and identify high-quality prompts, which is costly, inefficient, and subjective. Meanwhile, existing continuous prompt optimization methods improve the performance by learning the ideal prompts through the gradient information of PLMs, whose high computational cost, and low readability and generalizability are often concerning. To address the research gap, we propose a Dialogue-comprised Policy-gradient-based Discrete Prompt Optimization ($DP_2O$) method. We first design a multi-round dialogue alignment strategy for readability prompt set generation based on GPT-4. Furthermore, we propose an efficient prompt screening metric to identify high-quality prompts with linear complexity. Finally, we construct a reinforcement learning (RL) framework based on policy gradients to match the prompts to inputs optimally. By training a policy network with only 0.67% of the PLM parameter size on the tasks in the few-shot setting, $DP_2O$ outperforms the state-of-the-art (SOTA) method by 1.52% in accuracy on average on four open-source datasets. Moreover, subsequent experiments also demonstrate that $DP_2O$ has good universality, robustness, and generalization ability.