 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChenhui Xu
QuadraNet V2: Efficient and Sustainable Training of High-Order Neural Networks with Quadratic Adaptation
May 06, 2024
Machine learning is evolving towards high-order models that necessitate pre-training on extensive datasets, a process associated with significant overheads. Traditional models, despite having pre-trained weights, are becoming obsolete due to architectural differences that obstruct the effective transfer and initialization of these weights. To address these challenges, we introduce a novel framework, QuadraNet V2, which leverages quadratic neural networks to create efficient and sustainable high-order learning models. Our method initializes the primary term of the quadratic neuron using a standard neural network, while the quadratic term is employed to adaptively enhance the learning of data non-linearity or shifts. This integration of pre-trained primary terms with quadratic terms, which possess advanced modeling capabilities, significantly augments the information characterization capacity of the high-order network. By utilizing existing pre-trained weights, QuadraNet V2 reduces the required GPU hours for training by 90\% to 98.4\% compared to training from scratch, demonstrating both efficiency and effectiveness.
Out-of-Distribution Detection via Deep Multi-Comprehension Ensemble
Mar 24, 2024Recent research underscores the pivotal role of the Out-of-Distribution (OOD) feature representation field scale in determining the efficacy of models in OOD detection. Consequently, the adoption of model ensembles has emerged as a prominent strategy to augment this feature representation field, capitalizing on anticipated model diversity. However, our introduction of novel qualitative and quantitative model ensemble evaluation methods, specifically Loss Basin/Barrier Visualization and the Self-Coupling Index, reveals a critical drawback in existing ensemble methods. We find that these methods incorporate weights that are affine-transformable, exhibiting limited variability and thus failing to achieve the desired diversity in feature representation. To address this limitation, we elevate the dimensions of traditional model ensembles, incorporating various factors such as different weight initializations, data holdout, etc., into distinct supervision tasks. This innovative approach, termed Multi-Comprehension (MC) Ensemble, leverages diverse training tasks to generate distinct comprehensions of the data and labels, thereby extending the feature representation field. Our experimental results demonstrate the superior performance of the MC Ensemble strategy in OOD detection compared to both the naive Deep Ensemble method and a standalone model of comparable size. This underscores the effectiveness of our proposed approach in enhancing the model's capability to detect instances outside its training distribution.
QuadraNet: Improving High-Order Neural Interaction Efficiency with Hardware-Aware Quadratic Neural Networks
Nov 29, 2023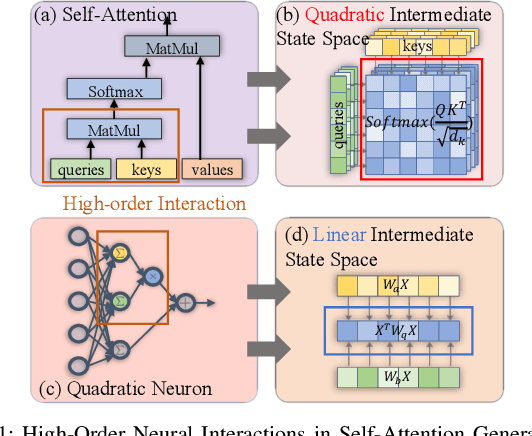
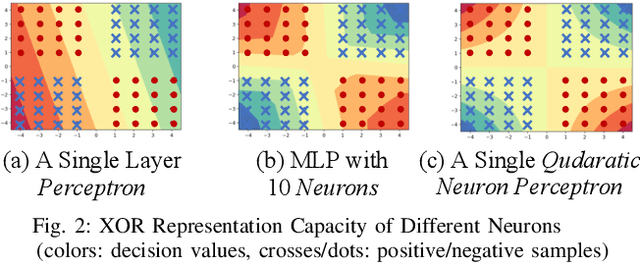
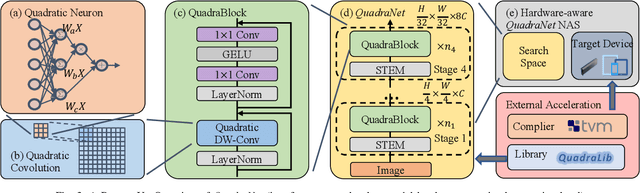
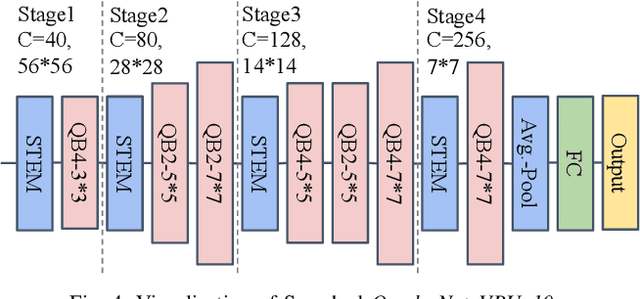
Recent progress in computer vision-oriented neural network designs is mostly driven by capturing high-order neural interactions among inputs and features. And there emerged a variety of approaches to accomplish this, such as Transformers and its variants. However, these interactions generate a large amount of intermediate state and/or strong data dependency, leading to considerable memory consumption and computing cost, and therefore compromising the overall runtime performance. To address this challenge, we rethink the high-order interactive neural network design with a quadratic computing approach. Specifically, we propose QuadraNet -- a comprehensive model design methodology from neuron reconstruction to structural block and eventually to the overall neural network implementation. Leveraging quadratic neurons' intrinsic high-order advantages and dedicated computation optimization schemes, QuadraNet could effectively achieve optimal cognition and computation performance. Incorporating state-of-the-art hardware-aware neural architecture search and system integration techniques, QuadraNet could also be well generalized in different hardware constraint settings and deployment scenarios. The experiment shows thatQuadraNet achieves up to 1.5$\times$ throughput, 30% less memory footprint, and similar cognition performance, compared with the state-of-the-art high-order approaches.