 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChia-Hao Shen
Almost-unsupervised Speech Recognition with Close-to-zero Resource Based on Phonetic Structures Learned from Very Small Unpaired Speech and Text Data
Oct 30, 2018
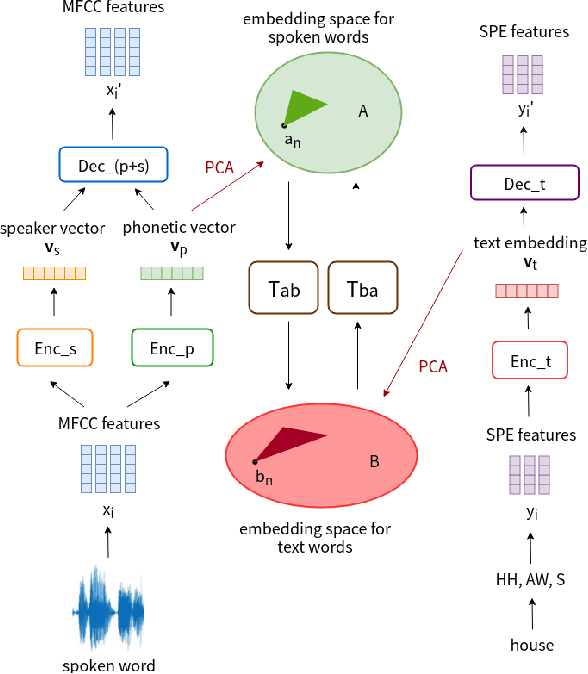
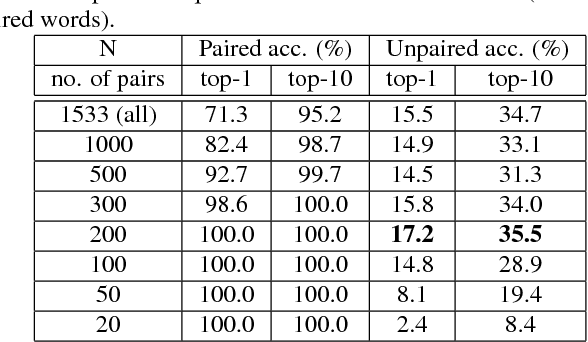
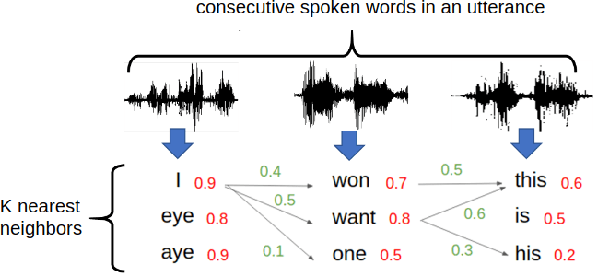
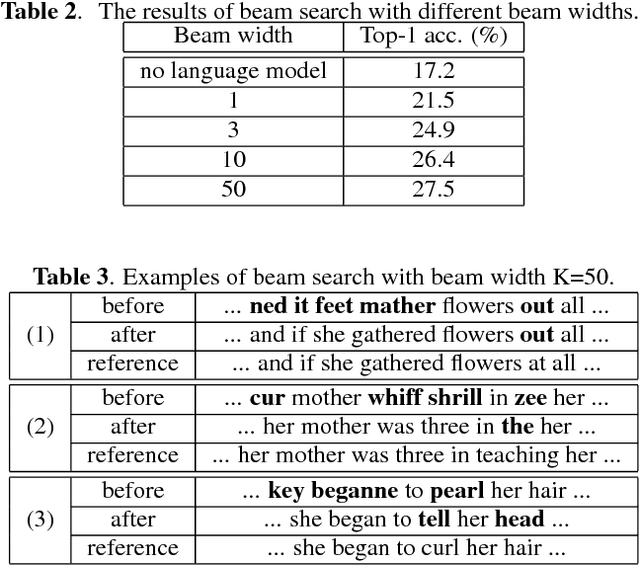
Producing a large amount of annotated speech data for training ASR systems remains difficult for more than 95% of languages all over the world which are low-resourced. However, we note human babies start to learn the language by the sounds of a small number of exemplar words without hearing a large amount of data. We initiate some preliminary work in this direction in this paper. Audio Word2Vec is used to obtain embeddings of spoken words which carry phonetic information extracted from the signals. An autoencoder is used to generate embeddings of text words based on the articulatory features for the phoneme sequences. Both sets of embeddings for spoken and text words describe similar phonetic structures among words in their respective latent spaces. A mapping relation from the audio embeddings to text embeddings actually gives the word-level ASR. This can be learned by aligning a small number of spoken words and the corresponding text words in the embedding spaces. In the initial experiments only 200 annotated spoken words and one hour of speech data without annotation gave a word accuracy of 27.5%, which is low but a good starting point.
Phonetic-and-Semantic Embedding of Spoken Words with Applications in Spoken Content Retrieval
Sep 03, 2018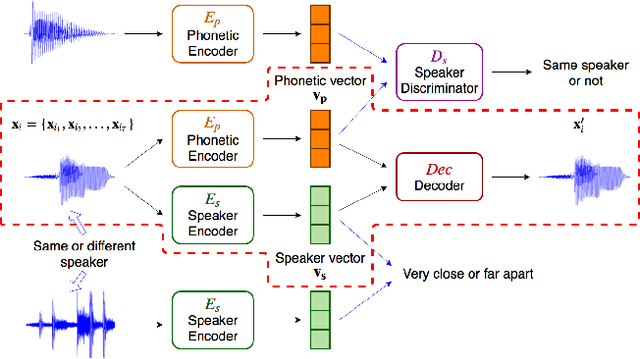
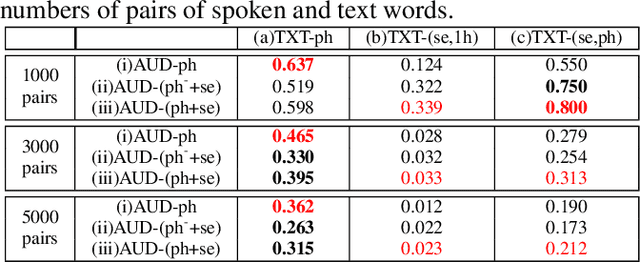
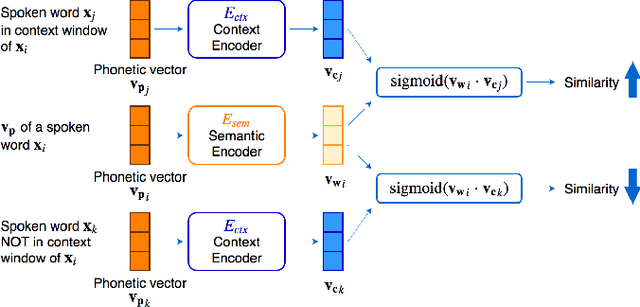
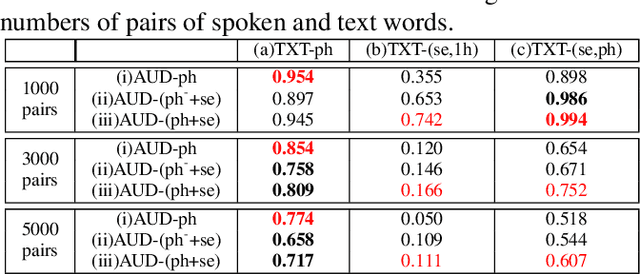
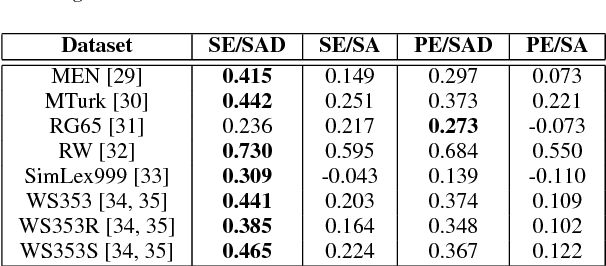
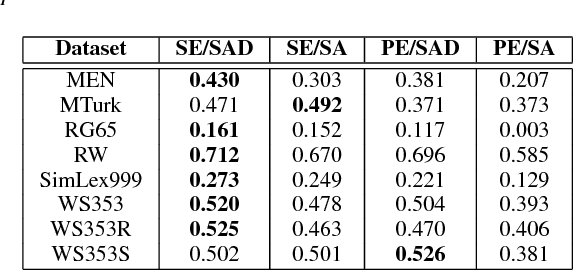
Word embedding or Word2Vec has been successful in offering semantics for text words learned from the context of words. Audio Word2Vec was shown to offer phonetic structures for spoken words (signal segments for words) learned from signals within spoken words. This paper proposes a two-stage framework to perform phonetic-and-semantic embedding on spoken words considering the context of the spoken words. Stage 1 performs phonetic embedding with speaker characteristics disentangled. Stage 2 then performs semantic embedding in addition. We further propose to evaluate the phonetic-and-semantic nature of the audio embeddings obtained in Stage 2 by parallelizing with text embeddings. In general, phonetic structure and semantics inevitably disturb each other. For example the words "brother" and "sister" are close in semantics but very different in phonetic structure, while the words "brother" and "bother" are in the other way around. But phonetic-and-semantic embedding is attractive, as shown in the initial experiments on spoken document retrieval. Not only spoken documents including the spoken query can be retrieved based on the phonetic structures, but spoken documents semantically related to the query but not including the query can also be retrieved based on the semantics.
Towards Unsupervised Automatic Speech Recognition Trained by Unaligned Speech and Text only
Aug 11, 2018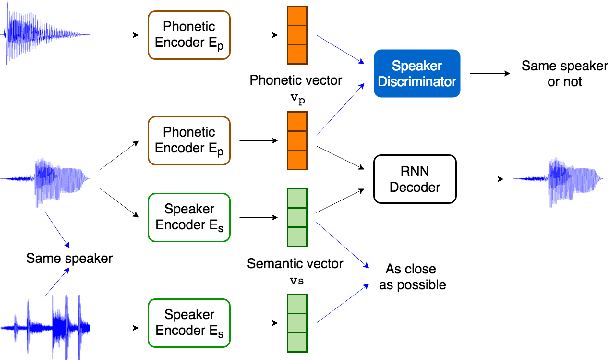
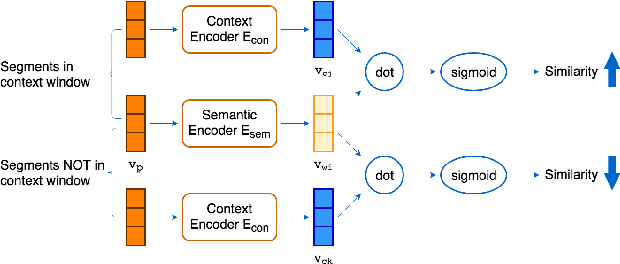
Automatic speech recognition (ASR) has been widely researched with supervised approaches, while many low-resourced languages lack audio-text aligned data, and supervised methods cannot be applied on them. In this work, we propose a framework to achieve unsupervised ASR on a read English speech dataset, where audio and text are unaligned. In the first stage, each word-level audio segment in the utterances is represented by a vector representation extracted by a sequence-of-sequence autoencoder, in which phonetic information and speaker information are disentangled. Secondly, semantic embeddings of audio segments are trained from the vector representations using a skip-gram model. Last but not the least, an unsupervised method is utilized to transform semantic embeddings of audio segments to text embedding space, and finally the transformed embeddings are mapped to words. With the above framework, we are towards unsupervised ASR trained by unaligned text and speech only.
Language Transfer of Audio Word2Vec: Learning Audio Segment Representations without Target Language Data
Jul 19, 2017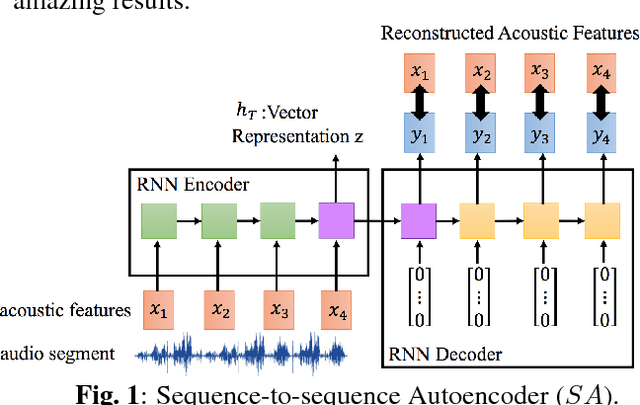
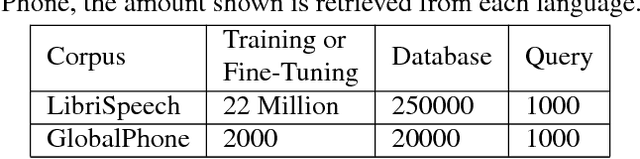
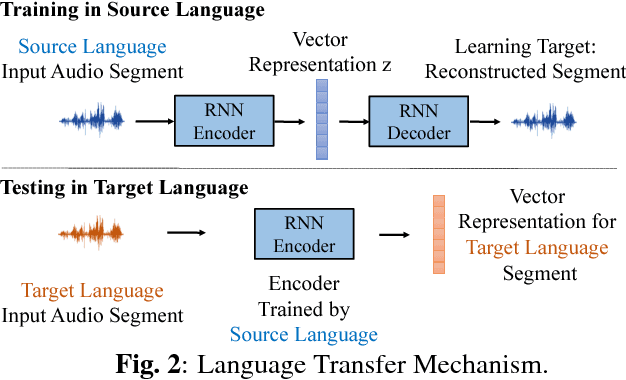
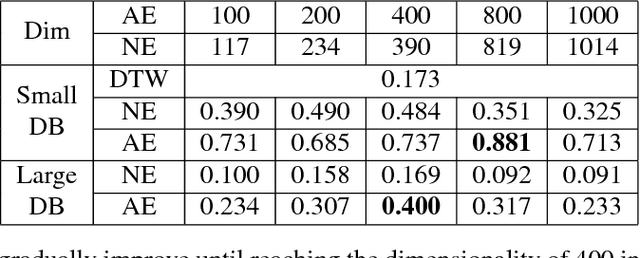
Audio Word2Vec offers vector representations of fixed dimensionality for variable-length audio segments using Sequence-to-sequence Autoencoder (SA). These vector representations are shown to describe the sequential phonetic structures of the audio segments to a good degree, with real world applications such as query-by-example Spoken Term Detection (STD). This paper examines the capability of language transfer of Audio Word2Vec. We train SA from one language (source language) and use it to extract the vector representation of the audio segments of another language (target language). We found that SA can still catch phonetic structure from the audio segments of the target language if the source and target languages are similar. In query-by-example STD, we obtain the vector representations from the SA learned from a large amount of source language data, and found them surpass the representations from naive encoder and SA directly learned from a small amount of target language data. The result shows that it is possible to learn Audio Word2Vec model from high-resource languages and use it on low-resource languages. This further expands the usability of Audio Word2Vec.
Audio Word2Vec: Unsupervised Learning of Audio Segment Representations using Sequence-to-sequence Autoencoder
Jun 11, 2016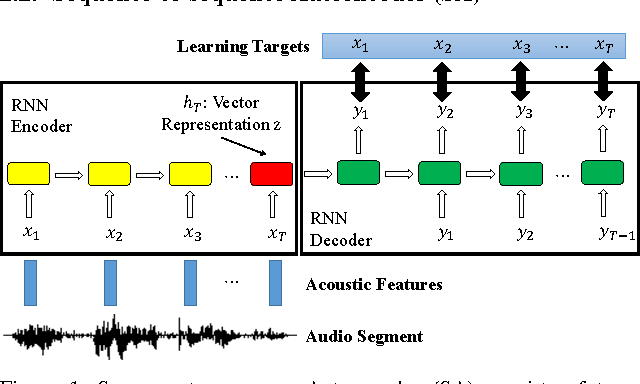
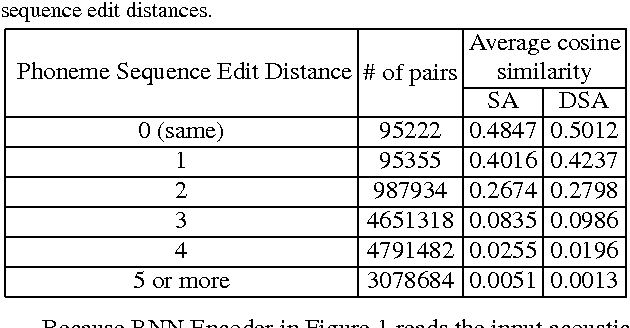
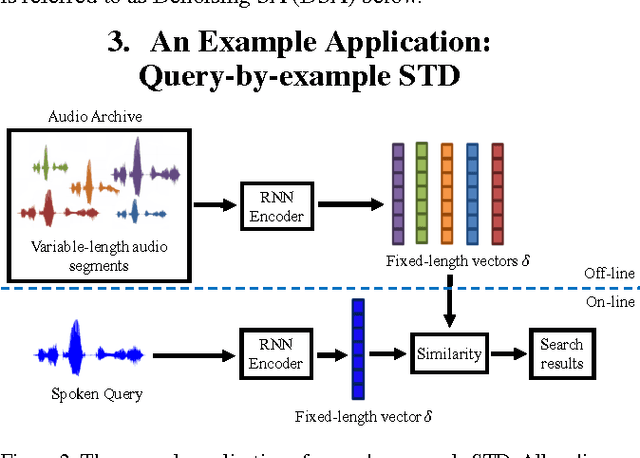
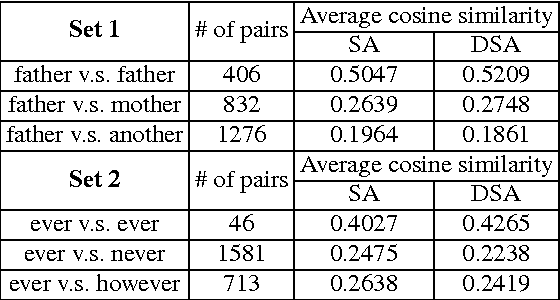
The vector representations of fixed dimensionality for words (in text) offered by Word2Vec have been shown to be very useful in many application scenarios, in particular due to the semantic information they carry. This paper proposes a parallel version, the Audio Word2Vec. It offers the vector representations of fixed dimensionality for variable-length audio segments. These vector representations are shown to describe the sequential phonetic structures of the audio segments to a good degree, with very attractive real world applications such as query-by-example Spoken Term Detection (STD). In this STD application, the proposed approach significantly outperformed the conventional Dynamic Time Warping (DTW) based approaches at significantly lower computation requirements. We propose unsupervised learning of Audio Word2Vec from audio data without human annotation using Sequence-to-sequence Audoencoder (SA). SA consists of two RNNs equipped with Long Short-Term Memory (LSTM) units: the first RNN (encoder) maps the input audio sequence into a vector representation of fixed dimensionality, and the second RNN (decoder) maps the representation back to the input audio sequence. The two RNNs are jointly trained by minimizing the reconstruction error. Denoising Sequence-to-sequence Autoencoder (DSA) is furthered proposed offering more robust learning.