 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChirag Modi
Batch and match: black-box variational inference with a score-based divergence
Feb 22, 2024
Most leading implementations of black-box variational inference (BBVI) are based on optimizing a stochastic evidence lower bound (ELBO). But such approaches to BBVI often converge slowly due to the high variance of their gradient estimates. In this work, we propose batch and match (BaM), an alternative approach to BBVI based on a score-based divergence. Notably, this score-based divergence can be optimized by a closed-form proximal update for Gaussian variational families with full covariance matrices. We analyze the convergence of BaM when the target distribution is Gaussian, and we prove that in the limit of infinite batch size the variational parameter updates converge exponentially quickly to the target mean and covariance. We also evaluate the performance of BaM on Gaussian and non-Gaussian target distributions that arise from posterior inference in hierarchical and deep generative models. In these experiments, we find that BaM typically converges in fewer (and sometimes significantly fewer) gradient evaluations than leading implementations of BBVI based on ELBO maximization.
LtU-ILI: An All-in-One Framework for Implicit Inference in Astrophysics and Cosmology
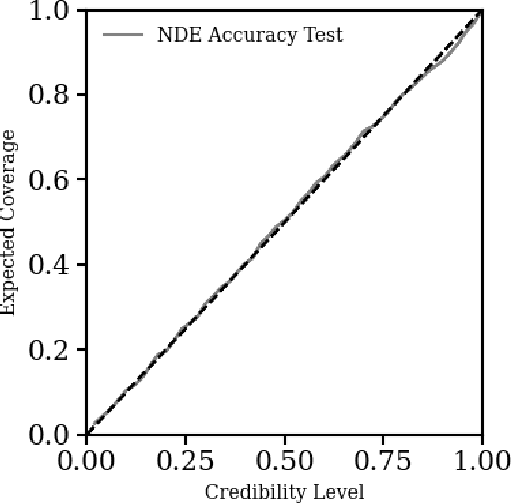
Feb 06, 2024This paper presents the Learning the Universe Implicit Likelihood Inference (LtU-ILI) pipeline, a codebase for rapid, user-friendly, and cutting-edge machine learning (ML) inference in astrophysics and cosmology. The pipeline includes software for implementing various neural architectures, training schema, priors, and density estimators in a manner easily adaptable to any research workflow. It includes comprehensive validation metrics to assess posterior estimate coverage, enhancing the reliability of inferred results. Additionally, the pipeline is easily parallelizable, designed for efficient exploration of modeling hyperparameters. To demonstrate its capabilities, we present real applications across a range of astrophysics and cosmology problems, such as: estimating galaxy cluster masses from X-ray photometry; inferring cosmology from matter power spectra and halo point clouds; characterising progenitors in gravitational wave signals; capturing physical dust parameters from galaxy colors and luminosities; and establishing properties of semi-analytic models of galaxy formation. We also include exhaustive benchmarking and comparisons of all implemented methods as well as discussions about the challenges and pitfalls of ML inference in astronomical sciences. All code and examples are made publicly available at https://github.com/maho3/ltu-ili.
SimBIG: Field-level Simulation-Based Inference of Galaxy Clustering
Oct 23, 2023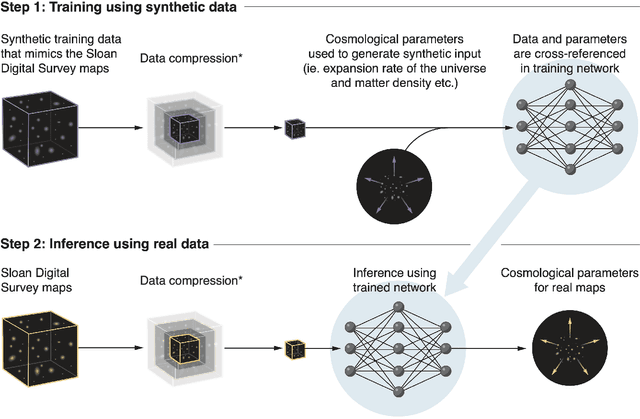
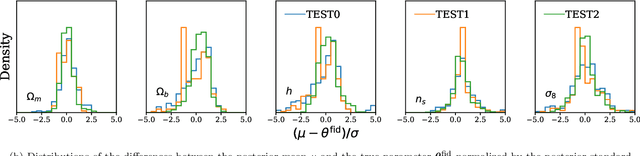
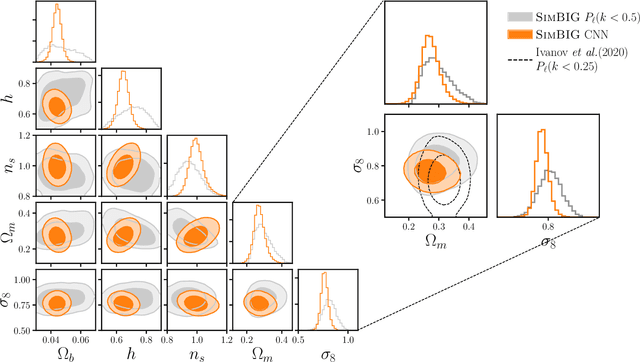
We present the first simulation-based inference (SBI) of cosmological parameters from field-level analysis of galaxy clustering. Standard galaxy clustering analyses rely on analyzing summary statistics, such as the power spectrum, $P_\ell$, with analytic models based on perturbation theory. Consequently, they do not fully exploit the non-linear and non-Gaussian features of the galaxy distribution. To address these limitations, we use the {\sc SimBIG} forward modelling framework to perform SBI using normalizing flows. We apply SimBIG to a subset of the BOSS CMASS galaxy sample using a convolutional neural network with stochastic weight averaging to perform massive data compression of the galaxy field. We infer constraints on $\Omega_m = 0.267^{+0.033}_{-0.029}$ and $\sigma_8=0.762^{+0.036}_{-0.035}$. While our constraints on $\Omega_m$ are in-line with standard $P_\ell$ analyses, those on $\sigma_8$ are $2.65\times$ tighter. Our analysis also provides constraints on the Hubble constant $H_0=64.5 \pm 3.8 \ {\rm km / s / Mpc}$ from galaxy clustering alone. This higher constraining power comes from additional non-Gaussian cosmological information, inaccessible with $P_\ell$. We demonstrate the robustness of our analysis by showcasing our ability to infer unbiased cosmological constraints from a series of test simulations that are constructed using different forward models than the one used in our training dataset. This work not only presents competitive cosmological constraints but also introduces novel methods for leveraging additional cosmological information in upcoming galaxy surveys like DESI, PFS, and Euclid.
Variational Inference with Gaussian Score Matching
Jul 15, 2023Variational inference (VI) is a method to approximate the computationally intractable posterior distributions that arise in Bayesian statistics. Typically, VI fits a simple parametric distribution to the target posterior by minimizing an appropriate objective such as the evidence lower bound (ELBO). In this work, we present a new approach to VI based on the principle of score matching, that if two distributions are equal then their score functions (i.e., gradients of the log density) are equal at every point on their support. With this, we develop score matching VI, an iterative algorithm that seeks to match the scores between the variational approximation and the exact posterior. At each iteration, score matching VI solves an inner optimization, one that minimally adjusts the current variational estimate to match the scores at a newly sampled value of the latent variables. We show that when the variational family is a Gaussian, this inner optimization enjoys a closed form solution, which we call Gaussian score matching VI (GSM-VI). GSM-VI is also a ``black box'' variational algorithm in that it only requires a differentiable joint distribution, and as such it can be applied to a wide class of models. We compare GSM-VI to black box variational inference (BBVI), which has similar requirements but instead optimizes the ELBO. We study how GSM-VI behaves as a function of the problem dimensionality, the condition number of the target covariance matrix (when the target is Gaussian), and the degree of mismatch between the approximating and exact posterior distribution. We also study GSM-VI on a collection of real-world Bayesian inference problems from the posteriorDB database of datasets and models. In all of our studies we find that GSM-VI is faster than BBVI, but without sacrificing accuracy. It requires 10-100x fewer gradient evaluations to obtain a comparable quality of approximation.
Reconstructing the Universe with Variational self-Boosted Sampling
Jun 28, 2022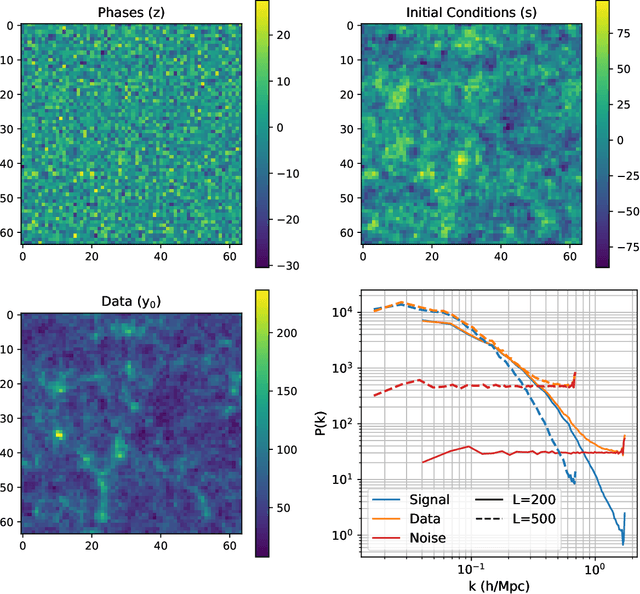


Forward modeling approaches in cosmology have made it possible to reconstruct the initial conditions at the beginning of the Universe from the observed survey data. However the high dimensionality of the parameter space still poses a challenge to explore the full posterior, with traditional algorithms such as Hamiltonian Monte Carlo (HMC) being computationally inefficient due to generating correlated samples and the performance of variational inference being highly dependent on the choice of divergence (loss) function. Here we develop a hybrid scheme, called variational self-boosted sampling (VBS) to mitigate the drawbacks of both these algorithms by learning a variational approximation for the proposal distribution of Monte Carlo sampling and combine it with HMC. The variational distribution is parameterized as a normalizing flow and learnt with samples generated on the fly, while proposals drawn from it reduce auto-correlation length in MCMC chains. Our normalizing flow uses Fourier space convolutions and element-wise operations to scale to high dimensions. We show that after a short initial warm-up and training phase, VBS generates better quality of samples than simple VI approaches and reduces the correlation length in the sampling phase by a factor of 10-50 over using only HMC to explore the posterior of initial conditions in 64$^3$ and 128$^3$ dimensional problems, with larger gains for high signal-to-noise data observations.
Delayed rejection Hamiltonian Monte Carlo for sampling multiscale distributions
Oct 01, 2021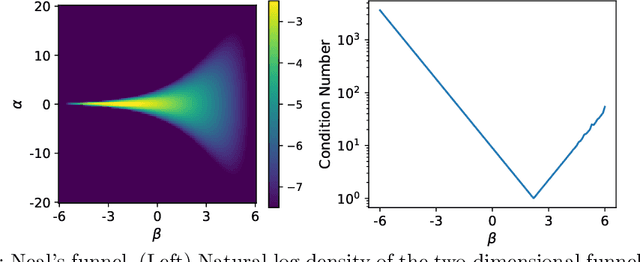

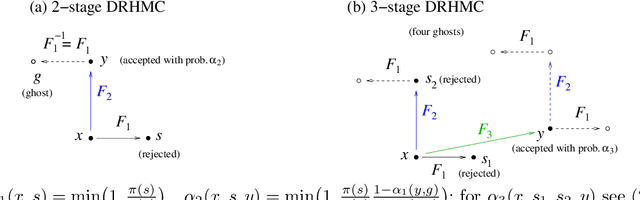

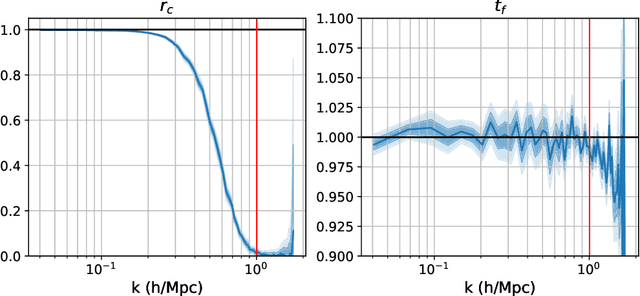
The efficiency of Hamiltonian Monte Carlo (HMC) can suffer when sampling a distribution with a wide range of length scales, because the small step sizes needed for stability in high-curvature regions are inefficient elsewhere. To address this we present a delayed rejection variant: if an initial HMC trajectory is rejected, we make one or more subsequent proposals each using a step size geometrically smaller than the last. We extend the standard delayed rejection framework by allowing the probability of a retry to depend on the probability of accepting the previous proposal. We test the scheme in several sampling tasks, including multiscale model distributions such as Neal's funnel, and statistical applications. Delayed rejection enables up to five-fold performance gains over optimally-tuned HMC, as measured by effective sample size per gradient evaluation. Even for simpler distributions, delayed rejection provides increased robustness to step size misspecification. Along the way, we provide an accessible but rigorous review of detailed balance for HMC.
Generative Learning of Counterfactual for Synthetic Control Applications in Econometrics
Oct 16, 2019

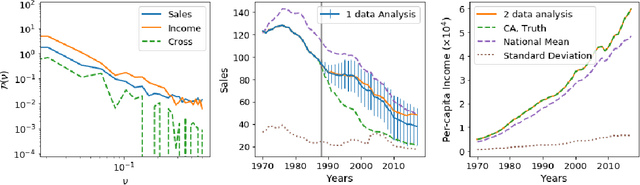
A common statistical problem in econometrics is to estimate the impact of a treatment on a treated unit given a control sample with untreated outcomes. Here we develop a generative learning approach to this problem, learning the probability distribution of the data, which can be used for downstream tasks such as post-treatment counterfactual prediction and hypothesis testing. We use control samples to transform the data to a Gaussian and homoschedastic form and then perform Gaussian process analysis in Fourier space, evaluating the optimal Gaussian kernel via non-parametric power spectrum estimation. We combine this Gaussian prior with the data likelihood given by the pre-treatment data of the single unit, to obtain the synthetic prediction of the unit post-treatment, which minimizes the error variance of synthetic prediction. Given the generative model the minimum variance counterfactual is unique, and comes with an associated error covariance matrix. We extend this basic formalism to include correlations of primary variable with other covariates of interest. Given the probabilistic description of generative model we can compare synthetic data prediction with real data to address the question of whether the treatment had a statistically significant impact. For this purpose we develop a hypothesis testing approach and evaluate the Bayes factor. We apply the method to the well studied example of California (CA) tobacco sales tax of 1988. We also perform a placebo analysis using control states to validate our methodology. Our hypothesis testing method suggests 5.8:1 odds in favor of CA tobacco sales tax having an impact on the tobacco sales, a value that is at least three times higher than any of the 38 control states.