 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChitta Baral
Towards Systematic Evaluation of Logical Reasoning Ability of Large Language Models
Apr 23, 2024
Recently developed large language models (LLMs) have been shown to perform remarkably well on a wide range of language understanding tasks. But, can they really "reason" over the natural language? This question has been receiving significant research attention and many reasoning skills such as commonsense, numerical, and qualitative have been studied. However, the crucial skill pertaining to 'logical reasoning' has remained underexplored. Existing work investigating this reasoning ability of LLMs has focused only on a couple of inference rules (such as modus ponens and modus tollens) of propositional and first-order logic. Addressing the above limitation, we comprehensively evaluate the logical reasoning ability of LLMs on 25 different reasoning patterns spanning over propositional, first-order, and non-monotonic logics. To enable systematic evaluation, we introduce LogicBench, a natural language question-answering dataset focusing on the use of a single inference rule. We conduct detailed analysis with a range of LLMs such as GPT-4, ChatGPT, Gemini, Llama-2, and Mistral using chain-of-thought prompting. Experimental results show that existing LLMs do not fare well on LogicBench; especially, they struggle with instances involving complex reasoning and negations. Furthermore, they sometimes overlook contextual information necessary for reasoning to arrive at the correct conclusion. We believe that our work and findings facilitate future research for evaluating and enhancing the logical reasoning ability of LLMs. Data and code are available at https://github.com/Mihir3009/LogicBench.
Insights into Alignment: Evaluating DPO and its Variants Across Multiple Tasks
Apr 23, 2024Large Language Models (LLMs) have demonstrated remarkable performance across a spectrum of tasks. Recently, Direct Preference Optimization (DPO) has emerged as an RL-free approach to optimize the policy model on human preferences. However, several limitations hinder the widespread adoption of this method. To address these shortcomings, various versions of DPO have been introduced. Yet, a comprehensive evaluation of these variants across diverse tasks is still lacking. In this study, we aim to bridge this gap by investigating the performance of alignment methods across three distinct scenarios: (1) keeping the Supervised Fine-Tuning (SFT) part, (2) skipping the SFT part, and (3) skipping the SFT part and utilizing an instruction-tuned model. Furthermore, we explore the impact of different training sizes on their performance. Our evaluation spans a range of tasks including dialogue systems, reasoning, mathematical problem-solving, question answering, truthfulness, and multi-task understanding, encompassing 13 benchmarks such as MT-Bench, Big Bench, and Open LLM Leaderboard. Key observations reveal that alignment methods achieve optimal performance with smaller training data subsets, exhibit limited effectiveness in reasoning tasks yet significantly impact mathematical problem-solving, and employing an instruction-tuned model notably influences truthfulness. We anticipate that our findings will catalyze further research aimed at developing more robust models to address alignment challenges.
On the Robustness of Language Guidance for Low-Level Vision Tasks: Findings from Depth Estimation
Apr 12, 2024Recent advances in monocular depth estimation have been made by incorporating natural language as additional guidance. Although yielding impressive results, the impact of the language prior, particularly in terms of generalization and robustness, remains unexplored. In this paper, we address this gap by quantifying the impact of this prior and introduce methods to benchmark its effectiveness across various settings. We generate "low-level" sentences that convey object-centric, three-dimensional spatial relationships, incorporate them as additional language priors and evaluate their downstream impact on depth estimation. Our key finding is that current language-guided depth estimators perform optimally only with scene-level descriptions and counter-intuitively fare worse with low level descriptions. Despite leveraging additional data, these methods are not robust to directed adversarial attacks and decline in performance with an increase in distribution shift. Finally, to provide a foundation for future research, we identify points of failures and offer insights to better understand these shortcomings. With an increasing number of methods using language for depth estimation, our findings highlight the opportunities and pitfalls that require careful consideration for effective deployment in real-world settings
Getting it Right: Improving Spatial Consistency in Text-to-Image Models
Apr 01, 2024One of the key shortcomings in current text-to-image (T2I) models is their inability to consistently generate images which faithfully follow the spatial relationships specified in the text prompt. In this paper, we offer a comprehensive investigation of this limitation, while also developing datasets and methods that achieve state-of-the-art performance. First, we find that current vision-language datasets do not represent spatial relationships well enough; to alleviate this bottleneck, we create SPRIGHT, the first spatially-focused, large scale dataset, by re-captioning 6 million images from 4 widely used vision datasets. Through a 3-fold evaluation and analysis pipeline, we find that SPRIGHT largely improves upon existing datasets in capturing spatial relationships. To demonstrate its efficacy, we leverage only ~0.25% of SPRIGHT and achieve a 22% improvement in generating spatially accurate images while also improving the FID and CMMD scores. Secondly, we find that training on images containing a large number of objects results in substantial improvements in spatial consistency. Notably, we attain state-of-the-art on T2I-CompBench with a spatial score of 0.2133, by fine-tuning on <500 images. Finally, through a set of controlled experiments and ablations, we document multiple findings that we believe will enhance the understanding of factors that affect spatial consistency in text-to-image models. We publicly release our dataset and model to foster further research in this area.
Lost in Translation? Translation Errors and Challenges for Fair Assessment of Text-to-Image Models on Multilingual Concepts
Mar 17, 2024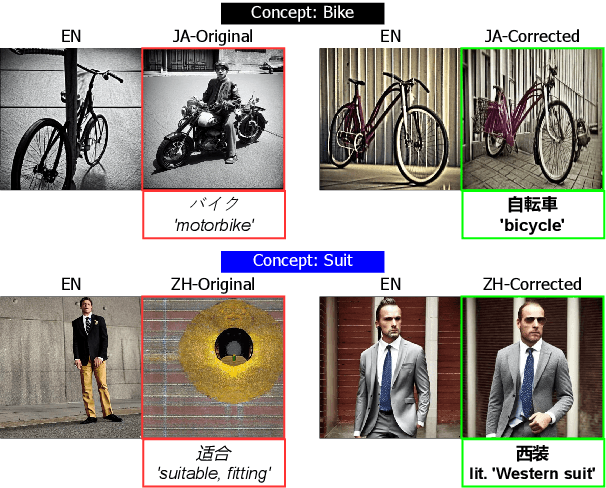

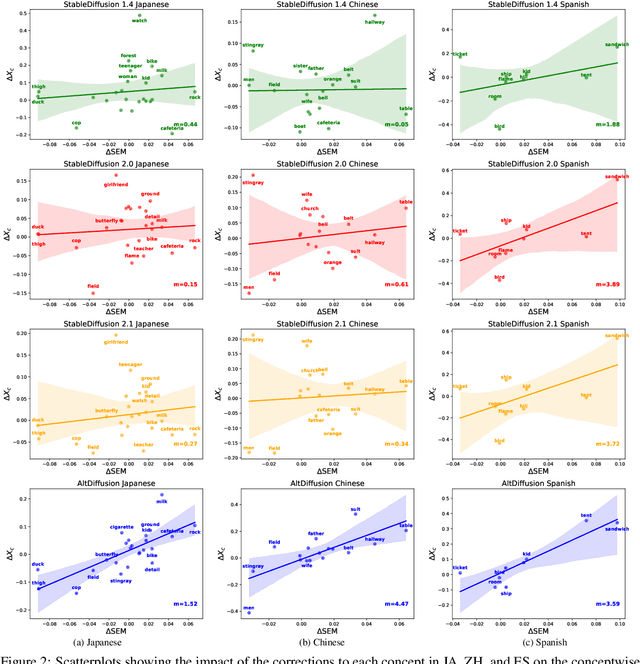

Benchmarks of the multilingual capabilities of text-to-image (T2I) models compare generated images prompted in a test language to an expected image distribution over a concept set. One such benchmark, "Conceptual Coverage Across Languages" (CoCo-CroLa), assesses the tangible noun inventory of T2I models by prompting them to generate pictures from a concept list translated to seven languages and comparing the output image populations. Unfortunately, we find that this benchmark contains translation errors of varying severity in Spanish, Japanese, and Chinese. We provide corrections for these errors and analyze how impactful they are on the utility and validity of CoCo-CroLa as a benchmark. We reassess multiple baseline T2I models with the revisions, compare the outputs elicited under the new translations to those conditioned on the old, and show that a correction's impactfulness on the image-domain benchmark results can be predicted in the text domain with similarity scores. Our findings will guide the future development of T2I multilinguality metrics by providing analytical tools for practical translation decisions.
Jailbreaking Proprietary Large Language Models using Word Substitution Cipher
Feb 16, 2024Large Language Models (LLMs) are aligned to moral and ethical guidelines but remain susceptible to creative prompts called Jailbreak that can bypass the alignment process. However, most jailbreaking prompts contain harmful questions in the natural language (mainly English), which can be detected by the LLM themselves. In this paper, we present jailbreaking prompts encoded using cryptographic techniques. We first present a pilot study on the state-of-the-art LLM, GPT-4, in decoding several safe sentences that have been encrypted using various cryptographic techniques and find that a straightforward word substitution cipher can be decoded most effectively. Motivated by this result, we use this encoding technique for writing jailbreaking prompts. We present a mapping of unsafe words with safe words and ask the unsafe question using these mapped words. Experimental results show an attack success rate (up to 59.42%) of our proposed jailbreaking approach on state-of-the-art proprietary models including ChatGPT, GPT-4, and Gemini-Pro. Additionally, we discuss the over-defensiveness of these models. We believe that our work will encourage further research in making these LLMs more robust while maintaining their decoding capabilities.
$λ$-ECLIPSE: Multi-Concept Personalized Text-to-Image Diffusion Models by Leveraging CLIP Latent Space
Feb 07, 2024Despite the recent advances in personalized text-to-image (P-T2I) generative models, subject-driven T2I remains challenging. The primary bottlenecks include 1) Intensive training resource requirements, 2) Hyper-parameter sensitivity leading to inconsistent outputs, and 3) Balancing the intricacies of novel visual concept and composition alignment. We start by re-iterating the core philosophy of T2I diffusion models to address the above limitations. Predominantly, contemporary subject-driven T2I approaches hinge on Latent Diffusion Models (LDMs), which facilitate T2I mapping through cross-attention layers. While LDMs offer distinct advantages, P-T2I methods' reliance on the latent space of these diffusion models significantly escalates resource demands, leading to inconsistent results and necessitating numerous iterations for a single desired image. Recently, ECLIPSE has demonstrated a more resource-efficient pathway for training UnCLIP-based T2I models, circumventing the need for diffusion text-to-image priors. Building on this, we introduce $\lambda$-ECLIPSE. Our method illustrates that effective P-T2I does not necessarily depend on the latent space of diffusion models. $\lambda$-ECLIPSE achieves single, multi-subject, and edge-guided T2I personalization with just 34M parameters and is trained on a mere 74 GPU hours using 1.6M image-text interleaved data. Through extensive experiments, we also establish that $\lambda$-ECLIPSE surpasses existing baselines in composition alignment while preserving concept alignment performance, even with significantly lower resource utilization.
The Art of Defending: A Systematic Evaluation and Analysis of LLM Defense Strategies on Safety and Over-Defensiveness
Dec 30, 2023As Large Language Models (LLMs) play an increasingly pivotal role in natural language processing applications, their safety concerns become critical areas of NLP research. This paper presents Safety and Over-Defensiveness Evaluation (SODE) benchmark: a collection of diverse safe and unsafe prompts with carefully designed evaluation methods that facilitate systematic evaluation, comparison, and analysis over 'safety' and 'over-defensiveness.' With SODE, we study a variety of LLM defense strategies over multiple state-of-the-art LLMs, which reveals several interesting and important findings, such as (a) the widely popular 'self-checking' techniques indeed improve the safety against unsafe inputs, but this comes at the cost of extreme over-defensiveness on the safe inputs, (b) providing a safety instruction along with in-context exemplars (of both safe and unsafe inputs) consistently improves safety and also mitigates undue over-defensiveness of the models, (c) providing contextual knowledge easily breaks the safety guardrails and makes the models more vulnerable to generating unsafe responses. Overall, our work reveals numerous such critical findings that we believe will pave the way and facilitate further research in improving the safety of LLMs.
ECLIPSE: A Resource-Efficient Text-to-Image Prior for Image Generations
Dec 07, 2023Text-to-image (T2I) diffusion models, notably the unCLIP models (e.g., DALL-E-2), achieve state-of-the-art (SOTA) performance on various compositional T2I benchmarks, at the cost of significant computational resources. The unCLIP stack comprises T2I prior and diffusion image decoder. The T2I prior model alone adds a billion parameters compared to the Latent Diffusion Models, which increases the computational and high-quality data requirements. We introduce ECLIPSE, a novel contrastive learning method that is both parameter and data-efficient. ECLIPSE leverages pre-trained vision-language models (e.g., CLIP) to distill the knowledge into the prior model. We demonstrate that the ECLIPSE trained prior, with only 3.3% of the parameters and trained on a mere 2.8% of the data, surpasses the baseline T2I priors with an average of 71.6% preference score under resource-limited setting. It also attains performance on par with SOTA big models, achieving an average of 63.36% preference score in terms of the ability to follow the text compositions. Extensive experiments on two unCLIP diffusion image decoders, Karlo and Kandinsky, affirm that ECLIPSE priors consistently deliver high performance while significantly reducing resource dependency.
LongBoX: Evaluating Transformers on Long-Sequence Clinical Tasks
Nov 16, 2023Many large language models (LLMs) for medicine have largely been evaluated on short texts, and their ability to handle longer sequences such as a complete electronic health record (EHR) has not been systematically explored. Assessing these models on long sequences is crucial since prior work in the general domain has demonstrated performance degradation of LLMs on longer texts. Motivated by this, we introduce LongBoX, a collection of seven medical datasets in text-to-text format, designed to investigate model performance on long sequences. Preliminary experiments reveal that both medical LLMs (e.g., BioGPT) and strong general domain LLMs (e.g., FLAN-T5) struggle on this benchmark. We further evaluate two techniques designed for long-sequence handling: (i) local-global attention, and (ii) Fusion-in-Decoder (FiD). Our results demonstrate mixed results with long-sequence handling - while scores on some datasets increase, there is substantial room for improvement. We hope that LongBoX facilitates the development of more effective long-sequence techniques for the medical domain. Data and source code are available at https://github.com/Mihir3009/LongBoX.