 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChris Russell
Kick Back & Relax++: Scaling Beyond Ground-Truth Depth with SlowTV & CribsTV
Mar 03, 2024

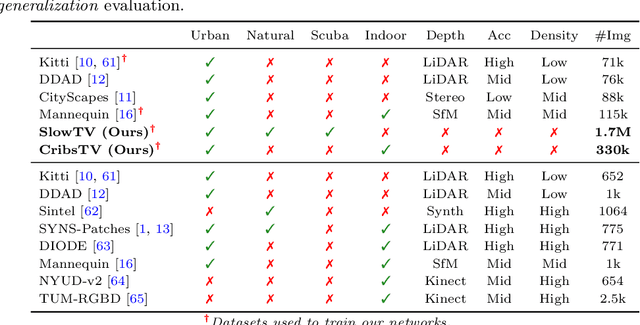

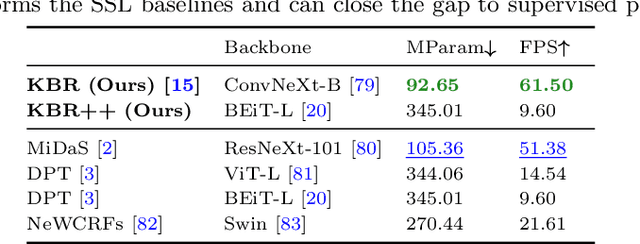
Self-supervised learning is the key to unlocking generic computer vision systems. By eliminating the reliance on ground-truth annotations, it allows scaling to much larger data quantities. Unfortunately, self-supervised monocular depth estimation (SS-MDE) has been limited by the absence of diverse training data. Existing datasets have focused exclusively on urban driving in densely populated cities, resulting in models that fail to generalize beyond this domain. To address these limitations, this paper proposes two novel datasets: SlowTV and CribsTV. These are large-scale datasets curated from publicly available YouTube videos, containing a total of 2M training frames. They offer an incredibly diverse set of environments, ranging from snowy forests to coastal roads, luxury mansions and even underwater coral reefs. We leverage these datasets to tackle the challenging task of zero-shot generalization, outperforming every existing SS-MDE approach and even some state-of-the-art supervised methods. The generalization capabilities of our models are further enhanced by a range of components and contributions: 1) learning the camera intrinsics, 2) a stronger augmentation regime targeting aspect ratio changes, 3) support frame randomization, 4) flexible motion estimation, 5) a modern transformer-based architecture. We demonstrate the effectiveness of each component in extensive ablation experiments. To facilitate the development of future research, we make the datasets, code and pretrained models available to the public at https://github.com/jspenmar/slowtv_monodepth.
Evaluating the Fairness of Discriminative Foundation Models in Computer Vision
Oct 18, 2023We propose a novel taxonomy for bias evaluation of discriminative foundation models, such as Contrastive Language-Pretraining (CLIP), that are used for labeling tasks. We then systematically evaluate existing methods for mitigating bias in these models with respect to our taxonomy. Specifically, we evaluate OpenAI's CLIP and OpenCLIP models for key applications, such as zero-shot classification, image retrieval and image captioning. We categorize desired behaviors based around three axes: (i) if the task concerns humans; (ii) how subjective the task is (i.e., how likely it is that people from a diverse range of backgrounds would agree on a labeling); and (iii) the intended purpose of the task and if fairness is better served by impartiality (i.e., making decisions independent of the protected attributes) or representation (i.e., making decisions to maximize diversity). Finally, we provide quantitative fairness evaluations for both binary-valued and multi-valued protected attributes over ten diverse datasets. We find that fair PCA, a post-processing method for fair representations, works very well for debiasing in most of the aforementioned tasks while incurring only minor loss of performance. However, different debiasing approaches vary in their effectiveness depending on the task. Hence, one should choose the debiasing approach depending on the specific use case.
Kick Back & Relax: Learning to Reconstruct the World by Watching SlowTV
Jul 20, 2023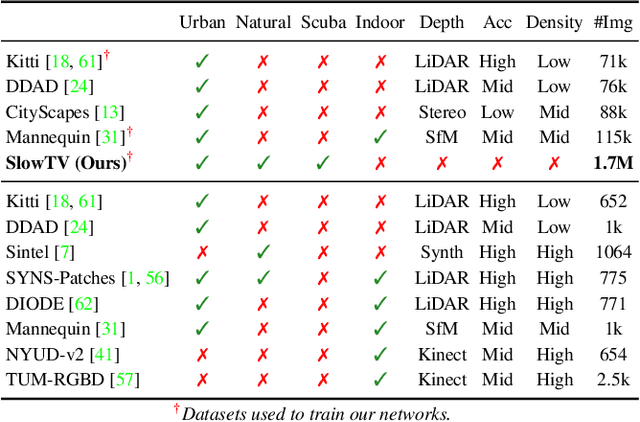

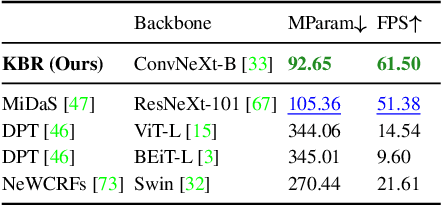
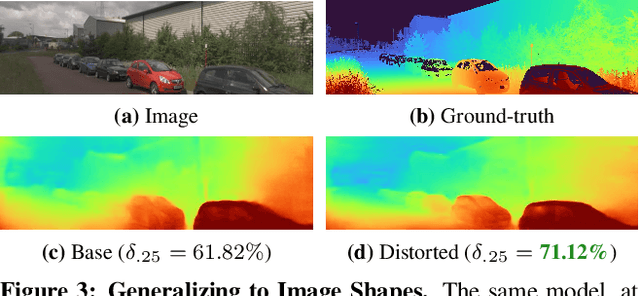
Self-supervised monocular depth estimation (SS-MDE) has the potential to scale to vast quantities of data. Unfortunately, existing approaches limit themselves to the automotive domain, resulting in models incapable of generalizing to complex environments such as natural or indoor settings. To address this, we propose a large-scale SlowTV dataset curated from YouTube, containing an order of magnitude more data than existing automotive datasets. SlowTV contains 1.7M images from a rich diversity of environments, such as worldwide seasonal hiking, scenic driving and scuba diving. Using this dataset, we train an SS-MDE model that provides zero-shot generalization to a large collection of indoor/outdoor datasets. The resulting model outperforms all existing SSL approaches and closes the gap on supervised SoTA, despite using a more efficient architecture. We additionally introduce a collection of best-practices to further maximize performance and zero-shot generalization. This includes 1) aspect ratio augmentation, 2) camera intrinsic estimation, 3) support frame randomization and 4) flexible motion estimation. Code is available at https://github.com/jspenmar/slowtv_monodepth.
Learning Adaptive Neighborhoods for Graph Neural Networks
Jul 18, 2023

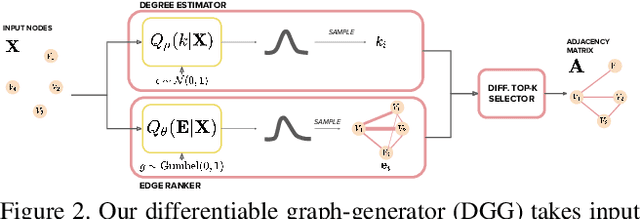
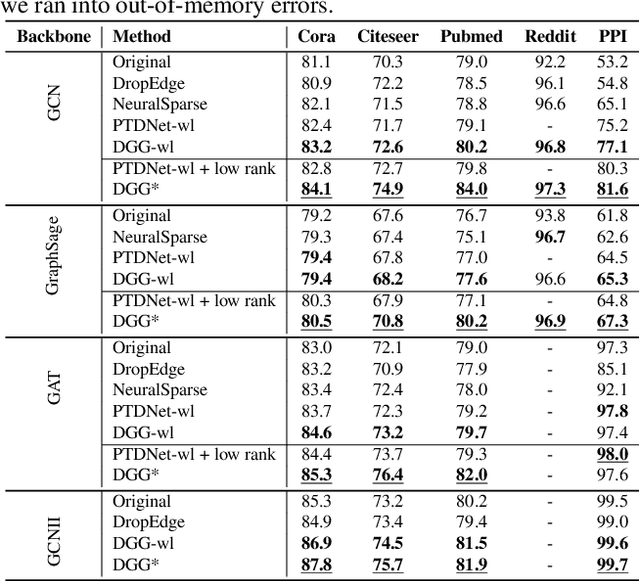
Graph convolutional networks (GCNs) enable end-to-end learning on graph structured data. However, many works assume a given graph structure. When the input graph is noisy or unavailable, one approach is to construct or learn a latent graph structure. These methods typically fix the choice of node degree for the entire graph, which is suboptimal. Instead, we propose a novel end-to-end differentiable graph generator which builds graph topologies where each node selects both its neighborhood and its size. Our module can be readily integrated into existing pipelines involving graph convolution operations, replacing the predetermined or existing adjacency matrix with one that is learned, and optimized, as part of the general objective. As such it is applicable to any GCN. We integrate our module into trajectory prediction, point cloud classification and node classification pipelines resulting in improved accuracy over other structure-learning methods across a wide range of datasets and GCN backbones.
The Second Monocular Depth Estimation Challenge
Apr 26, 2023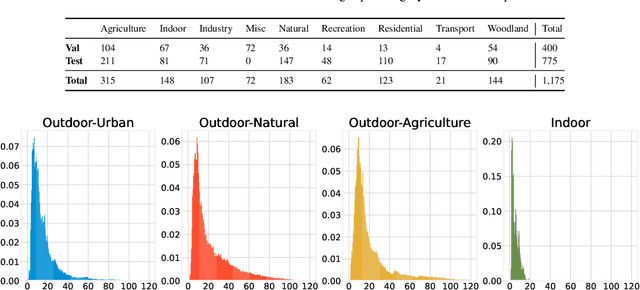
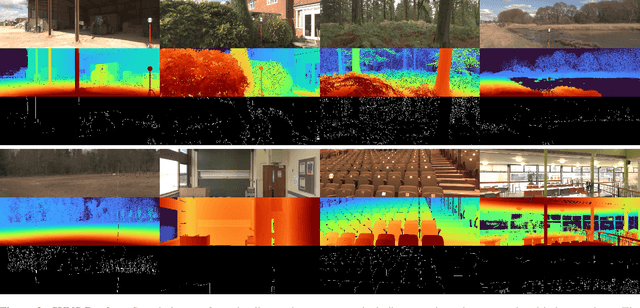

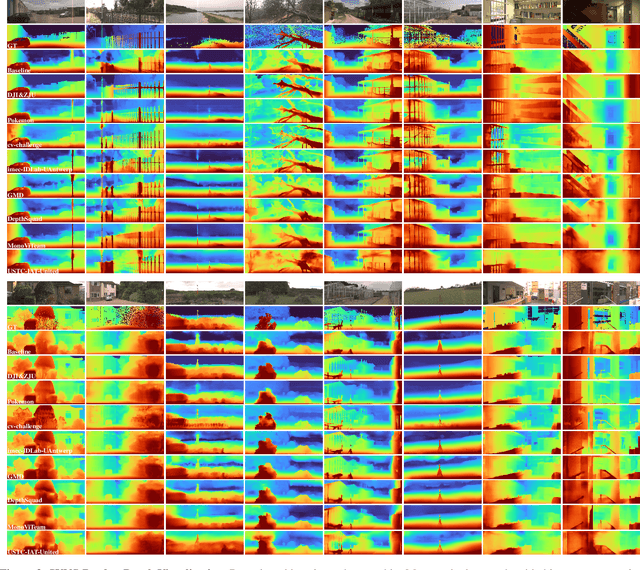
This paper discusses the results for the second edition of the Monocular Depth Estimation Challenge (MDEC). This edition was open to methods using any form of supervision, including fully-supervised, self-supervised, multi-task or proxy depth. The challenge was based around the SYNS-Patches dataset, which features a wide diversity of environments with high-quality dense ground-truth. This includes complex natural environments, e.g. forests or fields, which are greatly underrepresented in current benchmarks. The challenge received eight unique submissions that outperformed the provided SotA baseline on any of the pointcloud- or image-based metrics. The top supervised submission improved relative F-Score by 27.62%, while the top self-supervised improved it by 16.61%. Supervised submissions generally leveraged large collections of datasets to improve data diversity. Self-supervised submissions instead updated the network architecture and pretrained backbones. These results represent a significant progress in the field, while highlighting avenues for future research, such as reducing interpolation artifacts at depth boundaries, improving self-supervised indoor performance and overall natural image accuracy.
A data augmentation perspective on diffusion models and retrieval
Apr 20, 2023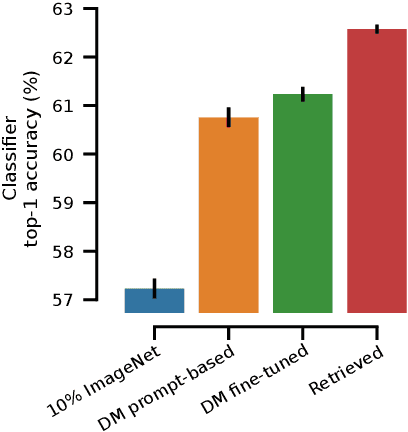
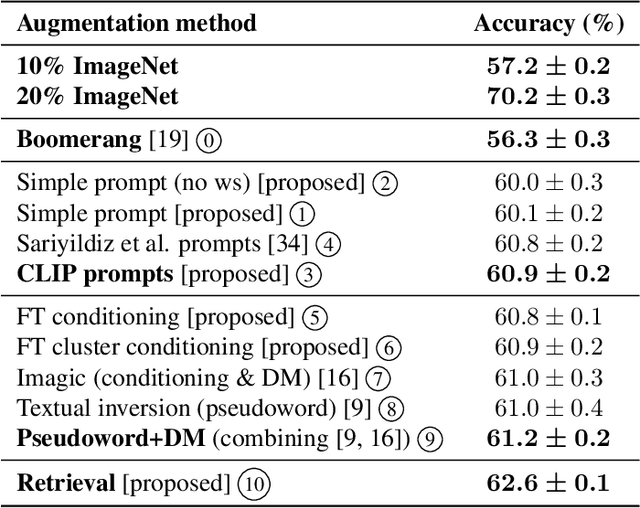
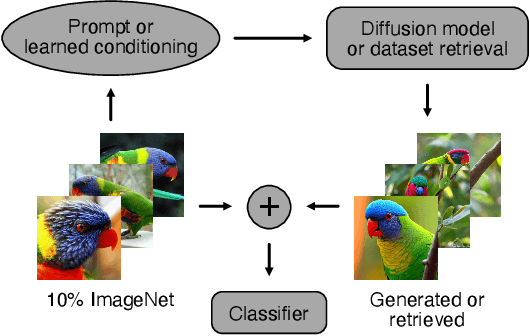
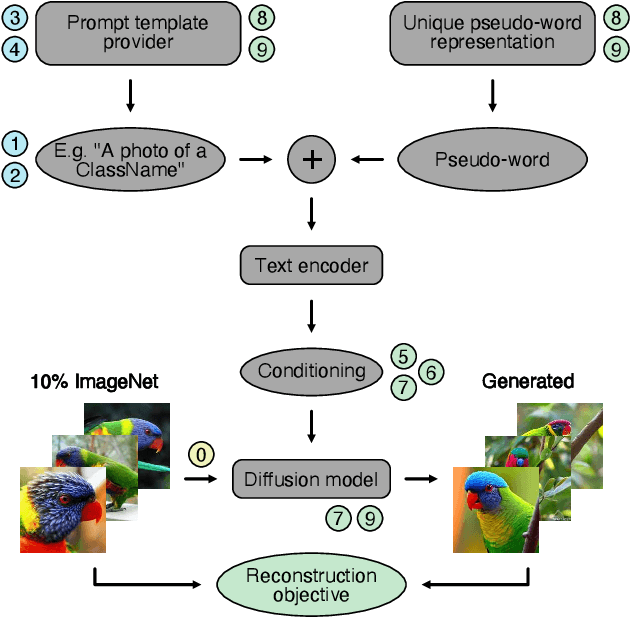
Diffusion models excel at generating photorealistic images from text-queries. Naturally, many approaches have been proposed to use these generative abilities to augment training datasets for downstream tasks, such as classification. However, diffusion models are themselves trained on large noisily supervised, but nonetheless, annotated datasets. It is an open question whether the generalization capabilities of diffusion models beyond using the additional data of the pre-training process for augmentation lead to improved downstream performance. We perform a systematic evaluation of existing methods to generate images from diffusion models and study new extensions to assess their benefit for data augmentation. While we find that personalizing diffusion models towards the target data outperforms simpler prompting strategies, we also show that using the training data of the diffusion model alone, via a simple nearest neighbor retrieval procedure, leads to even stronger downstream performance. Overall, our study probes the limitations of diffusion models for data augmentation but also highlights its potential in generating new training data to improve performance on simple downstream vision tasks.
Novel View Synthesis of Humans using Differentiable Rendering
Mar 28, 2023


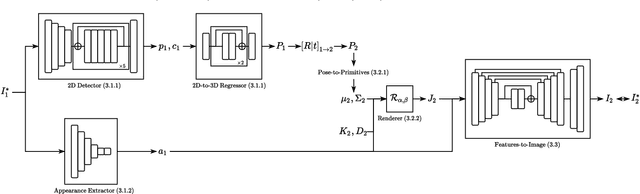
We present a new approach for synthesizing novel views of people in new poses. Our novel differentiable renderer enables the synthesis of highly realistic images from any viewpoint. Rather than operating over mesh-based structures, our renderer makes use of diffuse Gaussian primitives that directly represent the underlying skeletal structure of a human. Rendering these primitives gives results in a high-dimensional latent image, which is then transformed into an RGB image by a decoder network. The formulation gives rise to a fully differentiable framework that can be trained end-to-end. We demonstrate the effectiveness of our approach to image reconstruction on both the Human3.6M and Panoptic Studio datasets. We show how our approach can be used for motion transfer between individuals; novel view synthesis of individuals captured from just a single camera; to synthesize individuals from any virtual viewpoint; and to re-render people in novel poses. Code and video results are available at https://github.com/GuillaumeRochette/HumanViewSynthesis.
Efficient fair PCA for fair representation learning
Feb 26, 2023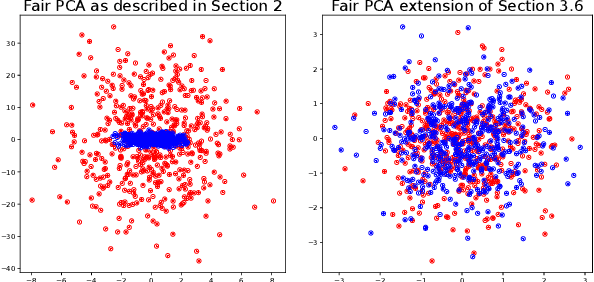
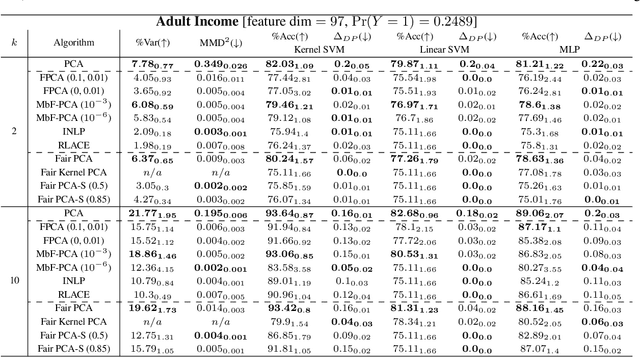
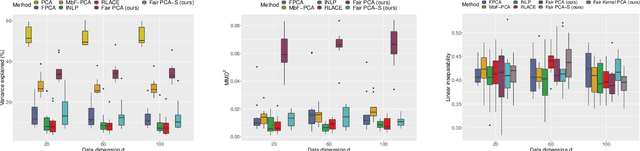
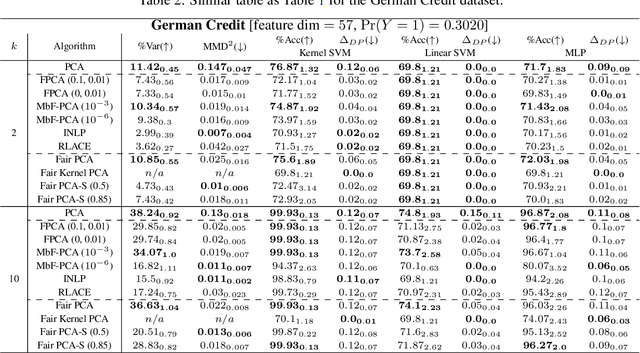
We revisit the problem of fair principal component analysis (PCA), where the goal is to learn the best low-rank linear approximation of the data that obfuscates demographic information. We propose a conceptually simple approach that allows for an analytic solution similar to standard PCA and can be kernelized. Our methods have the same complexity as standard PCA, or kernel PCA, and run much faster than existing methods for fair PCA based on semidefinite programming or manifold optimization, while achieving similar results.
The Unfairness of Fair Machine Learning: Levelling down and strict egalitarianism by default
Feb 20, 2023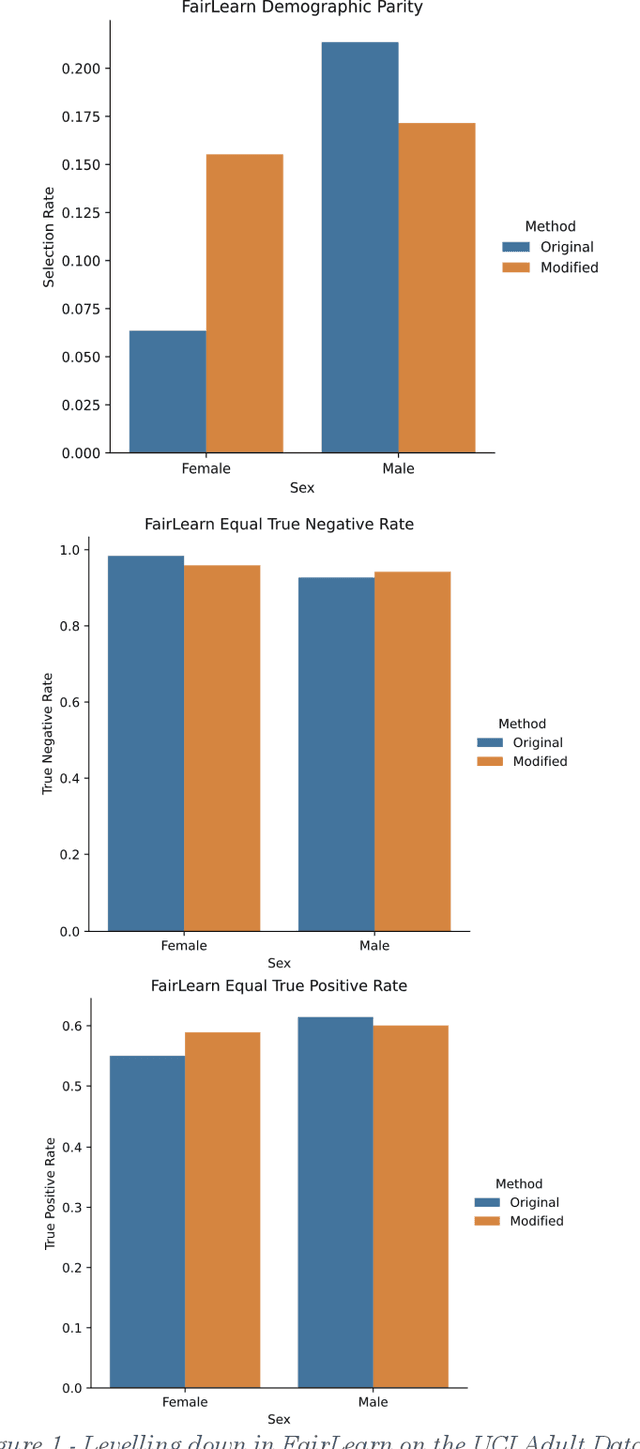
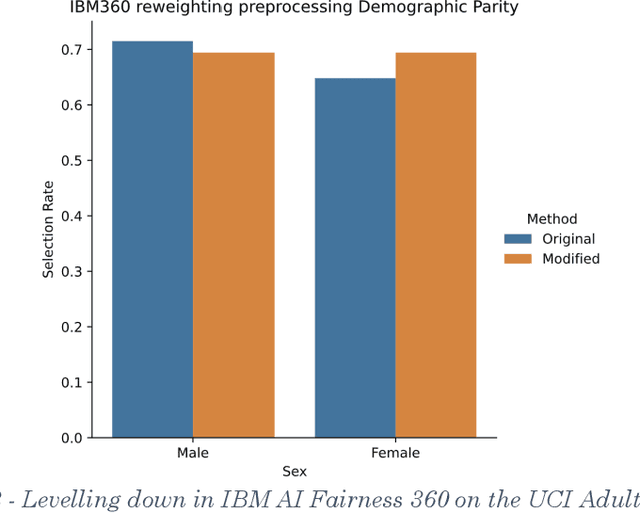
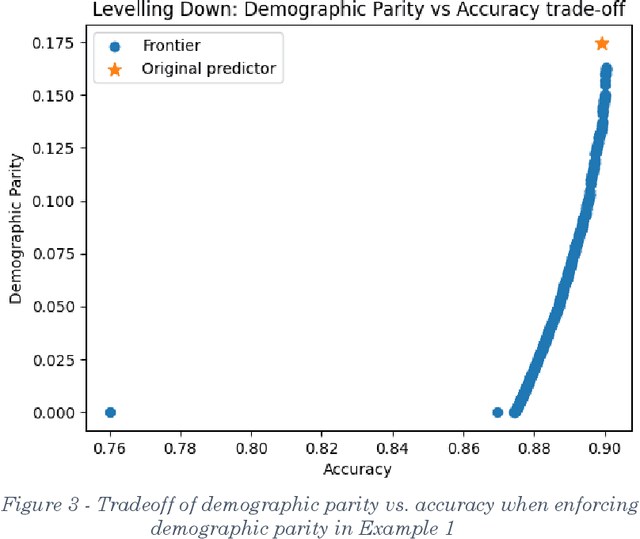
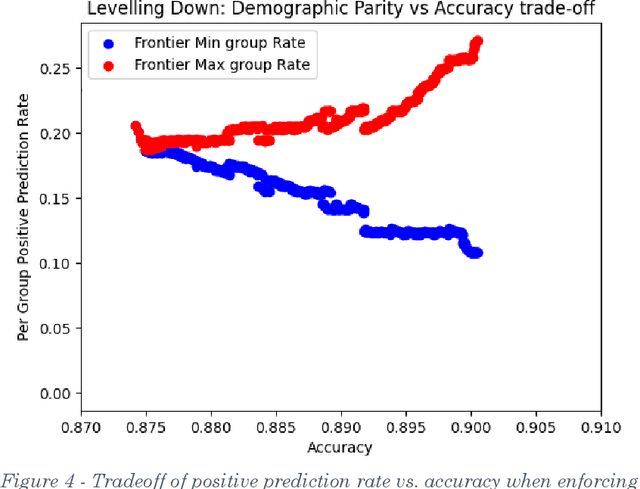
In recent years fairness in machine learning (ML) has emerged as a highly active area of research and development. Most define fairness in simple terms, where fairness means reducing gaps in performance or outcomes between demographic groups while preserving as much of the accuracy of the original system as possible. This oversimplification of equality through fairness measures is troubling. Many current fairness measures suffer from both fairness and performance degradation, or "levelling down," where fairness is achieved by making every group worse off, or by bringing better performing groups down to the level of the worst off. When fairness can only be achieved by making everyone worse off in material or relational terms through injuries of stigma, loss of solidarity, unequal concern, and missed opportunities for substantive equality, something would appear to have gone wrong in translating the vague concept of 'fairness' into practice. This paper examines the causes and prevalence of levelling down across fairML, and explore possible justifications and criticisms based on philosophical and legal theories of equality and distributive justice, as well as equality law jurisprudence. We find that fairML does not currently engage in the type of measurement, reporting, or analysis necessary to justify levelling down in practice. We propose a first step towards substantive equality in fairML: "levelling up" systems by design through enforcement of minimum acceptable harm thresholds, or "minimum rate constraints," as fairness constraints. We likewise propose an alternative harms-based framework to counter the oversimplified egalitarian framing currently dominant in the field and push future discussion more towards substantive equality opportunities and away from strict egalitarianism by default. N.B. Shortened abstract, see paper for full abstract.
Causal Triplet: An Open Challenge for Intervention-centric Causal Representation Learning
Jan 12, 2023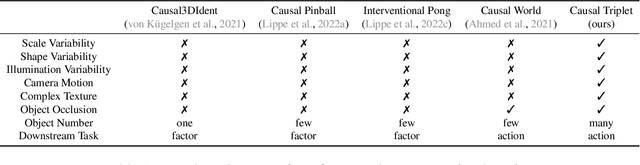
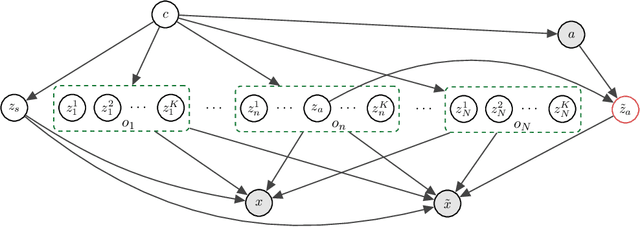


Recent years have seen a surge of interest in learning high-level causal representations from low-level image pairs under interventions. Yet, existing efforts are largely limited to simple synthetic settings that are far away from real-world problems. In this paper, we present Causal Triplet, a causal representation learning benchmark featuring not only visually more complex scenes, but also two crucial desiderata commonly overlooked in previous works: (i) an actionable counterfactual setting, where only certain object-level variables allow for counterfactual observations whereas others do not; (ii) an interventional downstream task with an emphasis on out-of-distribution robustness from the independent causal mechanisms principle. Through extensive experiments, we find that models built with the knowledge of disentangled or object-centric representations significantly outperform their distributed counterparts. However, recent causal representation learning methods still struggle to identify such latent structures, indicating substantial challenges and opportunities for future work. Our code and datasets will be available at https://sites.google.com/view/causaltriplet.