 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChristopher Mutschler
Guided-SPSA: Simultaneous Perturbation Stochastic Approximation assisted by the Parameter Shift Rule
Apr 24, 2024
The study of variational quantum algorithms (VQCs) has received significant attention from the quantum computing community in recent years. These hybrid algorithms, utilizing both classical and quantum components, are well-suited for noisy intermediate-scale quantum devices. Though estimating exact gradients using the parameter-shift rule to optimize the VQCs is realizable in NISQ devices, they do not scale well for larger problem sizes. The computational complexity, in terms of the number of circuit evaluations required for gradient estimation by the parameter-shift rule, scales linearly with the number of parameters in VQCs. On the other hand, techniques that approximate the gradients of the VQCs, such as the simultaneous perturbation stochastic approximation (SPSA), do not scale with the number of parameters but struggle with instability and often attain suboptimal solutions. In this work, we introduce a novel gradient estimation approach called Guided-SPSA, which meaningfully combines the parameter-shift rule and SPSA-based gradient approximation. The Guided-SPSA results in a 15% to 25% reduction in the number of circuit evaluations required during training for a similar or better optimality of the solution found compared to the parameter-shift rule. The Guided-SPSA outperforms standard SPSA in all scenarios and outperforms the parameter-shift rule in scenarios such as suboptimal initialization of the parameters. We demonstrate numerically the performance of Guided-SPSA on different paradigms of quantum machine learning, such as regression, classification, and reinforcement learning.
Warm-Start Variational Quantum Policy Iteration
Apr 16, 2024Reinforcement learning is a powerful framework aiming to determine optimal behavior in highly complex decision-making scenarios. This objective can be achieved using policy iteration, which requires to solve a typically large linear system of equations. We propose the variational quantum policy iteration (VarQPI) algorithm, realizing this step with a NISQ-compatible quantum-enhanced subroutine. Its scalability is supported by an analysis of the structure of generic reinforcement learning environments, laying the foundation for potential quantum advantage with utility-scale quantum computers. Furthermore, we introduce the warm-start initialization variant (WS-VarQPI) that significantly reduces resource overhead. The algorithm solves a large FrozenLake environment with an underlying 256x256-dimensional linear system, indicating its practical robustness.
Comprehensive Library of Variational LSE Solvers
Apr 15, 2024Linear systems of equations can be found in various mathematical domains, as well as in the field of machine learning. By employing noisy intermediate-scale quantum devices, variational solvers promise to accelerate finding solutions for large systems. Although there is a wealth of theoretical research on these algorithms, only fragmentary implementations exist. To fill this gap, we have developed the variational-lse-solver framework, which realizes existing approaches in literature, and introduces several enhancements. The user-friendly interface is designed for researchers that work at the abstraction level of identifying and developing end-to-end applications.
Qiskit-Torch-Module: Fast Prototyping of Quantum Neural Networks
Apr 09, 2024Quantum computer simulation software is an integral tool for the research efforts in the quantum computing community. An important aspect is the efficiency of respective frameworks, especially for training variational quantum algorithms. Focusing on the widely used Qiskit software environment, we develop the qiskit-torch-module. It improves runtime performance by two orders of magnitude over comparable libraries, while facilitating low-overhead integration with existing codebases. Moreover, the framework provides advanced tools for integrating quantum neural networks with PyTorch. The pipeline is tailored for single-machine compute systems, which constitute a widely employed setup in day-to-day research efforts.
Few-Shot Learning with Uncertainty-based Quadruplet Selection for Interference Classification in GNSS Data
Feb 09, 2024Jamming devices pose a significant threat by disrupting signals from the global navigation satellite system (GNSS), compromising the robustness of accurate positioning. Detecting anomalies in frequency snapshots is crucial to counteract these interferences effectively. The ability to adapt to diverse, unseen interference characteristics is essential for ensuring the reliability of GNSS in real-world applications. In this paper, we propose a few-shot learning (FSL) approach to adapt to new interference classes. Our method employs quadruplet selection for the model to learn representations using various positive and negative interference classes. Furthermore, our quadruplet variant selects pairs based on the aleatoric and epistemic uncertainty to differentiate between similar classes. We recorded a dataset at a motorway with eight interference classes on which our FSL method with quadruplet loss outperforms other FSL techniques in jammer classification accuracy with 97.66%.
Velocity-Based Channel Charting with Spatial Distribution Map Matching
Nov 14, 2023Fingerprint-based localization improves the positioning performance in challenging, non-line-of-sight (NLoS) dominated indoor environments. However, fingerprinting models require an expensive life-cycle management including recording and labeling of radio signals for the initial training and regularly at environmental changes. Alternatively, channel-charting avoids this labeling effort as it implicitly associates relative coordinates to the recorded radio signals. Then, with reference real-world coordinates (positions) we can use such charts for positioning tasks. However, current channel-charting approaches lag behind fingerprinting in their positioning accuracy and still require reference samples for localization, regular data recording and labeling to keep the models up to date. Hence, we propose a novel framework that does not require reference positions. We only require information from velocity information, e.g., from pedestrian dead reckoning or odometry to model the channel charts, and topological map information, e.g., a building floor plan, to transform the channel charts into real coordinates. We evaluate our approach on two different real-world datasets using 5G and distributed single-input/multiple-output system (SIMO) radio systems. Our experiments show that even with noisy velocity estimates and coarse map information, we achieve similar position accuracies
Reinforcement Learning for Node Selection in Branch-and-Bound
Sep 29, 2023



A big challenge in branch and bound lies in identifying the optimal node within the search tree from which to proceed. Current state-of-the-art selectors utilize either hand-crafted ensembles that automatically switch between naive sub-node selectors, or learned node selectors that rely on individual node data. We propose a novel bi-simulation technique that uses reinforcement learning (RL) while considering the entire tree state, rather than just isolated nodes. To achieve this, we train a graph neural network that produces a probability distribution based on the path from the model's root to its ``to-be-selected'' leaves. Modelling node-selection as a probability distribution allows us to train the model using state-of-the-art RL techniques that capture both intrinsic node-quality and node-evaluation costs. Our method induces a high quality node selection policy on a set of varied and complex problem sets, despite only being trained on specially designed, synthetic TSP instances. Experiments on several benchmarks show significant improvements in optimality gap reductions and per-node efficiency under strict time constraints.
C-MCTS: Safe Planning with Monte Carlo Tree Search
May 25, 2023



Many real-world decision-making tasks, such as safety-critical scenarios, cannot be fully described in a single-objective setting using the Markov Decision Process (MDP) framework, as they include hard constraints. These can instead be modeled with additional cost functions within the Constrained Markov Decision Process (CMDP) framework. Even though CMDPs have been extensively studied in the Reinforcement Learning literature, little attention has been given to sampling-based planning algorithms such as MCTS for solving them. Previous approaches use Monte Carlo cost estimates to avoid constraint violations. However, these suffer from high variance which results in conservative performance with respect to costs. We propose Constrained MCTS (C-MCTS), an algorithm that estimates cost using a safety critic. The safety critic training is based on Temporal Difference learning in an offline phase prior to agent deployment. This critic limits the exploration of the search tree and removes unsafe trajectories within MCTS during deployment. C-MCTS satisfies cost constraints but operates closer to the constraint boundary, achieving higher rewards compared to previous work. As a nice byproduct, the planner is more efficient requiring fewer planning steps. Most importantly, we show that under model mismatch between the planner and the real world, our approach is less susceptible to cost violations than previous work.
Augmented Random Search for Multi-Objective Bayesian Optimization of Neural Networks
May 23, 2023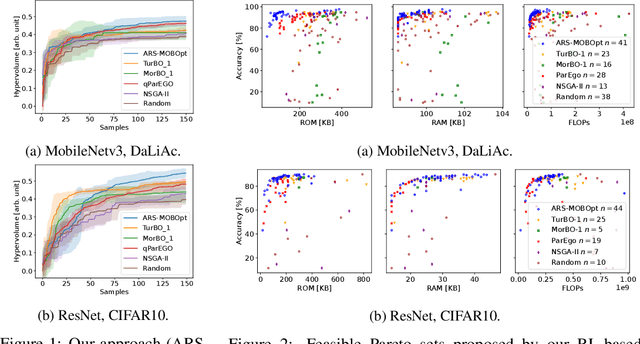
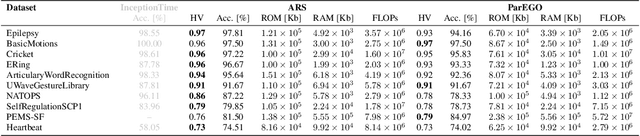

Deploying Deep Neural Networks (DNNs) on tiny devices is a common trend to process the increasing amount of sensor data being generated. Multi-objective optimization approaches can be used to compress DNNs by applying network pruning and weight quantization to minimize the memory footprint (RAM), the number of parameters (ROM) and the number of floating point operations (FLOPs) while maintaining the predictive accuracy. In this paper, we show that existing multi-objective Bayesian optimization (MOBOpt) approaches can fall short in finding optimal candidates on the Pareto front and propose a novel solver based on an ensemble of competing parametric policies trained using an Augmented Random Search Reinforcement Learning (RL) agent. Our methodology aims at finding feasible tradeoffs between a DNN's predictive accuracy, memory consumption on a given target system, and computational complexity. Our experiments show that we outperform existing MOBOpt approaches consistently on different data sets and architectures such as ResNet-18 and MobileNetV3.
Batch Quantum Reinforcement Learning
Apr 27, 2023



Training DRL agents is often a time-consuming process as a large number of samples and environment interactions is required. This effect is even amplified in the case of Batch RL, where the agent is trained without environment interactions solely based on a set of previously collected data. Novel approaches based on quantum computing suggest an advantage compared to classical approaches in terms of sample efficiency. To investigate this advantage, we propose a batch RL algorithm leveraging VQC as function approximators in the discrete BCQ algorithm. Additionally, we present a novel data re-uploading scheme based on cyclically shifting the input variables' order in the data encoding layers. We show the efficiency of our algorithm on the OpenAI CartPole environment and compare its performance to classical neural network-based discrete BCQ.