 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChuanjun Ji
$R^3$-NL2GQL: A Hybrid Models Approach for for Accuracy Enhancing and Hallucinations Mitigation
Nov 03, 2023
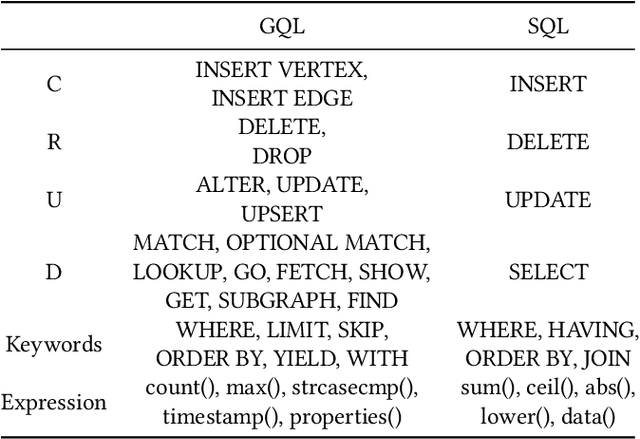
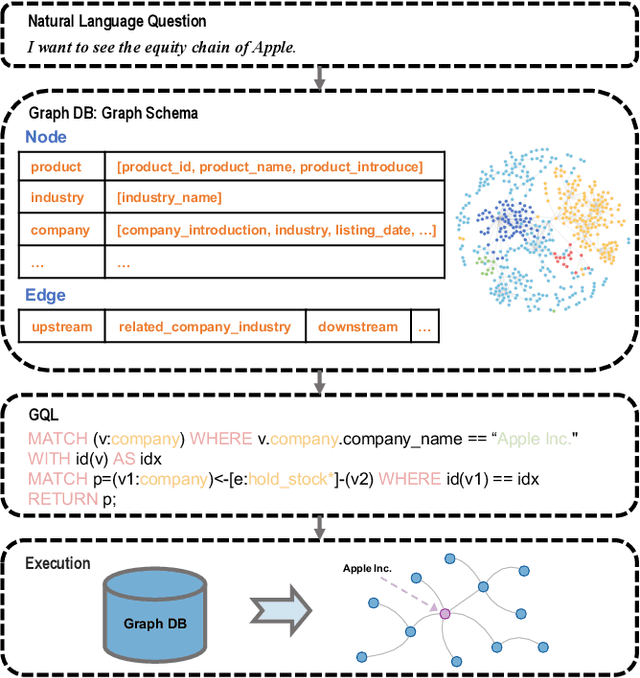
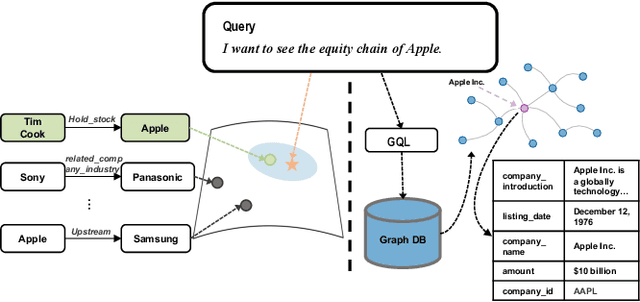
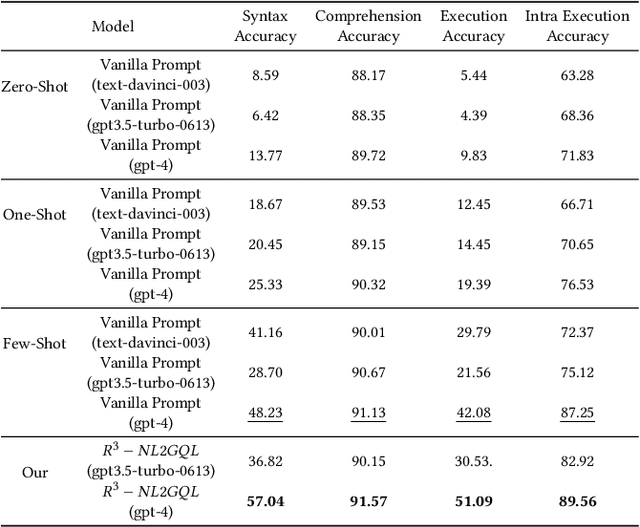
While current NL2SQL tasks constructed using Foundation Models have achieved commendable results, their direct application to Natural Language to Graph Query Language (NL2GQL) tasks poses challenges due to the significant differences between GQL and SQL expressions, as well as the numerous types of GQL. Our extensive experiments reveal that in NL2GQL tasks, larger Foundation Models demonstrate superior cross-schema generalization abilities, while smaller Foundation Models struggle to improve their GQL generation capabilities through fine-tuning. However, after fine-tuning, smaller models exhibit better intent comprehension and higher grammatical accuracy. Diverging from rule-based and slot-filling techniques, we introduce R3-NL2GQL, which employs both smaller and larger Foundation Models as reranker, rewriter and refiner. The approach harnesses the comprehension ability of smaller models for information reranker and rewriter, and the exceptional generalization and generation capabilities of larger models to transform input natural language queries and code structure schema into any form of GQLs. Recognizing the lack of established datasets in this nascent domain, we have created a bilingual dataset derived from graph database documentation and some open-source Knowledge Graphs (KGs). We tested our approach on this dataset and the experimental results showed that delivers promising performance and robustness.Our code and dataset is available at https://github.com/zhiqix/NL2GQL
Adaptive Ordered Information Extraction with Deep Reinforcement Learning
Jun 19, 2023



Information extraction (IE) has been studied extensively. The existing methods always follow a fixed extraction order for complex IE tasks with multiple elements to be extracted in one instance such as event extraction. However, we conduct experiments on several complex IE datasets and observe that different extraction orders can significantly affect the extraction results for a great portion of instances, and the ratio of sentences that are sensitive to extraction orders increases dramatically with the complexity of the IE task. Therefore, this paper proposes a novel adaptive ordered IE paradigm to find the optimal element extraction order for different instances, so as to achieve the best extraction results. We also propose an reinforcement learning (RL) based framework to generate optimal extraction order for each instance dynamically. Additionally, we propose a co-training framework adapted to RL to mitigate the exposure bias during the extractor training phase. Extensive experiments conducted on several public datasets demonstrate that our proposed method can beat previous methods and effectively improve the performance of various IE tasks, especially for complex ones.