 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChuanxia Zheng
DragAPart: Learning a Part-Level Motion Prior for Articulated Objects
Mar 22, 2024
We introduce DragAPart, a method that, given an image and a set of drags as input, can generate a new image of the same object in a new state, compatible with the action of the drags. Differently from prior works that focused on repositioning objects, DragAPart predicts part-level interactions, such as opening and closing a drawer. We study this problem as a proxy for learning a generalist motion model, not restricted to a specific kinematic structure or object category. To this end, we start from a pre-trained image generator and fine-tune it on a new synthetic dataset, Drag-a-Move, which we introduce. Combined with a new encoding for the drags and dataset randomization, the new model generalizes well to real images and different categories. Compared to prior motion-controlled generators, we demonstrate much better part-level motion understanding.
MVSplat: Efficient 3D Gaussian Splatting from Sparse Multi-View Images
Mar 21, 2024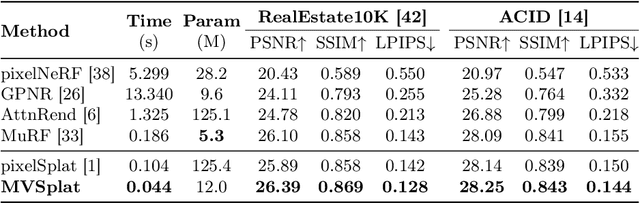
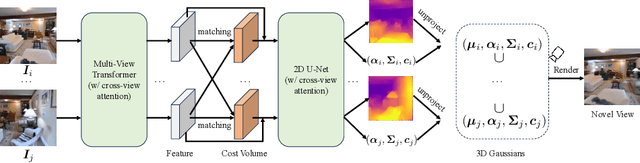


We propose MVSplat, an efficient feed-forward 3D Gaussian Splatting model learned from sparse multi-view images. To accurately localize the Gaussian centers, we propose to build a cost volume representation via plane sweeping in the 3D space, where the cross-view feature similarities stored in the cost volume can provide valuable geometry cues to the estimation of depth. We learn the Gaussian primitives' opacities, covariances, and spherical harmonics coefficients jointly with the Gaussian centers while only relying on photometric supervision. We demonstrate the importance of the cost volume representation in learning feed-forward Gaussian Splatting models via extensive experimental evaluations. On the large-scale RealEstate10K and ACID benchmarks, our model achieves state-of-the-art performance with the fastest feed-forward inference speed (22 fps). Compared to the latest state-of-the-art method pixelSplat, our model uses $10\times $ fewer parameters and infers more than $2\times$ faster while providing higher appearance and geometry quality as well as better cross-dataset generalization.
ClusteringSDF: Self-Organized Neural Implicit Surfaces for 3D Decomposition
Mar 21, 2024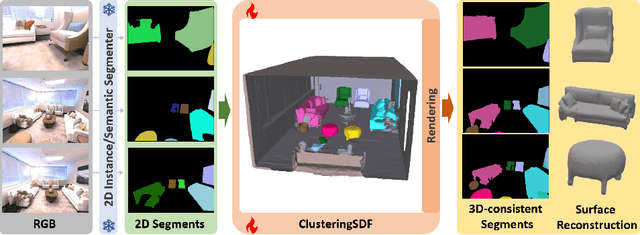

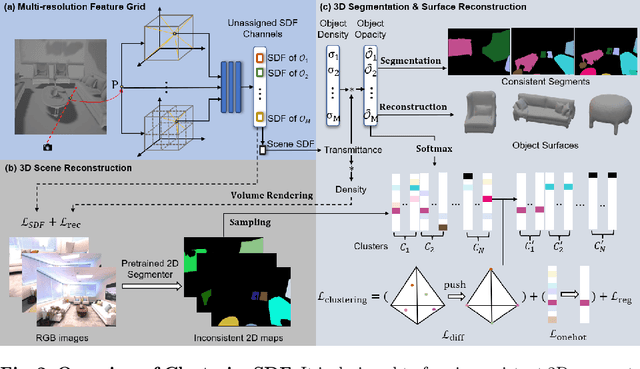
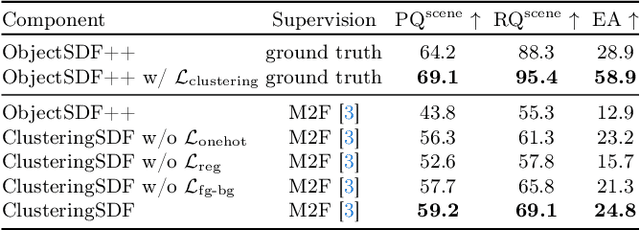
3D decomposition/segmentation still remains a challenge as large-scale 3D annotated data is not readily available. Contemporary approaches typically leverage 2D machine-generated segments, integrating them for 3D consistency. While the majority of these methods are based on NeRFs, they face a potential weakness that the instance/semantic embedding features derive from independent MLPs, thus preventing the segmentation network from learning the geometric details of the objects directly through radiance and density. In this paper, we propose ClusteringSDF, a novel approach to achieve both segmentation and reconstruction in 3D via the neural implicit surface representation, specifically Signal Distance Function (SDF), where the segmentation rendering is directly integrated with the volume rendering of neural implicit surfaces. Although based on ObjectSDF++, ClusteringSDF no longer requires the ground-truth segments for supervision while maintaining the capability of reconstructing individual object surfaces, but purely with the noisy and inconsistent labels from pre-trained models.As the core of ClusteringSDF, we introduce a high-efficient clustering mechanism for lifting the 2D labels to 3D and the experimental results on the challenging scenes from ScanNet and Replica datasets show that ClusteringSDF can achieve competitive performance compared against the state-of-the-art with significantly reduced training time.
Amodal Ground Truth and Completion in the Wild
Dec 28, 2023The problem we study in this paper is amodal image segmentation: predicting entire object segmentation masks including both visible and invisible (occluded) parts. In previous work, the amodal segmentation ground truth on real images is usually predicted by manual annotaton and thus is subjective. In contrast, we use 3D data to establish an automatic pipeline to determine authentic ground truth amodal masks for partially occluded objects in real images. This pipeline is used to construct an amodal completion evaluation benchmark, MP3D-Amodal, consisting of a variety of object categories and labels. To better handle the amodal completion task in the wild, we explore two architecture variants: a two-stage model that first infers the occluder, followed by amodal mask completion; and a one-stage model that exploits the representation power of Stable Diffusion for amodal segmentation across many categories. Without bells and whistles, our method achieves a new state-of-the-art performance on Amodal segmentation datasets that cover a large variety of objects, including COCOA and our new MP3D-Amodal dataset. The dataset, model, and code are available at https://www.robots.ox.ac.uk/~vgg/research/amodal/.
Free3D: Consistent Novel View Synthesis without 3D Representation
Dec 07, 2023We introduce Free3D, a simple approach designed for open-set novel view synthesis (NVS) from a single image. Similar to Zero-1-to-3, we start from a pre-trained 2D image generator for generalization, and fine-tune it for NVS. Compared to recent and concurrent works, we obtain significant improvements without resorting to an explicit 3D representation, which is slow and memory-consuming or training an additional 3D network. We do so by encoding better the target camera pose via a new per-pixel ray conditioning normalization (RCN) layer. The latter injects pose information in the underlying 2D image generator by telling each pixel its specific viewing direction. We also improve multi-view consistency via a light-weight multi-view attention layer and multi-view noise sharing. We train Free3D on the Objaverse dataset and demonstrate excellent generalization to various new categories in several new datasets, including OminiObject3D and GSO. We hope our simple and effective approach will serve as a solid baseline and help future research in NVS with more accuracy pose. The project page is available at https://chuanxiaz.com/free3d/.
One More Step: A Versatile Plug-and-Play Module for Rectifying Diffusion Schedule Flaws and Enhancing Low-Frequency Controls
Nov 27, 2023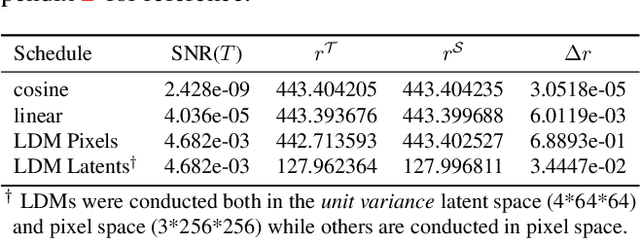
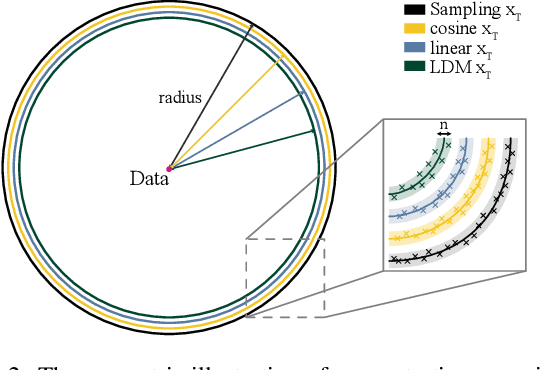
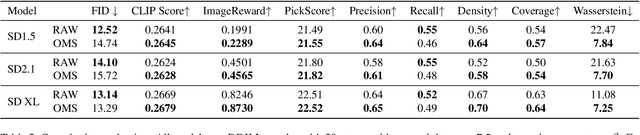
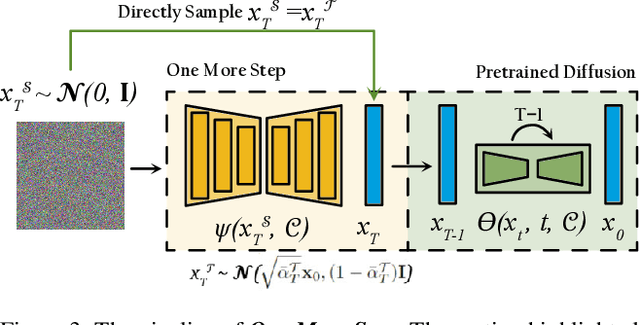
It is well known that many open-released foundational diffusion models have difficulty in generating images that substantially depart from average brightness, despite such images being present in the training data. This is due to an inconsistency: while denoising starts from pure Gaussian noise during inference, the training noise schedule retains residual data even in the final timestep distribution, due to difficulties in numerical conditioning in mainstream formulation, leading to unintended bias during inference. To mitigate this issue, certain $\epsilon$-prediction models are combined with an ad-hoc offset-noise methodology. In parallel, some contemporary models have adopted zero-terminal SNR noise schedules together with $\mathbf{v}$-prediction, which necessitate major alterations to pre-trained models. However, such changes risk destabilizing a large multitude of community-driven applications anchored on these pre-trained models. In light of this, our investigation revisits the fundamental causes, leading to our proposal of an innovative and principled remedy, called One More Step (OMS). By integrating a compact network and incorporating an additional simple yet effective step during inference, OMS elevates image fidelity and harmonizes the dichotomy between training and inference, while preserving original model parameters. Once trained, various pre-trained diffusion models with the same latent domain can share the same OMS module.
What Does Stable Diffusion Know about the 3D Scene?
Oct 10, 2023Recent advances in generative models like Stable Diffusion enable the generation of highly photo-realistic images. Our objective in this paper is to probe the diffusion network to determine to what extent it 'understands' different properties of the 3D scene depicted in an image. To this end, we make the following contributions: (i) We introduce a protocol to evaluate whether a network models a number of physical 'properties' of the 3D scene by probing for explicit features that represent these properties. The probes are applied on datasets of real images with annotations for the property. (ii) We apply this protocol to properties covering scene geometry, scene material, support relations, lighting, and view dependent measures. (iii) We find that Stable Diffusion is good at a number of properties including scene geometry, support relations, shadows and depth, but less performant for occlusion. (iv) We also apply the probes to other models trained at large-scale, including DINO and CLIP, and find their performance inferior to that of Stable Diffusion.
Online Clustered Codebook
Jul 27, 2023
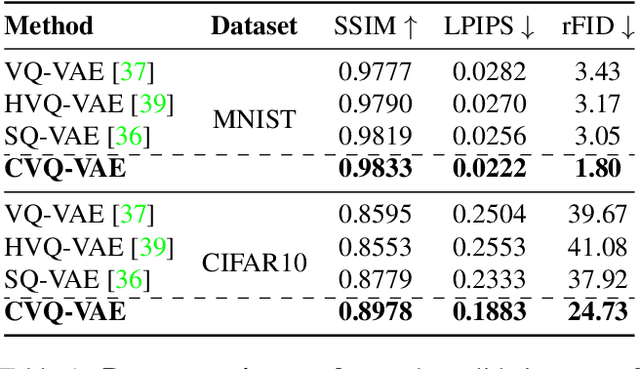
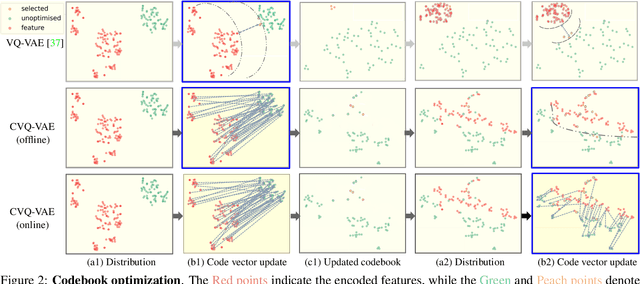
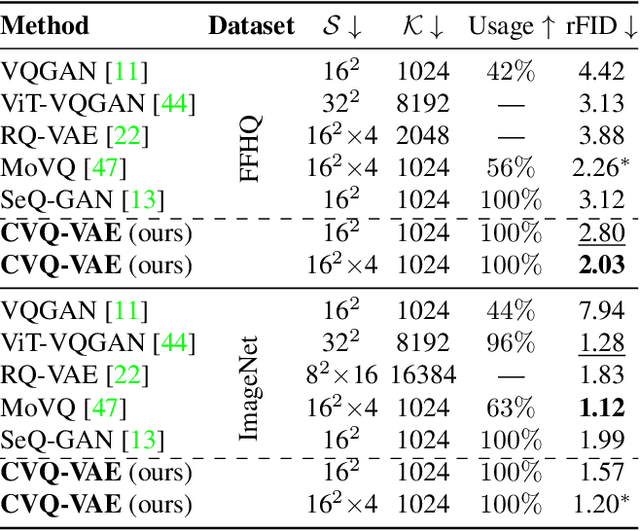
Vector Quantisation (VQ) is experiencing a comeback in machine learning, where it is increasingly used in representation learning. However, optimizing the codevectors in existing VQ-VAE is not entirely trivial. A problem is codebook collapse, where only a small subset of codevectors receive gradients useful for their optimisation, whereas a majority of them simply ``dies off'' and is never updated or used. This limits the effectiveness of VQ for learning larger codebooks in complex computer vision tasks that require high-capacity representations. In this paper, we present a simple alternative method for online codebook learning, Clustering VQ-VAE (CVQ-VAE). Our approach selects encoded features as anchors to update the ``dead'' codevectors, while optimising the codebooks which are alive via the original loss. This strategy brings unused codevectors closer in distribution to the encoded features, increasing the likelihood of being chosen and optimized. We extensively validate the generalization capability of our quantiser on various datasets, tasks (e.g. reconstruction and generation), and architectures (e.g. VQ-VAE, VQGAN, LDM). Our CVQ-VAE can be easily integrated into the existing models with just a few lines of code.
IPO-LDM: Depth-aided 360-degree Indoor RGB Panorama Outpainting via Latent Diffusion Model
Jul 07, 2023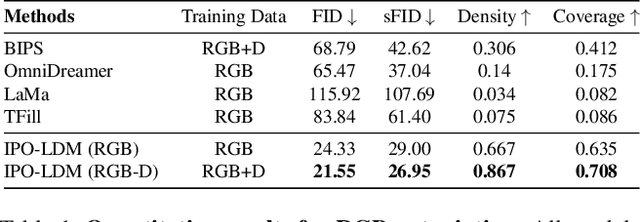
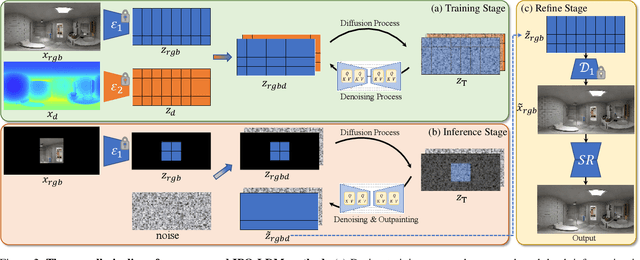
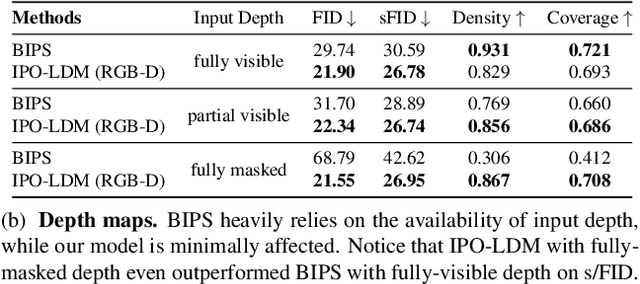
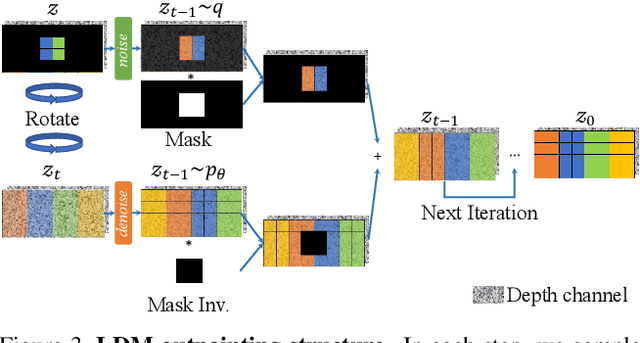
Generating complete 360-degree panoramas from narrow field of view images is ongoing research as omnidirectional RGB data is not readily available. Existing GAN-based approaches face some barriers to achieving higher quality output, and have poor generalization performance over different mask types. In this paper, we present our 360-degree indoor RGB panorama outpainting model using latent diffusion models (LDM), called IPO-LDM. We introduce a new bi-modal latent diffusion structure that utilizes both RGB and depth panoramic data during training, but works surprisingly well to outpaint normal depth-free RGB images during inference. We further propose a novel technique of introducing progressive camera rotations during each diffusion denoising step, which leads to substantial improvement in achieving panorama wraparound consistency. Results show that our IPO-LDM not only significantly outperforms state-of-the-art methods on RGB panorama outpainting, but can also produce multiple and diverse well-structured results for different types of masks.
Cocktail: Mixing Multi-Modality Controls for Text-Conditional Image Generation
Jun 01, 2023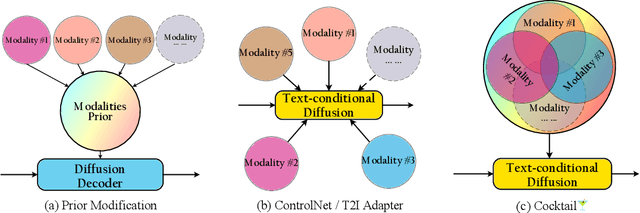

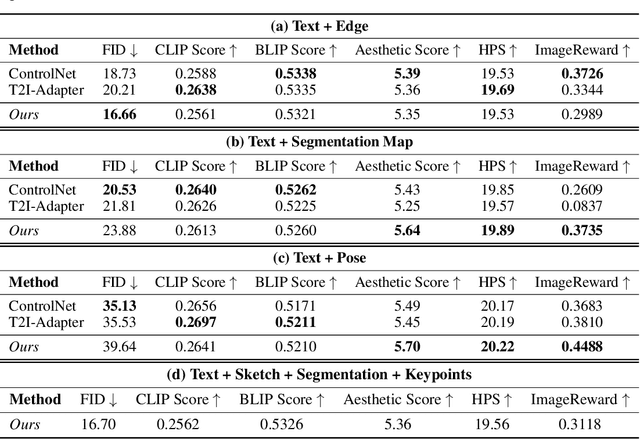
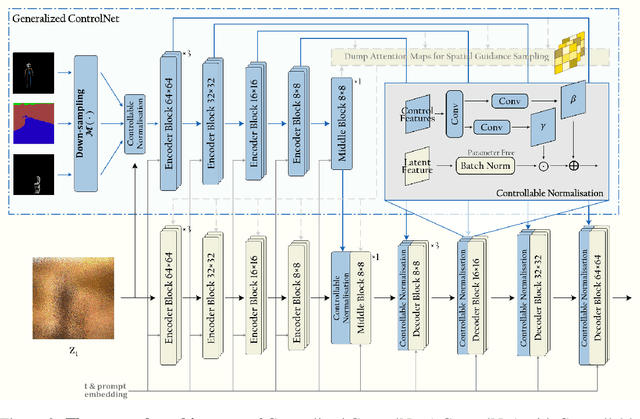
Text-conditional diffusion models are able to generate high-fidelity images with diverse contents. However, linguistic representations frequently exhibit ambiguous descriptions of the envisioned objective imagery, requiring the incorporation of additional control signals to bolster the efficacy of text-guided diffusion models. In this work, we propose Cocktail, a pipeline to mix various modalities into one embedding, amalgamated with a generalized ControlNet (gControlNet), a controllable normalisation (ControlNorm), and a spatial guidance sampling method, to actualize multi-modal and spatially-refined control for text-conditional diffusion models. Specifically, we introduce a hyper-network gControlNet, dedicated to the alignment and infusion of the control signals from disparate modalities into the pre-trained diffusion model. gControlNet is capable of accepting flexible modality signals, encompassing the simultaneous reception of any combination of modality signals, or the supplementary fusion of multiple modality signals. The control signals are then fused and injected into the backbone model according to our proposed ControlNorm. Furthermore, our advanced spatial guidance sampling methodology proficiently incorporates the control signal into the designated region, thereby circumventing the manifestation of undesired objects within the generated image. We demonstrate the results of our method in controlling various modalities, proving high-quality synthesis and fidelity to multiple external signals.