 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChunlin Ji
Prototypical Model with Novel Information-theoretic Loss Function for Generalized Zero Shot Learning
Dec 06, 2021
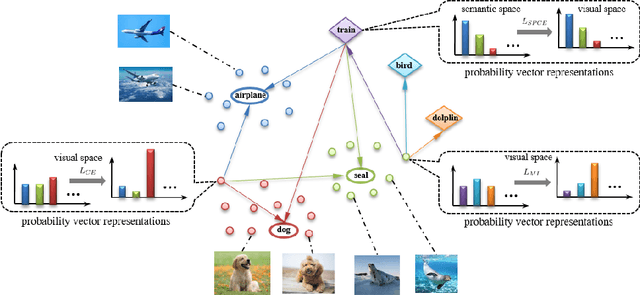
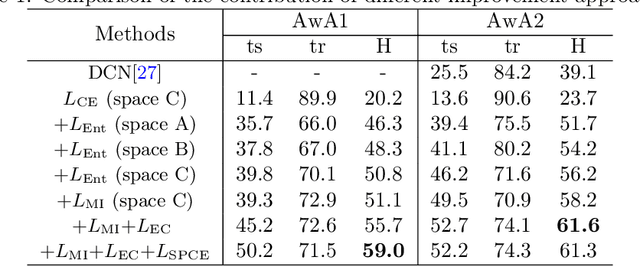
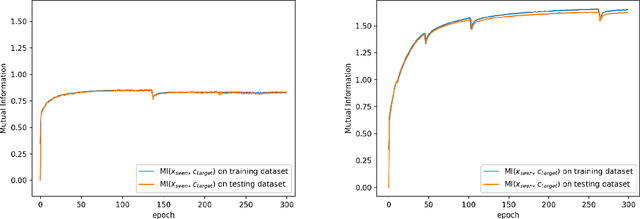
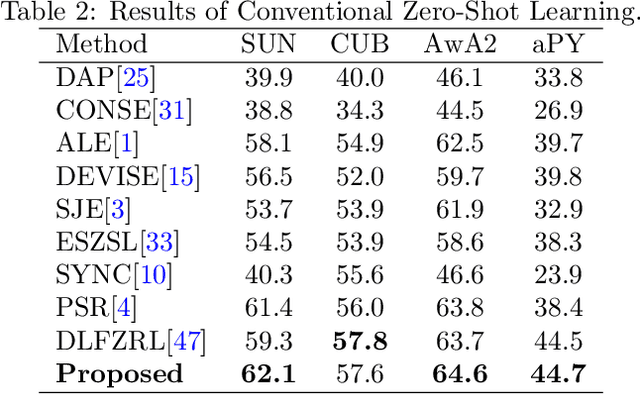
Generalized zero shot learning (GZSL) is still a technical challenge of deep learning as it has to recognize both source and target classes without data from target classes. To preserve the semantic relation between source and target classes when only trained with data from source classes, we address the quantification of the knowledge transfer and semantic relation from an information-theoretic viewpoint. To this end, we follow the prototypical model and format the variables of concern as a probability vector. Leveraging on the proposed probability vector representation, the information measurement such as mutual information and entropy, can be effectively evaluated with simple closed forms. We discuss the choice of common embedding space and distance function when using the prototypical model. Then We propose three information-theoretic loss functions for deterministic GZSL model: a mutual information loss to bridge seen data and target classes; an uncertainty-aware entropy constraint loss to prevent overfitting when using seen data to learn the embedding of target classes; a semantic preserving cross entropy loss to preserve the semantic relation when mapping the semantic representations to the common space. Simulation shows that, as a deterministic model, our proposed method obtains state of the art results on GZSL benchmark datasets. We achieve 21%-64% improvements over the baseline model -- deep calibration network (DCN) and for the first time demonstrate a deterministic model can perform as well as generative ones. Moreover, our proposed model is compatible with generative models. Simulation studies show that by incorporating with f-CLSWGAN, we obtain comparable results compared with advanced generative models.
Stochastic Variational Inference via Upper Bound
Dec 02, 2019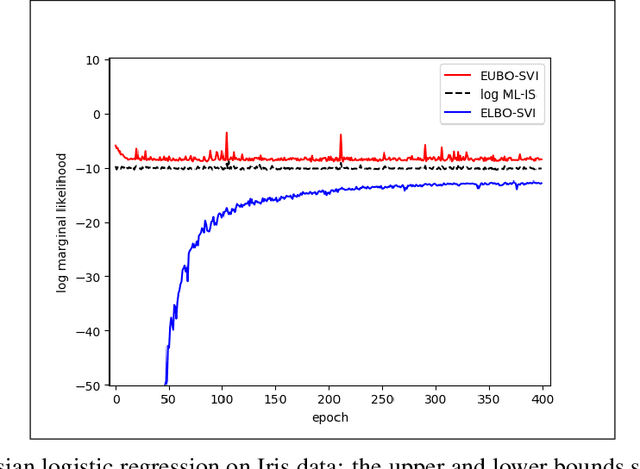
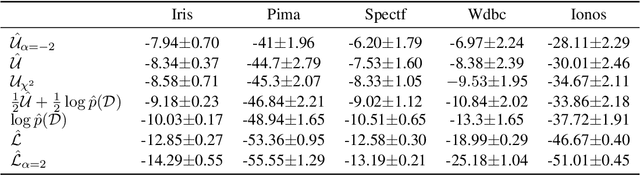
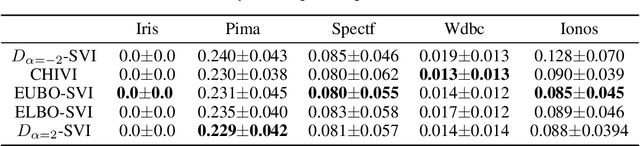
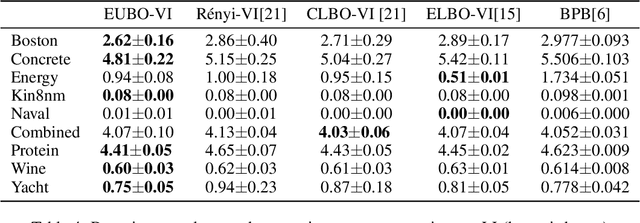
Stochastic variational inference (SVI) plays a key role in Bayesian deep learning. Recently various divergences have been proposed to design the surrogate loss for variational inference. We present a simple upper bound of the evidence as the surrogate loss. This evidence upper bound (EUBO) equals to the log marginal likelihood plus the KL-divergence between the posterior and the proposal. We show that the proposed EUBO is tighter than previous upper bounds introduced by $\chi$-divergence or $\alpha$-divergence. To facilitate scalable inference, we present the numerical approximation of the gradient of the EUBO and apply the SGD algorithm to optimize the variational parameters iteratively. Simulation study with Bayesian logistic regression shows that the upper and lower bounds well sandwich the evidence and the proposed upper bound is favorably tight. For Bayesian neural network, the proposed EUBO-VI algorithm outperforms state-of-the-art results for various examples.