 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClaire Monteleoni
Parameter Efficient Fine-tuning of Self-supervised ViTs without Catastrophic Forgetting
Apr 26, 2024
Artificial neural networks often suffer from catastrophic forgetting, where learning new concepts leads to a complete loss of previously acquired knowledge. We observe that this issue is particularly magnified in vision transformers (ViTs), where post-pre-training and fine-tuning on new tasks can significantly degrade the model's original general abilities. For instance, a DINO ViT-Base/16 pre-trained on ImageNet-1k loses over 70% accuracy on ImageNet-1k after just 10 iterations of fine-tuning on CIFAR-100. Overcoming this stability-plasticity dilemma is crucial for enabling ViTs to continuously learn and adapt to new domains while preserving their initial knowledge. In this work, we study two new parameter-efficient fine-tuning strategies: (1)~Block Expansion, and (2) Low-rank adaptation (LoRA). Our experiments reveal that using either Block Expansion or LoRA on self-supervised pre-trained ViTs surpass fully fine-tuned ViTs in new domains while offering significantly greater parameter efficiency. Notably, we find that Block Expansion experiences only a minimal performance drop in the pre-training domain, thereby effectively mitigating catastrophic forgetting in pre-trained ViTs.
Application-Driven Innovation in Machine Learning
Mar 26, 2024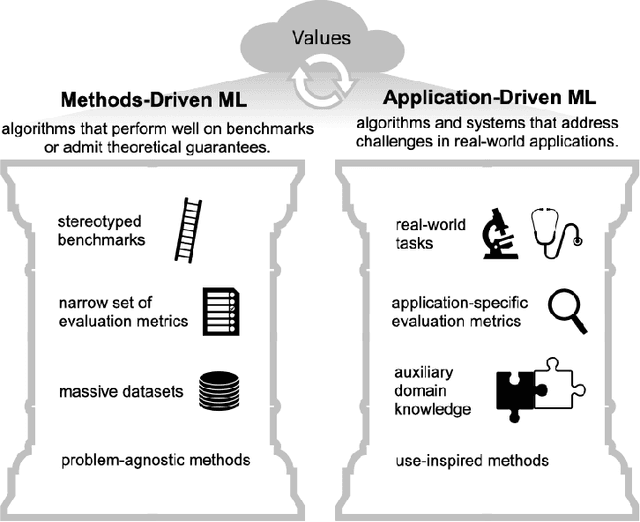
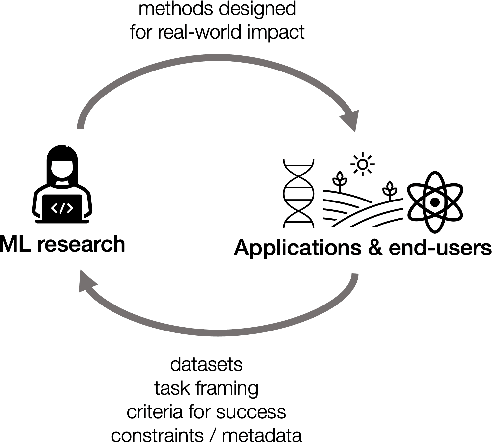
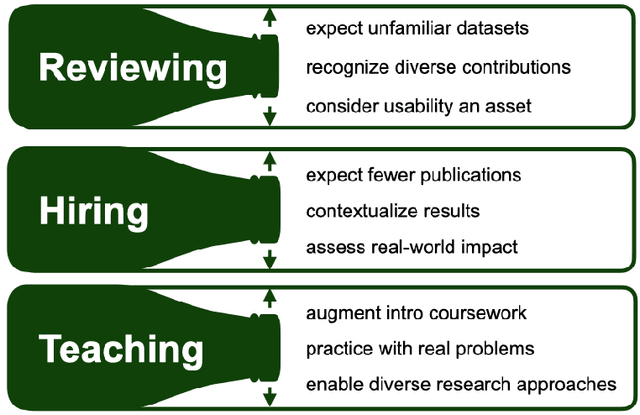
As applications of machine learning proliferate, innovative algorithms inspired by specific real-world challenges have become increasingly important. Such work offers the potential for significant impact not merely in domains of application but also in machine learning itself. In this paper, we describe the paradigm of application-driven research in machine learning, contrasting it with the more standard paradigm of methods-driven research. We illustrate the benefits of application-driven machine learning and how this approach can productively synergize with methods-driven work. Despite these benefits, we find that reviewing, hiring, and teaching practices in machine learning often hold back application-driven innovation. We outline how these processes may be improved.
Multi-decadal Sea Level Prediction using Neural Networks and Spectral Clustering on Climate Model Large Ensembles and Satellite Altimeter Data
Oct 06, 2023Sea surface height observations provided by satellite altimetry since 1993 show a rising rate (3.4 mm/year) for global mean sea level. While on average, sea level has risen 10 cm over the last 30 years, there is considerable regional variation in the sea level change. Through this work, we predict sea level trends 30 years into the future at a 2-degree spatial resolution and investigate the future patterns of the sea level change. We show the potential of machine learning (ML) in this challenging application of long-term sea level forecasting over the global ocean. Our approach incorporates sea level data from both altimeter observations and climate model simulations. We develop a supervised learning framework using fully connected neural networks (FCNNs) that can predict the sea level trend based on climate model projections. Alongside this, our method provides uncertainty estimates associated with the ML prediction. We also show the effectiveness of partitioning our spatial dataset and learning a dedicated ML model for each segmented region. We compare two partitioning strategies: one achieved using domain knowledge, and the other employing spectral clustering. Our results demonstrate that segmenting the spatial dataset with spectral clustering improves the ML predictions.
STint: Self-supervised Temporal Interpolation for Geospatial Data
Aug 31, 2023



Supervised and unsupervised techniques have demonstrated the potential for temporal interpolation of video data. Nevertheless, most prevailing temporal interpolation techniques hinge on optical flow, which encodes the motion of pixels between video frames. On the other hand, geospatial data exhibits lower temporal resolution while encompassing a spectrum of movements and deformations that challenge several assumptions inherent to optical flow. In this work, we propose an unsupervised temporal interpolation technique, which does not rely on ground truth data or require any motion information like optical flow, thus offering a promising alternative for better generalization across geospatial domains. Specifically, we introduce a self-supervised technique of dual cycle consistency. Our proposed technique incorporates multiple cycle consistency losses, which result from interpolating two frames between consecutive input frames through a series of stages. This dual cycle consistent constraint causes the model to produce intermediate frames in a self-supervised manner. To the best of our knowledge, this is the first attempt at unsupervised temporal interpolation without the explicit use of optical flow. Our experimental evaluations across diverse geospatial datasets show that STint significantly outperforms existing state-of-the-art methods for unsupervised temporal interpolation.
Sea level Projections with Machine Learning using Altimetry and Climate Model ensembles
Aug 02, 2023Satellite altimeter observations retrieved since 1993 show that the global mean sea level is rising at an unprecedented rate (3.4mm/year). With almost three decades of observations, we can now investigate the contributions of anthropogenic climate-change signals such as greenhouse gases, aerosols, and biomass burning in this rising sea level. We use machine learning (ML) to investigate future patterns of sea level change. To understand the extent of contributions from the climate-change signals, and to help in forecasting sea level change in the future, we turn to climate model simulations. This work presents a machine learning framework that exploits both satellite observations and climate model simulations to generate sea level rise projections at a 2-degree resolution spatial grid, 30 years into the future. We train fully connected neural networks (FCNNs) to predict altimeter values through a non-linear fusion of the climate model hindcasts (for 1993-2019). The learned FCNNs are then applied to future climate model projections to predict future sea level patterns. We propose segmenting our spatial dataset into meaningful clusters and show that clustering helps to improve predictions of our ML model.
Reflections from the Workshop on AI-Assisted Decision Making for Conservation
Jul 17, 2023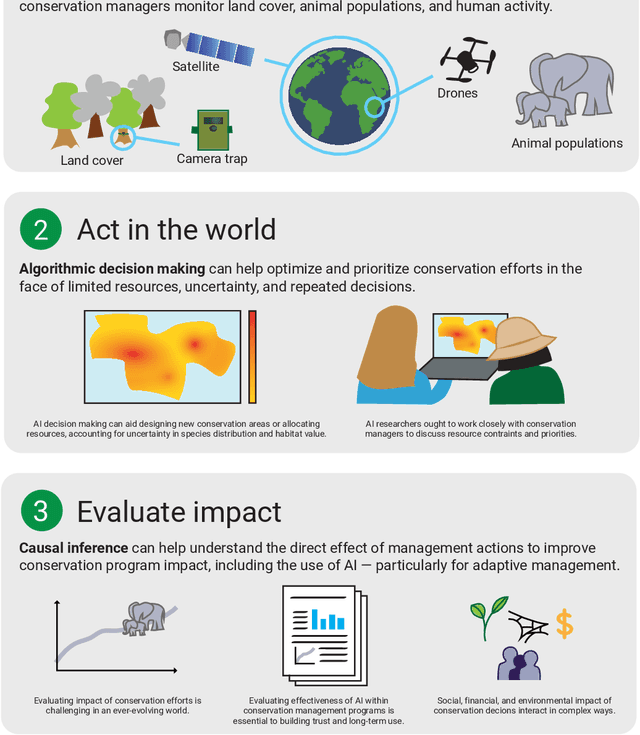

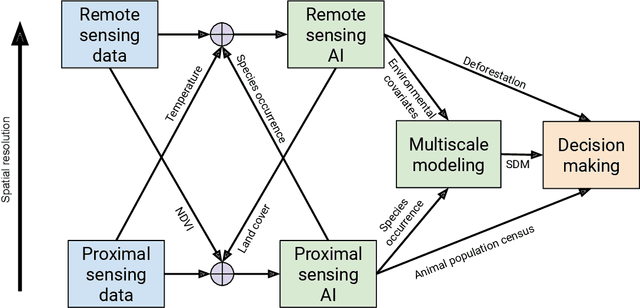
In this white paper, we synthesize key points made during presentations and discussions from the AI-Assisted Decision Making for Conservation workshop, hosted by the Center for Research on Computation and Society at Harvard University on October 20-21, 2022. We identify key open research questions in resource allocation, planning, and interventions for biodiversity conservation, highlighting conservation challenges that not only require AI solutions, but also require novel methodological advances. In addition to providing a summary of the workshop talks and discussions, we hope this document serves as a call-to-action to orient the expansion of algorithmic decision-making approaches to prioritize real-world conservation challenges, through collaborative efforts of ecologists, conservation decision-makers, and AI researchers.
ClimAlign: Unsupervised statistical downscaling of climate variables via normalizing flows
Aug 11, 2020



Downscaling is a landmark task in climate science and meteorology in which the goal is to use coarse scale, spatio-temporal data to infer values at finer scales. Statistical downscaling aims to approximate this task using statistical patterns gleaned from an existing dataset of downscaled values, often obtained from observations or physical models. In this work, we investigate the application of deep latent variable learning to the task of statistical downscaling. We present ClimAlign, a novel method for unsupervised, generative downscaling using adaptations of recent work in normalizing flows for variational inference. We evaluate the viability of our method using several different metrics on two datasets consisting of daily temperature and precipitation values gridded at low (1 degree latitude/longitude) and high (1/4 and 1/8 degree) resolutions. We show that our method achieves comparable predictive performance to existing supervised statistical downscaling methods while simultaneously allowing for both conditional and unconditional sampling from the joint distribution over high and low resolution spatial fields. We provide publicly accessible implementations of our method, as well as the baselines used for comparison, on GitHub.
Tropical Cyclone Track Forecasting using Fused Deep Learning from Aligned Reanalysis Data
Oct 23, 2019



The forecast of tropical cyclone trajectories is crucial for the protection of people and property. Although forecast dynamical models can provide high-precision short-term forecasts, they are computationally demanding, and current statistical forecasting models have much room for improvement given that the database of past hurricanes is constantly growing. Machine learning methods, that can capture non-linearities and complex relations, have only been scarcely tested for this application. We propose a neural network model fusing past trajectory data and reanalysis atmospheric images (wind and pressure 3D fields). We use a moving frame of reference that follows the storm center for the 24h tracking forecast. The network is trained to estimate the longitude and latitude displacement of tropical cyclones and depressions from a large database from both hemispheres (more than 3000 storms since 1979, sampled at a 6 hour frequency). The advantage of the fused network is demonstrated and a comparison with current forecast models shows that deep learning methods could provide a valuable and complementary prediction. Moreover, our method can give a forecast for a new storm in a few seconds, which is an important asset for real-time forecasts compared to traditional forecasts.
Evaluating the distribution learning capabilities of GANs
Jul 05, 2019



We evaluate the distribution learning capabilities of generative adversarial networks by testing them on synthetic datasets. The datasets include common distributions of points in $R^n$ space and images containing polygons of various shapes and sizes. We find that by and large GANs fail to faithfully recreate point datasets which contain discontinous support or sharp bends with noise. Additionally, on image datasets, we find that GANs do not seem to learn to count the number of objects of the same kind in an image. We also highlight the apparent tension between generalization and learning in GANs.
Cooperative Online Learning: Keeping your Neighbors Updated
Jan 23, 2019We study an asynchronous online learning setting with a network of agents. At each time step, some of the agents are activated, requested to make a prediction, and pay the corresponding loss. The loss function is then revealed to these agents and also to their neighbors in the network. When activations are stochastic, we show that the regret achieved by $N$ agents running the standard online Mirror Descent is $O(\sqrt{\alpha T})$, where $T$ is the horizon and $\alpha \le N$ is the independence number of the network. This is in contrast to the regret $\Omega(\sqrt{N T})$ which $N$ agents incur in the same setting when feedback is not shared. We also show a matching lower bound of order $\sqrt{\alpha T}$ that holds for any given network. When the pattern of agent activations is arbitrary, the problem changes significantly: we prove a $\Omega(T)$ lower bound on the regret that holds for any online algorithm oblivious to the feedback source.