 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClayton Sanford
Transformers, parallel computation, and logarithmic depth
Feb 14, 2024
We show that a constant number of self-attention layers can efficiently simulate, and be simulated by, a constant number of communication rounds of Massively Parallel Computation. As a consequence, we show that logarithmic depth is sufficient for transformers to solve basic computational tasks that cannot be efficiently solved by several other neural sequence models and sub-quadratic transformer approximations. We thus establish parallelism as a key distinguishing property of transformers.
Representational Strengths and Limitations of Transformers
Jun 05, 2023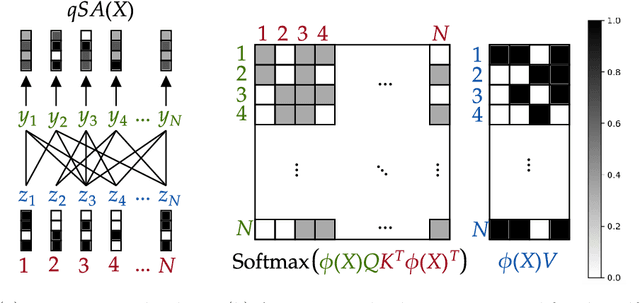
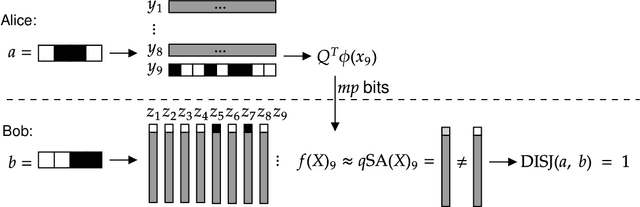
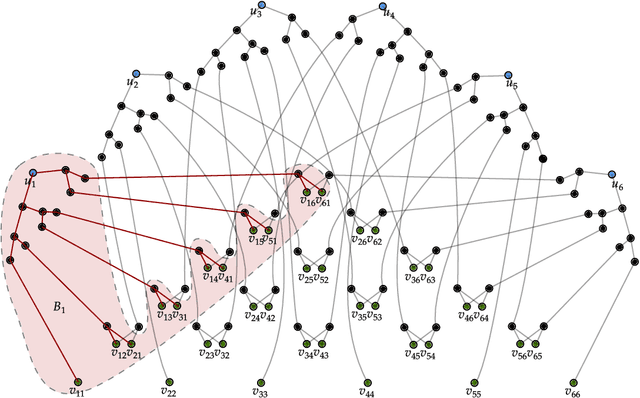
Attention layers, as commonly used in transformers, form the backbone of modern deep learning, yet there is no mathematical description of their benefits and deficiencies as compared with other architectures. In this work we establish both positive and negative results on the representation power of attention layers, with a focus on intrinsic complexity parameters such as width, depth, and embedding dimension. On the positive side, we present a sparse averaging task, where recurrent networks and feedforward networks all have complexity scaling polynomially in the input size, whereas transformers scale merely logarithmically in the input size; furthermore, we use the same construction to show the necessity and role of a large embedding dimension in a transformer. On the negative side, we present a triple detection task, where attention layers in turn have complexity scaling linearly in the input size; as this scenario seems rare in practice, we also present natural variants that can be efficiently solved by attention layers. The proof techniques emphasize the value of communication complexity in the analysis of transformers and related models, and the role of sparse averaging as a prototypical attention task, which even finds use in the analysis of triple detection.
Learning Single-Index Models with Shallow Neural Networks
Oct 27, 2022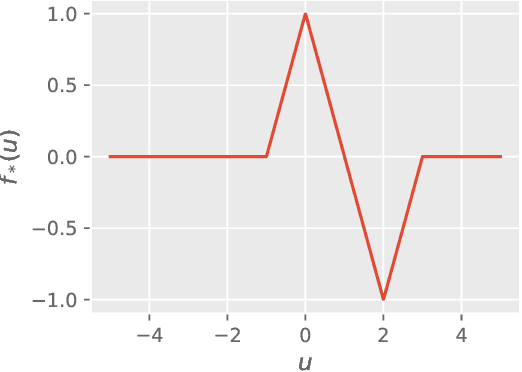
Single-index models are a class of functions given by an unknown univariate ``link'' function applied to an unknown one-dimensional projection of the input. These models are particularly relevant in high dimension, when the data might present low-dimensional structure that learning algorithms should adapt to. While several statistical aspects of this model, such as the sample complexity of recovering the relevant (one-dimensional) subspace, are well-understood, they rely on tailored algorithms that exploit the specific structure of the target function. In this work, we introduce a natural class of shallow neural networks and study its ability to learn single-index models via gradient flow. More precisely, we consider shallow networks in which biases of the neurons are frozen at random initialization. We show that the corresponding optimization landscape is benign, which in turn leads to generalization guarantees that match the near-optimal sample complexity of dedicated semi-parametric methods.
On Scrambling Phenomena for Randomly Initialized Recurrent Networks
Oct 11, 2022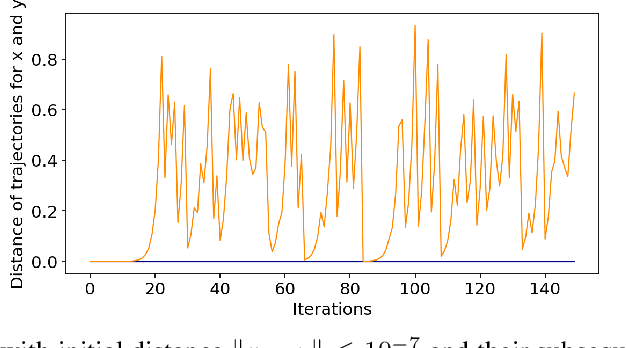

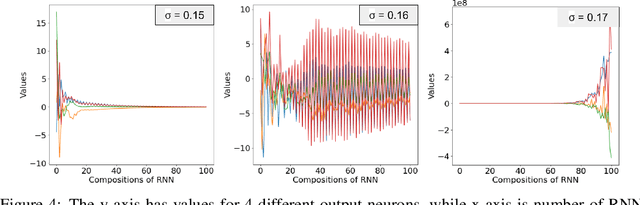
Recurrent Neural Networks (RNNs) frequently exhibit complicated dynamics, and their sensitivity to the initialization process often renders them notoriously hard to train. Recent works have shed light on such phenomena analyzing when exploding or vanishing gradients may occur, either of which is detrimental for training dynamics. In this paper, we point to a formal connection between RNNs and chaotic dynamical systems and prove a qualitatively stronger phenomenon about RNNs than what exploding gradients seem to suggest. Our main result proves that under standard initialization (e.g., He, Xavier etc.), RNNs will exhibit \textit{Li-Yorke chaos} with \textit{constant} probability \textit{independent} of the network's width. This explains the experimentally observed phenomenon of \textit{scrambling}, under which trajectories of nearby points may appear to be arbitrarily close during some timesteps, yet will be far away in future timesteps. In stark contrast to their feedforward counterparts, we show that chaotic behavior in RNNs is preserved under small perturbations and that their expressive power remains exponential in the number of feedback iterations. Our technical arguments rely on viewing RNNs as random walks under non-linear activations, and studying the existence of certain types of higher-order fixed points called \textit{periodic points} that lead to phase transitions from order to chaos.
Intrinsic dimensionality and generalization properties of the $\mathcal{R}$-norm inductive bias
Jun 10, 2022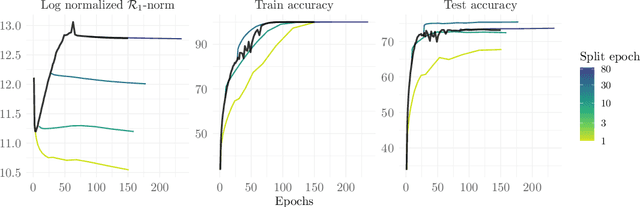

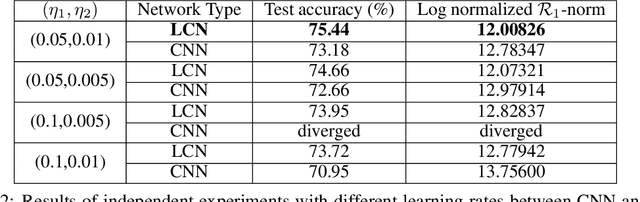
We study the structural and statistical properties of $\mathcal{R}$-norm minimizing interpolants of datasets labeled by specific target functions. The $\mathcal{R}$-norm is the basis of an inductive bias for two-layer neural networks, recently introduced to capture the functional effect of controlling the size of network weights, independently of the network width. We find that these interpolants are intrinsically multivariate functions, even when there are ridge functions that fit the data, and also that the $\mathcal{R}$-norm inductive bias is not sufficient for achieving statistically optimal generalization for certain learning problems. Altogether, these results shed new light on an inductive bias that is connected to practical neural network training.
Near-Optimal Statistical Query Lower Bounds for Agnostically Learning Intersections of Halfspaces with Gaussian Marginals
Feb 10, 2022We consider the well-studied problem of learning intersections of halfspaces under the Gaussian distribution in the challenging \emph{agnostic learning} model. Recent work of Diakonikolas et al. (2021) shows that any Statistical Query (SQ) algorithm for agnostically learning the class of intersections of $k$ halfspaces over $\mathbb{R}^n$ to constant excess error either must make queries of tolerance at most $n^{-\tilde{\Omega}(\sqrt{\log k})}$ or must make $2^{n^{\Omega(1)}}$ queries. We strengthen this result by improving the tolerance requirement to $n^{-\tilde{\Omega}(\log k)}$. This lower bound is essentially best possible since an SQ algorithm of Klivans et al. (2008) agnostically learns this class to any constant excess error using $n^{O(\log k)}$ queries of tolerance $n^{-O(\log k)}$. We prove two variants of our lower bound, each of which combines ingredients from Diakonikolas et al. (2021) with (an extension of) a different earlier approach for agnostic SQ lower bounds for the Boolean setting due to Dachman-Soled et al. (2014). Our approach also yields lower bounds for agnostically SQ learning the class of "convex subspace juntas" (studied by Vempala, 2010) and the class of sets with bounded Gaussian surface area; all of these lower bounds are nearly optimal since they essentially match known upper bounds from Klivans et al. (2008).
Expressivity of Neural Networks via Chaotic Itineraries beyond Sharkovsky's Theorem
Oct 19, 2021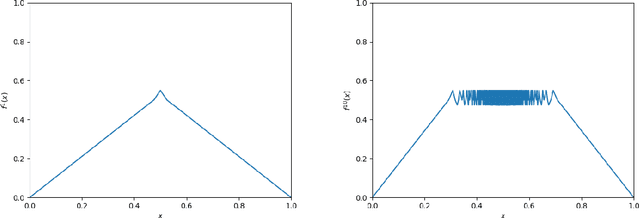
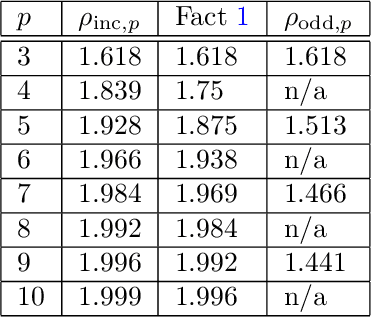
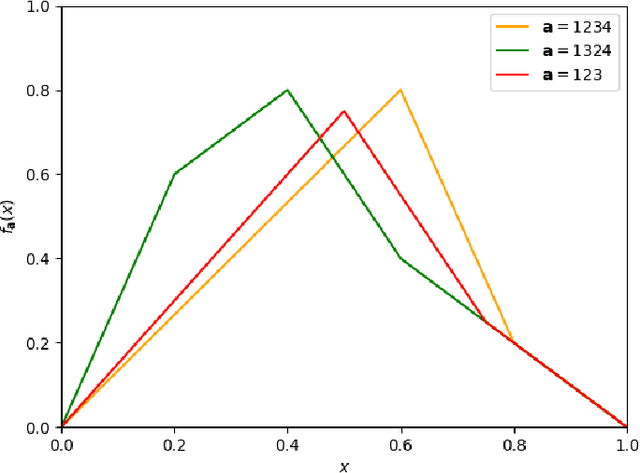
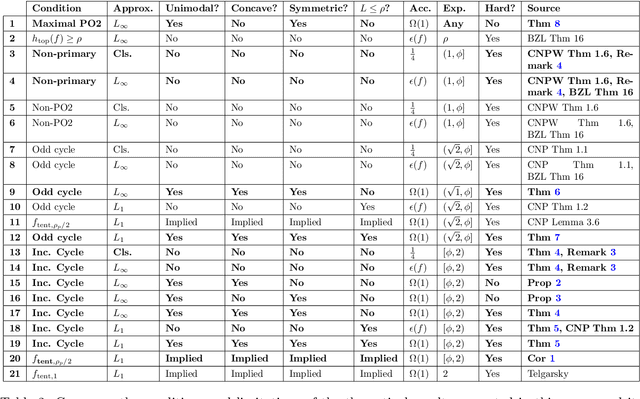
Given a target function $f$, how large must a neural network be in order to approximate $f$? Recent works examine this basic question on neural network \textit{expressivity} from the lens of dynamical systems and provide novel ``depth-vs-width'' tradeoffs for a large family of functions $f$. They suggest that such tradeoffs are governed by the existence of \textit{periodic} points or \emph{cycles} in $f$. Our work, by further deploying dynamical systems concepts, illuminates a more subtle connection between periodicity and expressivity: we prove that periodic points alone lead to suboptimal depth-width tradeoffs and we improve upon them by demonstrating that certain ``chaotic itineraries'' give stronger exponential tradeoffs, even in regimes where previous analyses only imply polynomial gaps. Contrary to prior works, our bounds are nearly-optimal, tighten as the period increases, and handle strong notions of inapproximability (e.g., constant $L_1$ error). More broadly, we identify a phase transition to the \textit{chaotic regime} that exactly coincides with an abrupt shift in other notions of function complexity, including VC-dimension and topological entropy.
Support vector machines and linear regression coincide with very high-dimensional features
May 28, 2021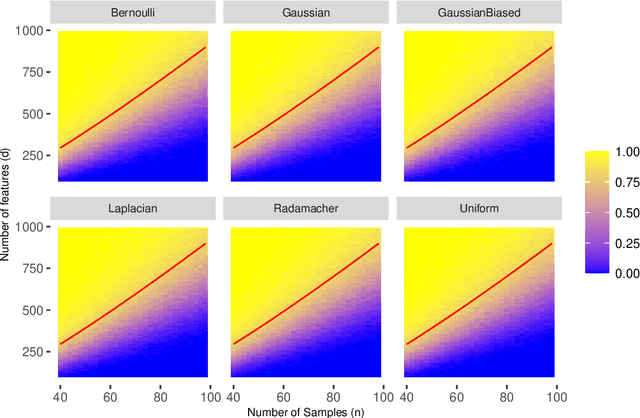
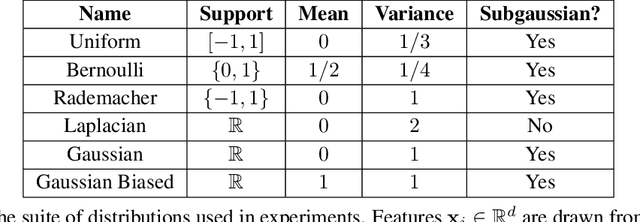
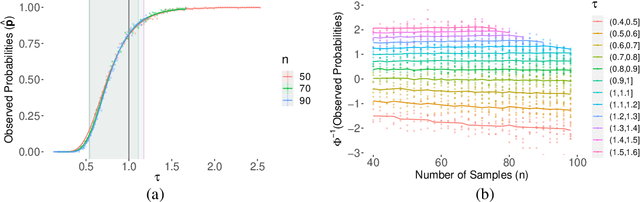

The support vector machine (SVM) and minimum Euclidean norm least squares regression are two fundamentally different approaches to fitting linear models, but they have recently been connected in models for very high-dimensional data through a phenomenon of support vector proliferation, where every training example used to fit an SVM becomes a support vector. In this paper, we explore the generality of this phenomenon and make the following contributions. First, we prove a super-linear lower bound on the dimension (in terms of sample size) required for support vector proliferation in independent feature models, matching the upper bounds from previous works. We further identify a sharp phase transition in Gaussian feature models, bound the width of this transition, and give experimental support for its universality. Finally, we hypothesize that this phase transition occurs only in much higher-dimensional settings in the $\ell_1$ variant of the SVM, and we present a new geometric characterization of the problem that may elucidate this phenomenon for the general $\ell_p$ case.
On the Approximation Power of Two-Layer Networks of Random ReLUs
Feb 03, 2021
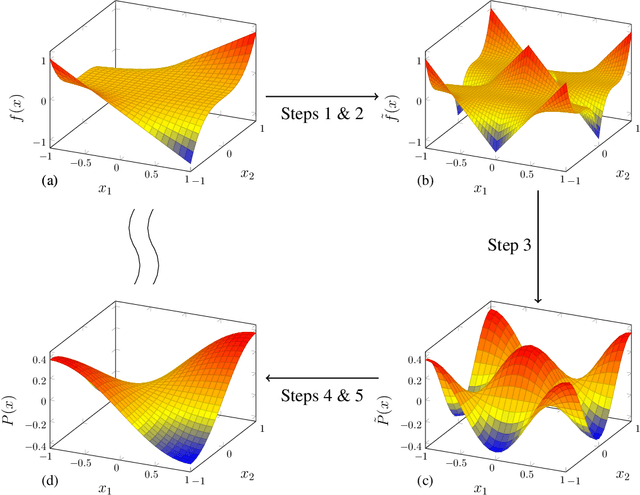
This paper considers the following question: how well can depth-two ReLU networks with randomly initialized bottom-level weights represent smooth functions? We give near-matching upper- and lower-bounds for $L_2$-approximation in terms of the Lipschitz constant, the desired accuracy, and the dimension of the problem, as well as similar results in terms of Sobolev norms. Our positive results employ tools from harmonic analysis and ridgelet representation theory, while our lower-bounds are based on (robust versions of) dimensionality arguments.
Uniform Convergence Bounds for Codec Selection
Dec 18, 2018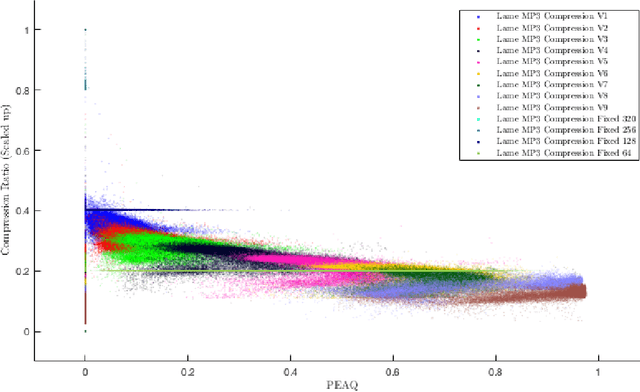

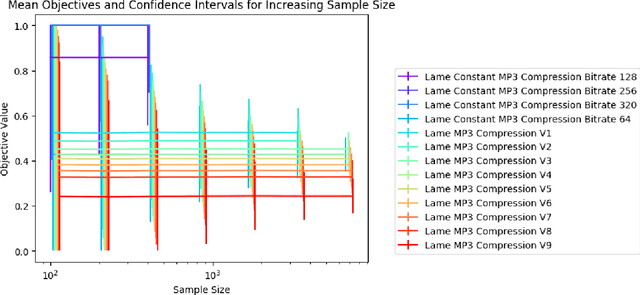
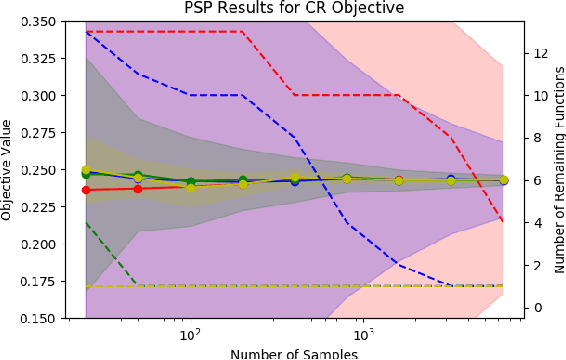
We frame the problem of selecting an optimal audio encoding scheme as a supervised learning task. Through uniform convergence theory, we guarantee approximately optimal codec selection while controlling for selection bias. We present rigorous statistical guarantees for the codec selection problem that hold for arbitrary distributions over audio sequences and for arbitrary quality metrics. Our techniques can thus balance sound quality and compression ratio, and use audio samples from the distribution to select a codec that performs well on that particular type of data. The applications of our technique are immense, as it can be used to optimize for quality and bandwidth usage of streaming and other digital media, while significantly outperforming approaches that apply a fixed codec to all data sources.