 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCongzhi Zhang
Causal Prompting: Debiasing Large Language Model Prompting based on Front-Door Adjustment
Mar 05, 2024
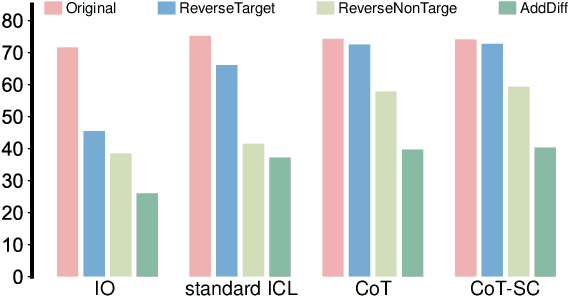
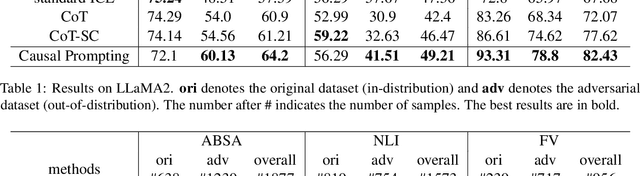
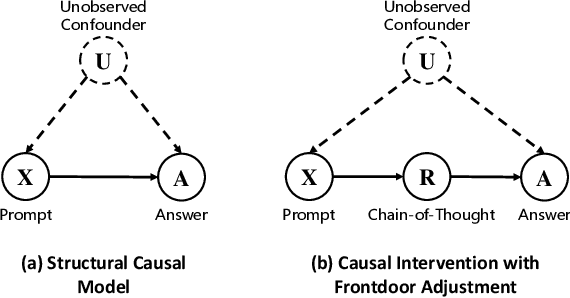
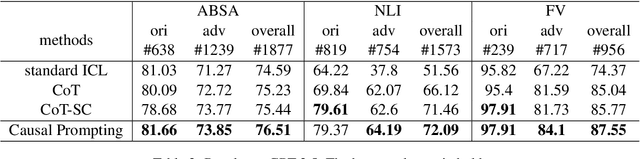
Despite the significant achievements of existing prompting methods such as in-context learning and chain-of-thought for large language models (LLMs), they still face challenges of various biases. Traditional debiasing methods primarily focus on the model training stage, including data augmentation-based and reweight-based approaches, with the limitations of addressing the complex biases of LLMs. To address such limitations, the causal relationship behind the prompting methods is uncovered using a structural causal model, and a novel causal prompting method based on front-door adjustment is proposed to effectively mitigate the bias of LLMs. In specific, causal intervention is implemented by designing the prompts without accessing the parameters and logits of LLMs.The chain-of-thoughts generated by LLMs are employed as the mediator variable and the causal effect between the input prompt and the output answers is calculated through front-door adjustment to mitigate model biases. Moreover, to obtain the representation of the samples precisely and estimate the causal effect more accurately, contrastive learning is used to fine-tune the encoder of the samples by aligning the space of the encoder with the LLM. Experimental results show that the proposed causal prompting approach achieves excellent performance on 3 natural language processing datasets on both open-source and closed-source LLMs.
Causal Walk: Debiasing Multi-Hop Fact Verification with Front-Door Adjustment
Mar 05, 2024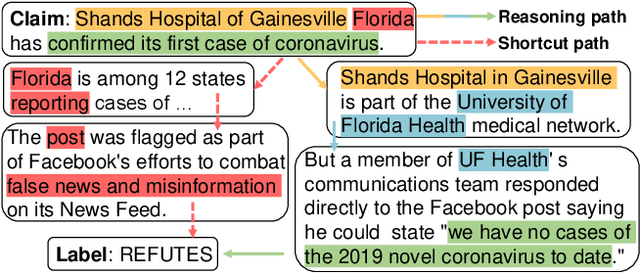

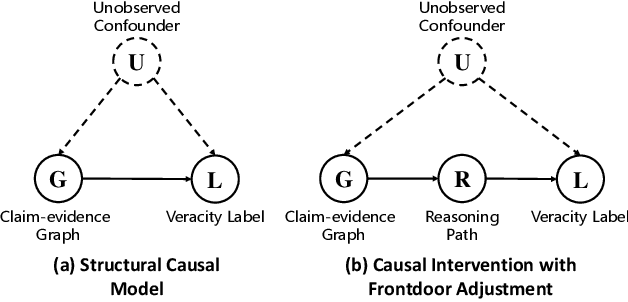

Conventional multi-hop fact verification models are prone to rely on spurious correlations from the annotation artifacts, leading to an obvious performance decline on unbiased datasets. Among the various debiasing works, the causal inference-based methods become popular by performing theoretically guaranteed debiasing such as casual intervention or counterfactual reasoning. However, existing causal inference-based debiasing methods, which mainly formulate fact verification as a single-hop reasoning task to tackle shallow bias patterns, cannot deal with the complicated bias patterns hidden in multiple hops of evidence. To address the challenge, we propose Causal Walk, a novel method for debiasing multi-hop fact verification from a causal perspective with front-door adjustment. Specifically, in the structural causal model, the reasoning path between the treatment (the input claim-evidence graph) and the outcome (the veracity label) is introduced as the mediator to block the confounder. With the front-door adjustment, the causal effect between the treatment and the outcome is decomposed into the causal effect between the treatment and the mediator, which is estimated by applying the idea of random walk, and the causal effect between the mediator and the outcome, which is estimated with normalized weighted geometric mean approximation. To investigate the effectiveness of the proposed method, an adversarial multi-hop fact verification dataset and a symmetric multi-hop fact verification dataset are proposed with the help of the large language model. Experimental results show that Causal Walk outperforms some previous debiasing methods on both existing datasets and the newly constructed datasets. Code and data will be released at https://github.com/zcccccz/CausalWalk.
Genes in Intelligent Agents
Jun 17, 2023



Training intelligent agents in Reinforcement Learning (RL) is much more time-consuming than animal learning. This is because agents learn from scratch, but animals learn with genes inherited from ancestors and are born with some innate abilities. Inspired by genes in animals, here we conceptualize the gene in intelligent agents and introduce Genetic Reinforcement Learning (GRL), a computational framework to represent, evaluate, and evolve genes (in agents). Leveraging GRL we identify genes and demonstrate several advantages of genes. First, we find that genes take the form of the fragment of agents' neural networks and can be inherited across generations. Second, we validate that genes bring better and stabler learning ability to agents, since genes condense knowledge from ancestors and bring agent with innate abilities. Third, we present evidence of Lamarckian evolution in intelligent agents. The continuous encoding of knowledge into genes across generations facilitates the evolution of genes. Overall, our work promotes a novel paradigm to train agents by incorporating genes.