 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConrad M Albrecht
AIO2: Online Correction of Object Labels for Deep Learning with Incomplete Annotation in Remote Sensing Image Segmentation
Mar 03, 2024
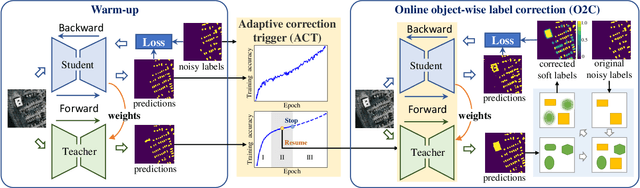
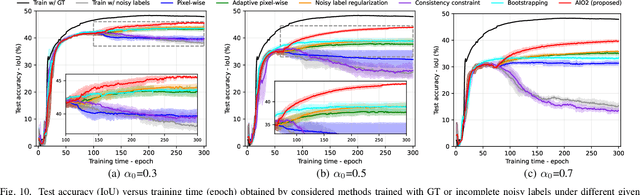

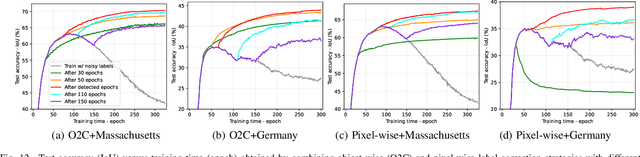
While the volume of remote sensing data is increasing daily, deep learning in Earth Observation faces lack of accurate annotations for supervised optimization. Crowdsourcing projects such as OpenStreetMap distribute the annotation load to their community. However, such annotation inevitably generates noise due to insufficient control of the label quality, lack of annotators, frequent changes of the Earth's surface as a result of natural disasters and urban development, among many other factors. We present Adaptively trIggered Online Object-wise correction (AIO2) to address annotation noise induced by incomplete label sets. AIO2 features an Adaptive Correction Trigger (ACT) module that avoids label correction when the model training under- or overfits, and an Online Object-wise Correction (O2C) methodology that employs spatial information for automated label modification. AIO2 utilizes a mean teacher model to enhance training robustness with noisy labels to both stabilize the training accuracy curve for fitting in ACT and provide pseudo labels for correction in O2C. Moreover, O2C is implemented online without the need to store updated labels every training epoch. We validate our approach on two building footprint segmentation datasets with different spatial resolutions. Experimental results with varying degrees of building label noise demonstrate the robustness of AIO2. Source code will be available at https://github.com/zhu-xlab/AIO2.git.
Feature Guided Masked Autoencoder for Self-supervised Learning in Remote Sensing
Oct 28, 2023
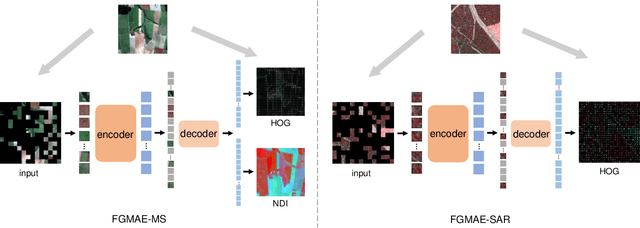


Self-supervised learning guided by masked image modelling, such as Masked AutoEncoder (MAE), has attracted wide attention for pretraining vision transformers in remote sensing. However, MAE tends to excessively focus on pixel details, thereby limiting the model's capacity for semantic understanding, in particular for noisy SAR images. In this paper, we explore spectral and spatial remote sensing image features as improved MAE-reconstruction targets. We first conduct a study on reconstructing various image features, all performing comparably well or better than raw pixels. Based on such observations, we propose Feature Guided Masked Autoencoder (FG-MAE): reconstructing a combination of Histograms of Oriented Graidents (HOG) and Normalized Difference Indices (NDI) for multispectral images, and reconstructing HOG for SAR images. Experimental results on three downstream tasks illustrate the effectiveness of FG-MAE with a particular boost for SAR imagery. Furthermore, we demonstrate the well-inherited scalability of FG-MAE and release a first series of pretrained vision transformers for medium resolution SAR and multispectral images.
DeCUR: decoupling common & unique representations for multimodal self-supervision
Sep 15, 2023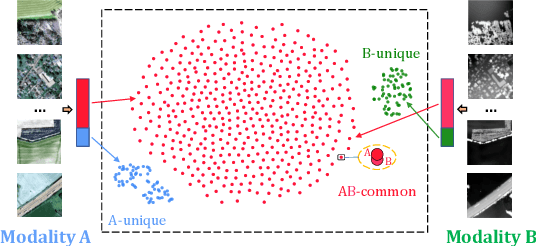


The increasing availability of multi-sensor data sparks interest in multimodal self-supervised learning. However, most existing approaches learn only common representations across modalities while ignoring intra-modal training and modality-unique representations. We propose Decoupling Common and Unique Representations (DeCUR), a simple yet effective method for multimodal self-supervised learning. By distinguishing inter- and intra-modal embeddings, DeCUR is trained to integrate complementary information across different modalities. We evaluate DeCUR in three common multimodal scenarios (radar-optical, RGB-elevation, and RGB-depth), and demonstrate its consistent benefits on scene classification and semantic segmentation downstream tasks. Notably, we get straightforward improvements by transferring our pretrained backbones to state-of-the-art supervised multimodal methods without any hyperparameter tuning. Furthermore, we conduct a comprehensive explainability analysis to shed light on the interpretation of common and unique features in our multimodal approach. Codes are available at \url{https://github.com/zhu-xlab/DeCUR}.
Deep Semantic Model Fusion for Ancient Agricultural Terrace Detection
Aug 04, 2023

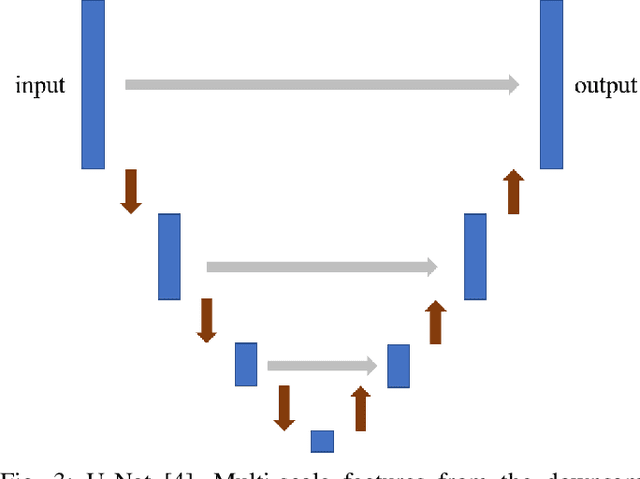
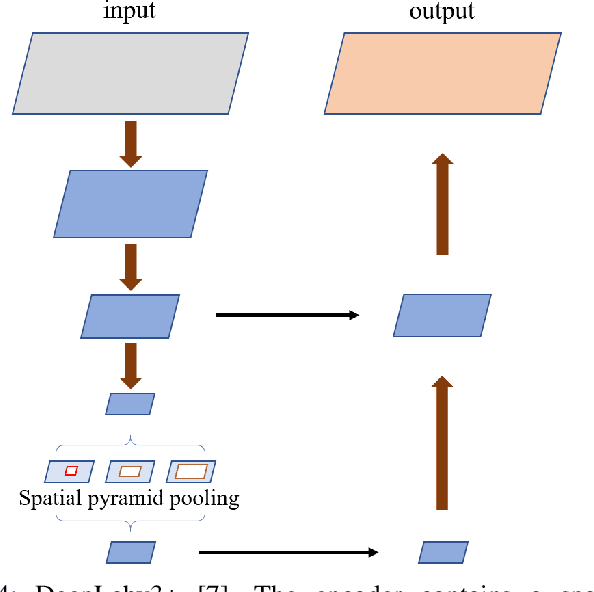
Discovering ancient agricultural terraces in desert regions is important for the monitoring of long-term climate changes on the Earth's surface. However, traditional ground surveys are both costly and limited in scale. With the increasing accessibility of aerial and satellite data, machine learning techniques bear large potential for the automatic detection and recognition of archaeological landscapes. In this paper, we propose a deep semantic model fusion method for ancient agricultural terrace detection. The input data includes aerial images and LiDAR generated terrain features in the Negev desert. Two deep semantic segmentation models, namely DeepLabv3+ and UNet, with EfficientNet backbone, are trained and fused to provide segmentation maps of ancient terraces and walls. The proposed method won the first prize in the International AI Archaeology Challenge. Codes are available at https://github.com/wangyi111/international-archaeology-ai-challenge.
Semi-Supervised Learning for hyperspectral images by non parametrically predicting view assignment
Jun 19, 2023


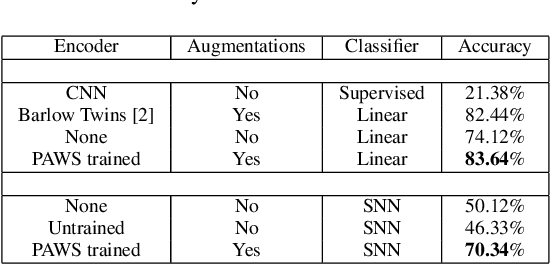
Hyperspectral image (HSI) classification is gaining a lot of momentum in present time because of high inherent spectral information within the images. However, these images suffer from the problem of curse of dimensionality and usually require a large number samples for tasks such as classification, especially in supervised setting. Recently, to effectively train the deep learning models with minimal labelled samples, the unlabeled samples are also being leveraged in self-supervised and semi-supervised setting. In this work, we leverage the idea of semi-supervised learning to assist the discriminative self-supervised pretraining of the models. The proposed method takes different augmented views of the unlabeled samples as input and assigns them the same pseudo-label corresponding to the labelled sample from the downstream task. We train our model on two HSI datasets, namely Houston dataset (from data fusion contest, 2013) and Pavia university dataset, and show that the proposed approach performs better than self-supervised approach and supervised training.
DeepLCZChange: A Remote Sensing Deep Learning Model Architecture for Urban Climate Resilience
Jun 09, 2023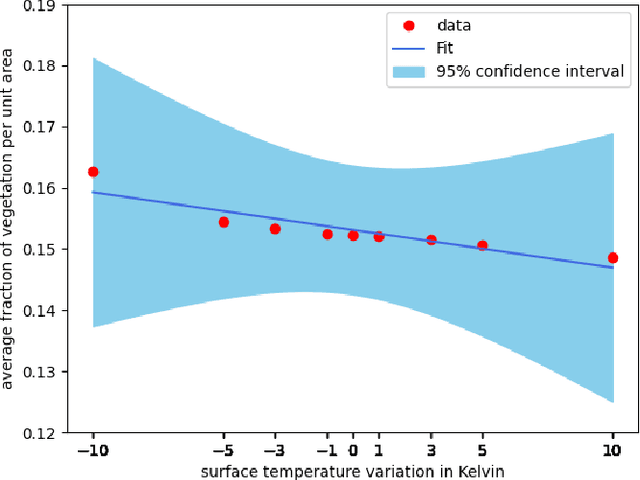
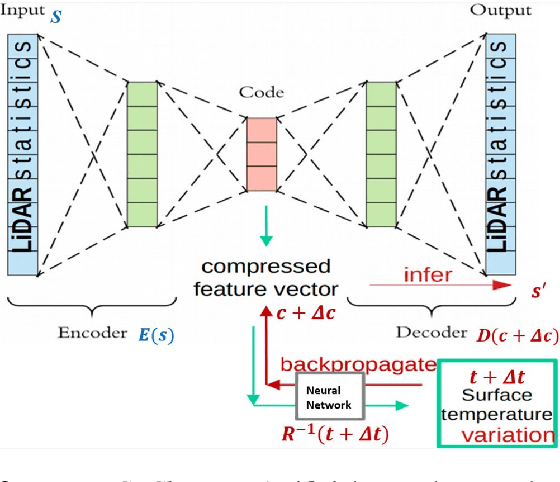
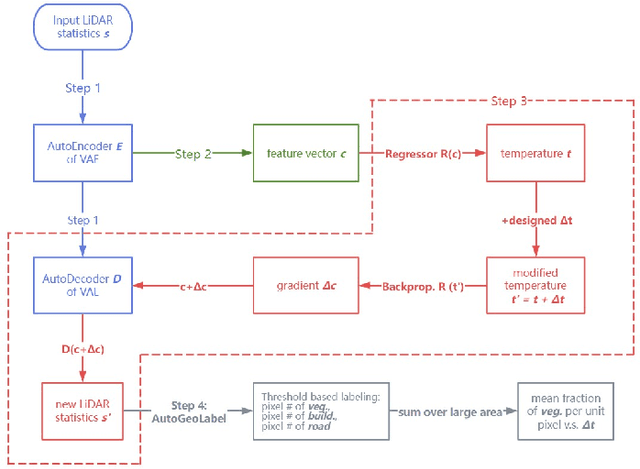

Urban land use structures impact local climate conditions of metropolitan areas. To shed light on the mechanism of local climate wrt. urban land use, we present a novel, data-driven deep learning architecture and pipeline, DeepLCZChange, to correlate airborne LiDAR data statistics with the Landsat 8 satellite's surface temperature product. A proof-of-concept numerical experiment utilizes corresponding remote sensing data for the city of New York to verify the cooling effect of urban forests.
SSL4EO-S12: A Large-Scale Multi-Modal, Multi-Temporal Dataset for Self-Supervised Learning in Earth Observation
Nov 13, 2022

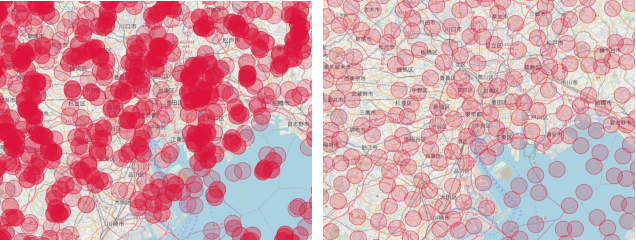

Self-supervised pre-training bears potential to generate expressive representations without human annotation. Most pre-training in Earth observation (EO) are based on ImageNet or medium-size, labeled remote sensing (RS) datasets. We share an unlabeled RS dataset SSL4EO-S12 (Self-Supervised Learning for Earth Observation - Sentinel-1/2) to assemble a large-scale, global, multimodal, and multi-seasonal corpus of satellite imagery from the ESA Sentinel-1 \& -2 satellite missions. For EO applications we demonstrate SSL4EO-S12 to succeed in self-supervised pre-training for a set of methods: MoCo-v2, DINO, MAE, and data2vec. Resulting models yield downstream performance close to, or surpassing accuracy measures of supervised learning. In addition, pre-training on SSL4EO-S12 excels compared to existing datasets. We make openly available the dataset, related source code, and pre-trained models at https://github.com/zhu-xlab/SSL4EO-S12.
Self-supervised Learning in Remote Sensing: A Review
Jun 27, 2022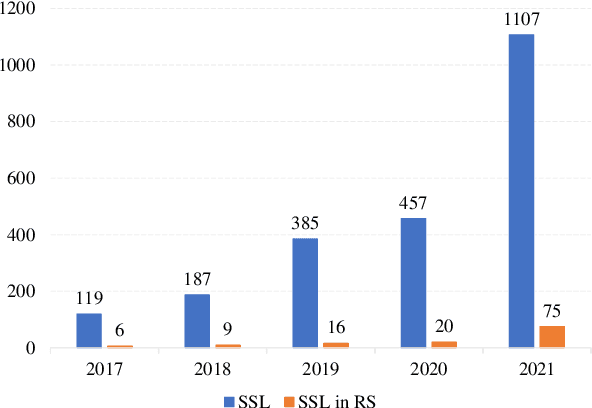
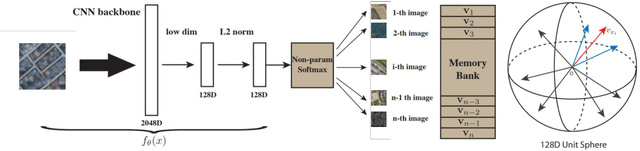
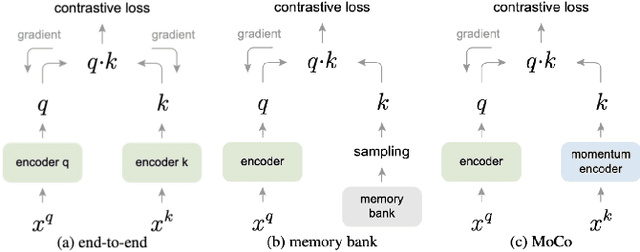

In deep learning research, self-supervised learning (SSL) has received great attention triggering interest within both the computer vision and remote sensing communities. While there has been a big success in computer vision, most of the potential of SSL in the domain of earth observation remains locked. In this paper, we provide an introduction to, and a review of the concepts and latest developments in SSL for computer vision in the context of remote sensing. Further, we provide a preliminary benchmark of modern SSL algorithms on popular remote sensing datasets, verifying the potential of SSL in remote sensing and providing an extended study on data augmentations. Finally, we identify a list of promising directions of future research in SSL for earth observation (SSL4EO) to pave the way for fruitful interaction of both domains.
Monitoring Urban Forests from Auto-Generated Segmentation Maps
Jun 14, 2022


We present and evaluate a weakly-supervised methodology to quantify the spatio-temporal distribution of urban forests based on remotely sensed data with close-to-zero human interaction. Successfully training machine learning models for semantic segmentation typically depends on the availability of high-quality labels. We evaluate the benefit of high-resolution, three-dimensional point cloud data (LiDAR) as source of noisy labels in order to train models for the localization of trees in orthophotos. As proof of concept we sense Hurricane Sandy's impact on urban forests in Coney Island, New York City (NYC) and reference it to less impacted urban space in Brooklyn, NYC.
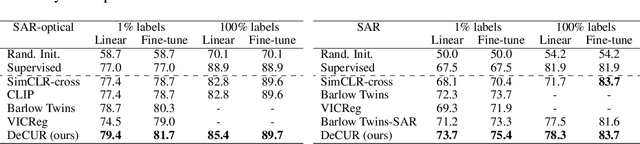
Self-supervised Vision Transformers for Joint SAR-optical Representation Learning
Apr 11, 2022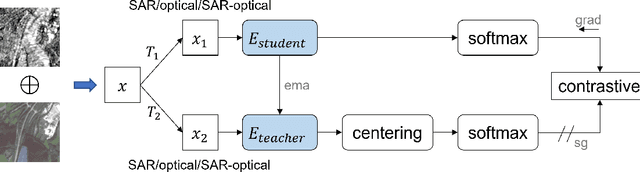
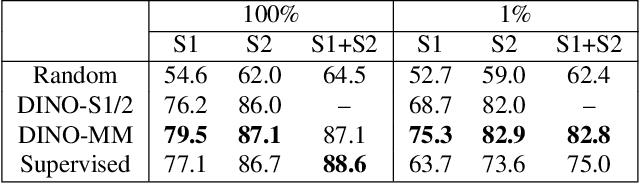
Self-supervised learning (SSL) has attracted much interest in remote sensing and earth observation due to its ability to learn task-agnostic representations without human annotation. While most of the existing SSL works in remote sensing utilize ConvNet backbones and focus on a single modality, we explore the potential of vision transformers (ViTs) for joint SAR-optical representation learning. Based on DINO, a state-of-the-art SSL algorithm that distills knowledge from two augmented views of an input image, we combine SAR and optical imagery by concatenating all channels to a unified input. Subsequently, we randomly mask out channels of one modality as a data augmentation strategy. While training, the model gets fed optical-only, SAR-only, and SAR-optical image pairs learning both inner- and intra-modality representations. Experimental results employing the BigEarthNet-MM dataset demonstrate the benefits of both, the ViT backbones and the proposed multimodal SSL algorithm DINO-MM.