 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCorinna Cortes
Differentially Private Domain Adaptation with Theoretical Guarantees
Jun 15, 2023
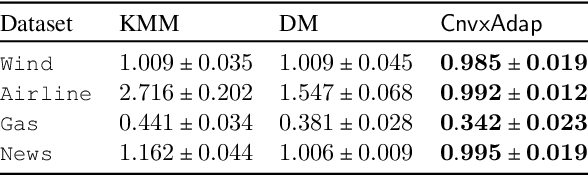
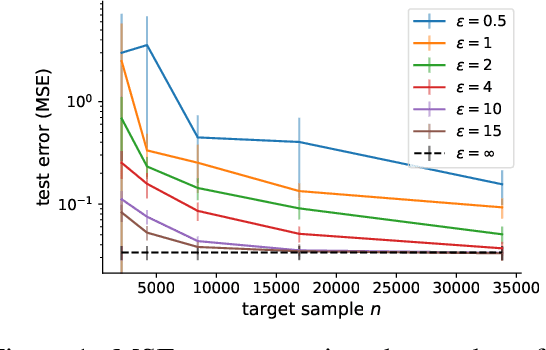

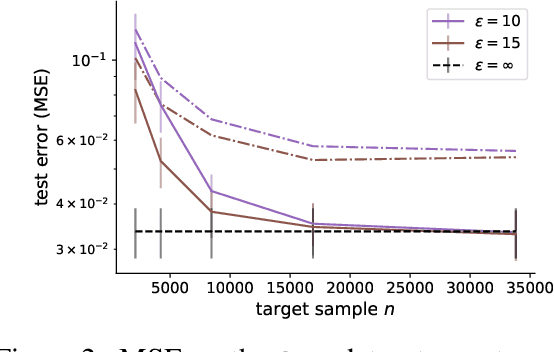
In many applications, the labeled data at the learner's disposal is subject to privacy constraints and is relatively limited. To derive a more accurate predictor for the target domain, it is often beneficial to leverage publicly available labeled data from an alternative domain, somewhat close to the target domain. This is the modern problem of supervised domain adaptation from a public source to a private target domain. We present two $(\epsilon, \delta)$-differentially private adaptation algorithms for supervised adaptation, for which we make use of a general optimization problem, recently shown to benefit from favorable theoretical learning guarantees. Our first algorithm is designed for regression with linear predictors and shown to solve a convex optimization problem. Our second algorithm is a more general solution for loss functions that may be non-convex but Lipschitz and smooth. While our main objective is a theoretical analysis, we also report the results of several experiments first demonstrating that the non-private versions of our algorithms outperform adaptation baselines and next showing that, for larger values of the target sample size or $\epsilon$, the performance of our private algorithms remains close to that of the non-private formulation.
Best-Effort Adaptation
May 10, 2023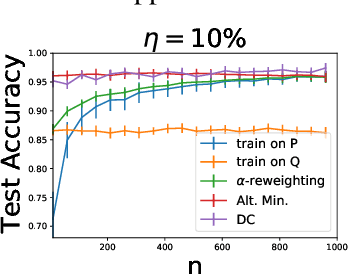
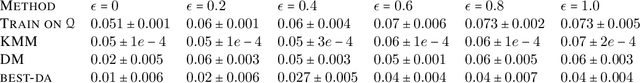
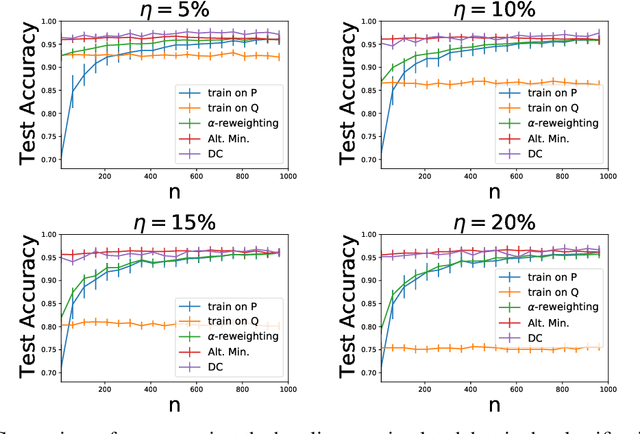
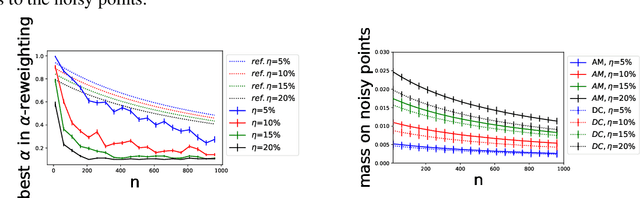
We study a problem of best-effort adaptation motivated by several applications and considerations, which consists of determining an accurate predictor for a target domain, for which a moderate amount of labeled samples are available, while leveraging information from another domain for which substantially more labeled samples are at one's disposal. We present a new and general discrepancy-based theoretical analysis of sample reweighting methods, including bounds holding uniformly over the weights. We show how these bounds can guide the design of learning algorithms that we discuss in detail. We further show that our learning guarantees and algorithms provide improved solutions for standard domain adaptation problems, for which few labeled data or none are available from the target domain. We finally report the results of a series of experiments demonstrating the effectiveness of our best-effort adaptation and domain adaptation algorithms, as well as comparisons with several baselines. We also discuss how our analysis can benefit the design of principled solutions for fine-tuning.
Inconsistency in Conference Peer Review: Revisiting the 2014 NeurIPS Experiment
Sep 20, 2021

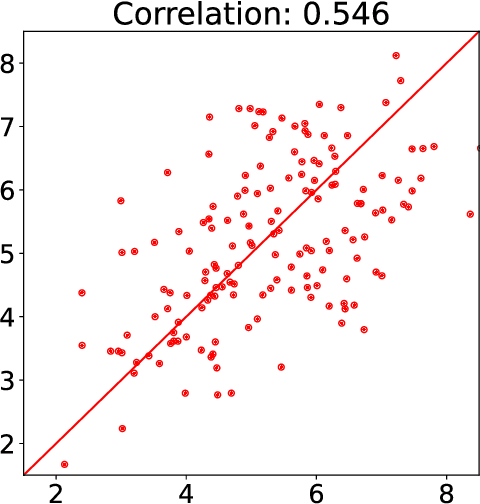
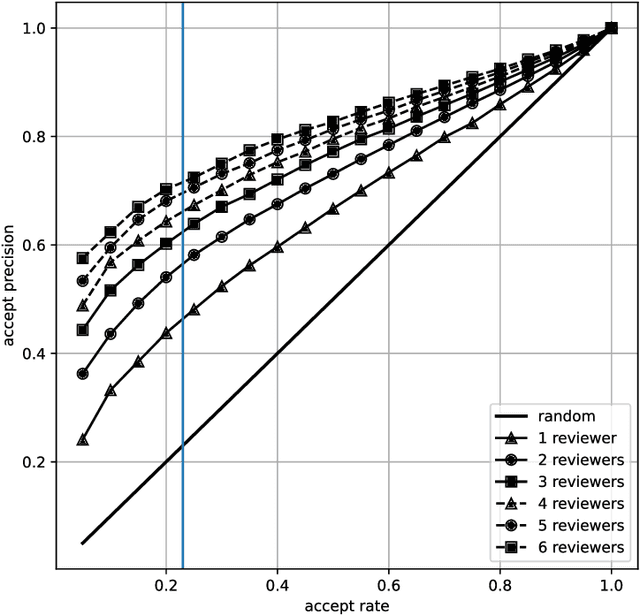
In this paper we revisit the 2014 NeurIPS experiment that examined inconsistency in conference peer review. We determine that 50\% of the variation in reviewer quality scores was subjective in origin. Further, with seven years passing since the experiment we find that for \emph{accepted} papers, there is no correlation between quality scores and impact of the paper as measured as a function of citation count. We trace the fate of rejected papers, recovering where these papers were eventually published. For these papers we find a correlation between quality scores and impact. We conclude that the reviewing process for the 2014 conference was good for identifying poor papers, but poor for identifying good papers. We give some suggestions for improving the reviewing process but also warn against removing the subjective element. Finally, we suggest that the real conclusion of the experiment is that the community should place less onus on the notion of `top-tier conference publications' when assessing the quality of individual researchers. For NeurIPS 2021, the PCs are repeating the experiment, as well as conducting new ones.
Multiple-Source Adaptation with Domain Classifiers
Aug 25, 2020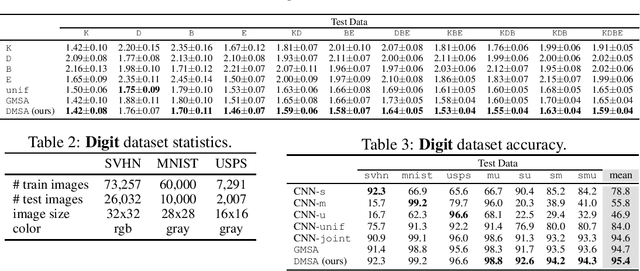
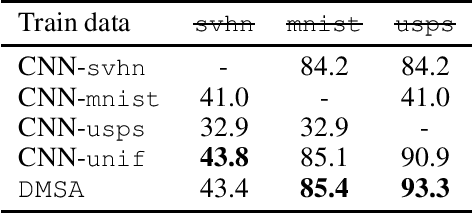
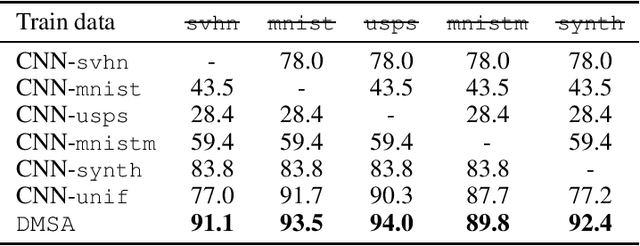
We consider the multiple-source adaptation (MSA) problem and improve a previously proposed MSA solution, where accurate density estimation per domain is required to obtain favorable learning guarantees. In this work, we replace the difficult task of density estimation per domain with a much easier task of domain classification, and show that the two solutions are equivalent given the true densities and domain classifier, yet the newer approach benefits from more favorable guarantees when densities and domain classifier are estimated from finite samples. Our experiments with real-world applications demonstrate that the new discriminative MSA solution outperforms the previous solution with density estimation, as well as other domain adaptation baselines.
Beyond Individual and Group Fairness
Aug 21, 2020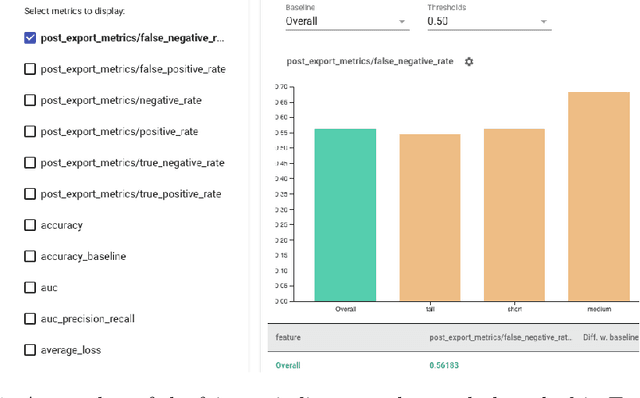


We present a new data-driven model of fairness that, unlike existing static definitions of individual or group fairness is guided by the unfairness complaints received by the system. Our model supports multiple fairness criteria and takes into account their potential incompatibilities. We consider both a stochastic and an adversarial setting of our model. In the stochastic setting, we show that our framework can be naturally cast as a Markov Decision Process with stochastic losses, for which we give efficient vanishing regret algorithmic solutions. In the adversarial setting, we design efficient algorithms with competitive ratio guarantees. We also report the results of experiments with our algorithms and the stochastic framework on artificial datasets, to demonstrate their effectiveness empirically.
Relative Deviation Margin Bounds
Jun 26, 2020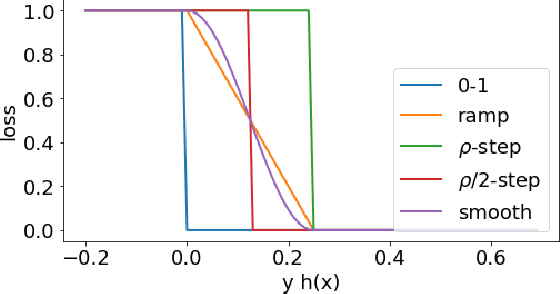
We present a series of new and more favorable margin-based learning guarantees that depend on the empirical margin loss of a predictor. We give two types of learning bounds, both data-dependent ones and bounds valid for general families, in terms of the Rademacher complexity or the empirical $\ell_\infty$ covering number of the hypothesis set used. We also briefly highlight several applications of these bounds and discuss their connection with existing results.
Adaptive Region-Based Active Learning
Feb 18, 2020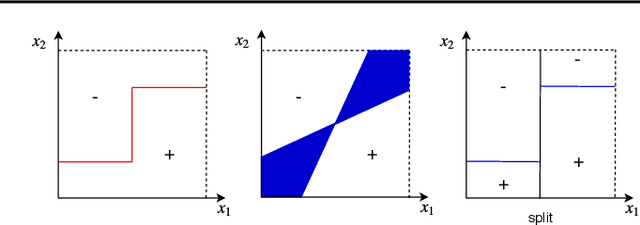
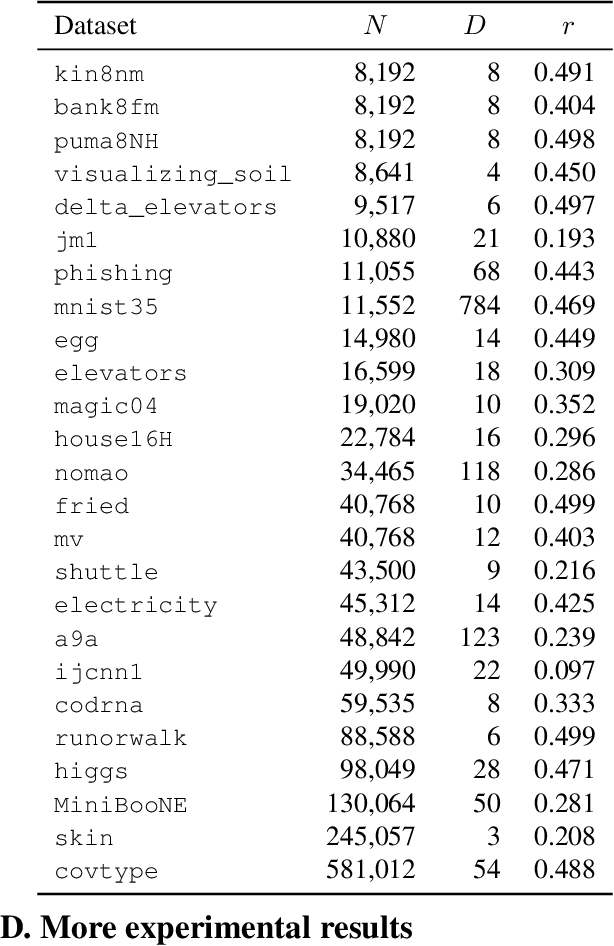
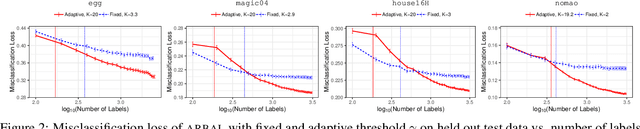
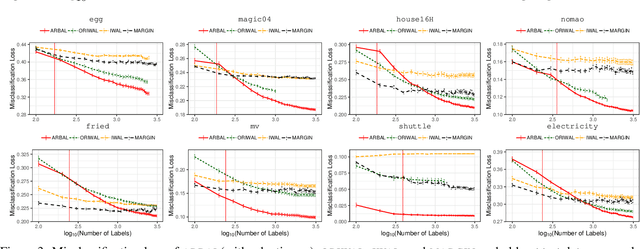
We present a new active learning algorithm that adaptively partitions the input space into a finite number of regions, and subsequently seeks a distinct predictor for each region, both phases actively requesting labels. We prove theoretical guarantees for both the generalization error and the label complexity of our algorithm, and analyze the number of regions defined by the algorithm under some mild assumptions. We also report the results of an extensive suite of experiments on several real-world datasets demonstrating substantial empirical benefits over existing single-region and non-adaptive region-based active learning baselines.
Learning GANs and Ensembles Using Discrepancy
Nov 06, 2019



Generative adversarial networks (GANs) generate data based on minimizing a divergence between two distributions. The choice of that divergence is therefore critical. We argue that the divergence must take into account the hypothesis set and the loss function used in a subsequent learning task, where the data generated by a GAN serves for training. Taking that structural information into account is also important to derive generalization guarantees. Thus, we propose to use the discrepancy measure, which was originally introduced for the closely related problem of domain adaptation and which precisely takes into account the hypothesis set and the loss function. We show that discrepancy admits favorable properties for training GANs and prove explicit generalization guarantees. We present efficient algorithms using discrepancy for two tasks: training a GAN directly, namely DGAN, and mixing previously trained generative models, namely EDGAN. Our experiments on toy examples and several benchmark datasets show that DGAN is competitive with other GANs and that EDGAN outperforms existing GAN ensembles, such as AdaGAN.
AdaNet: A Scalable and Flexible Framework for Automatically Learning Ensembles
Apr 30, 2019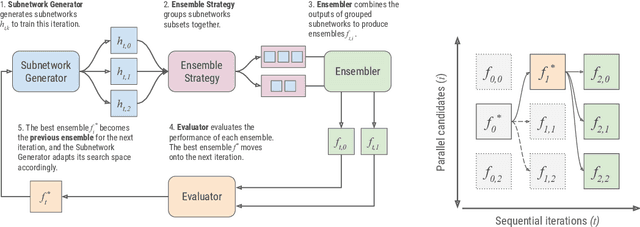
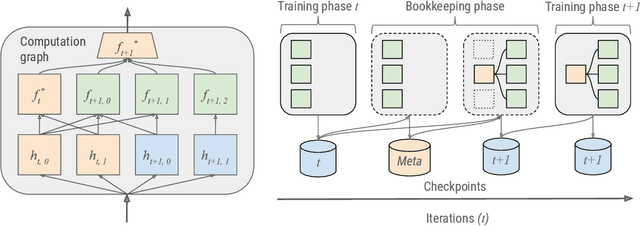
AdaNet is a lightweight TensorFlow-based (Abadi et al., 2015) framework for automatically learning high-quality ensembles with minimal expert intervention. Our framework is inspired by the AdaNet algorithm (Cortes et al., 2017) which learns the structure of a neural network as an ensemble of subnetworks. We designed it to: (1) integrate with the existing TensorFlow ecosystem, (2) offer sensible default search spaces to perform well on novel datasets, (3) present a flexible API to utilize expert information when available, and (4) efficiently accelerate training with distributed CPU, GPU, and TPU hardware. The code is open-source and available at: https://github.com/tensorflow/adanet.
Online Non-Additive Path Learning under Full and Partial Information
Sep 18, 2018
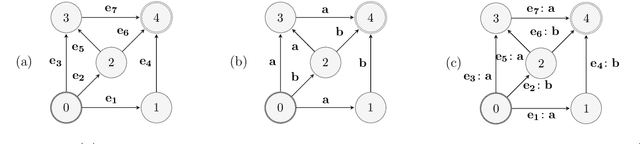
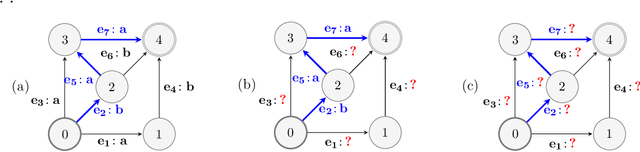

We study the problem of online path learning with non-additive gains, which is a central problem appearing in several applications, including ensemble structured prediction. We present new online algorithms for path learning with non-additive count-based gains for the three settings of full information, semi-bandit and full bandit. These algorithms admit very favorable regret guarantees and their guarantees can be viewed as the non-additive counterparts to the best known guarantees in the additive case. A key component of our algorithms is the definition and computation of an intermediate context-dependent automaton that enables us to use existing algorithms designed for additive gains. We further apply our methods to the important application of ensemble structured prediction. Finally, beyond count-based gains, we give an efficient implementation of the EXP3 algorithm for the full bandit setting with an arbitrary (non-additive) gain.