 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCornelia Fermuller
Interactive-FAR:Interactive, Fast and Adaptable Routing for Navigation Among Movable Obstacles in Complex Unknown Environments
Apr 11, 2024
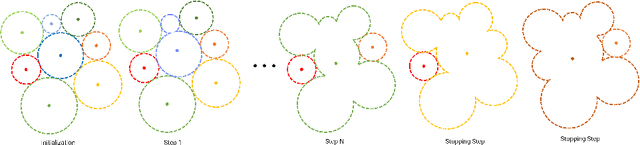
This paper introduces a real-time algorithm for navigating complex unknown environments cluttered with movable obstacles. Our algorithm achieves fast, adaptable routing by actively attempting to manipulate obstacles during path planning and adjusting the global plan from sensor feedback. The main contributions include an improved dynamic Directed Visibility Graph (DV-graph) for rapid global path searching, a real-time interaction planning method that adapts online from new sensory perceptions, and a comprehensive framework designed for interactive navigation in complex unknown or partially known environments. Our algorithm is capable of replanning the global path in several milliseconds. It can also attempt to move obstacles, update their affordances, and adapt strategies accordingly. Extensive experiments validate that our algorithm reduces the travel time by 33%, achieves up to 49% higher path efficiency, and runs faster than traditional methods by orders of magnitude in complex environments. It has been demonstrated to be the most efficient solution in terms of speed and efficiency for interactive navigation in environments of such complexity. We also open-source our code in the docker demo to facilitate future research.
TimeRewind: Rewinding Time with Image-and-Events Video Diffusion
Mar 20, 2024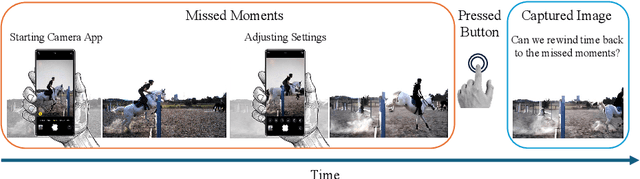

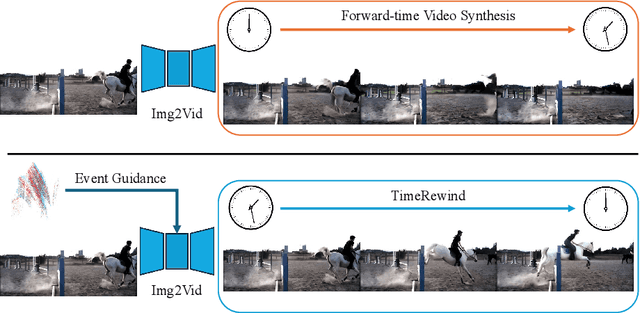
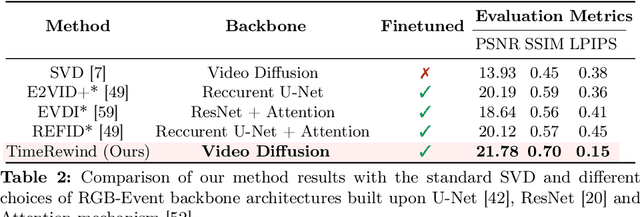
This paper addresses the novel challenge of ``rewinding'' time from a single captured image to recover the fleeting moments missed just before the shutter button is pressed. This problem poses a significant challenge in computer vision and computational photography, as it requires predicting plausible pre-capture motion from a single static frame, an inherently ill-posed task due to the high degree of freedom in potential pixel movements. We overcome this challenge by leveraging the emerging technology of neuromorphic event cameras, which capture motion information with high temporal resolution, and integrating this data with advanced image-to-video diffusion models. Our proposed framework introduces an event motion adaptor conditioned on event camera data, guiding the diffusion model to generate videos that are visually coherent and physically grounded in the captured events. Through extensive experimentation, we demonstrate the capability of our approach to synthesize high-quality videos that effectively ``rewind'' time, showcasing the potential of combining event camera technology with generative models. Our work opens new avenues for research at the intersection of computer vision, computational photography, and generative modeling, offering a forward-thinking solution to capturing missed moments and enhancing future consumer cameras and smartphones. Please see the project page at https://timerewind.github.io/ for video results and code release.
NatSGD: A Dataset with Speech, Gestures, and Demonstrations for Robot Learning in Natural Human-Robot Interaction
Mar 04, 2024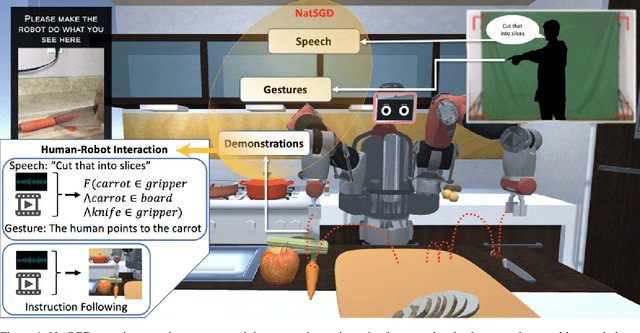

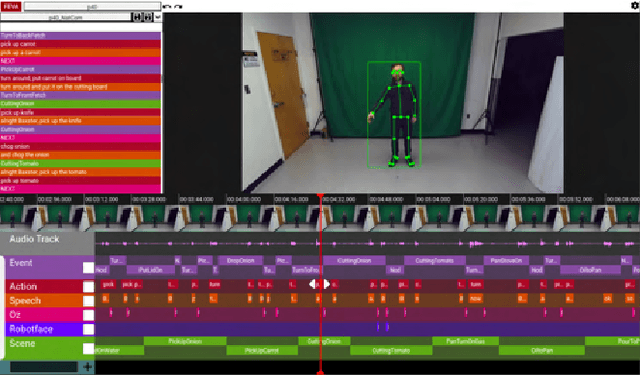
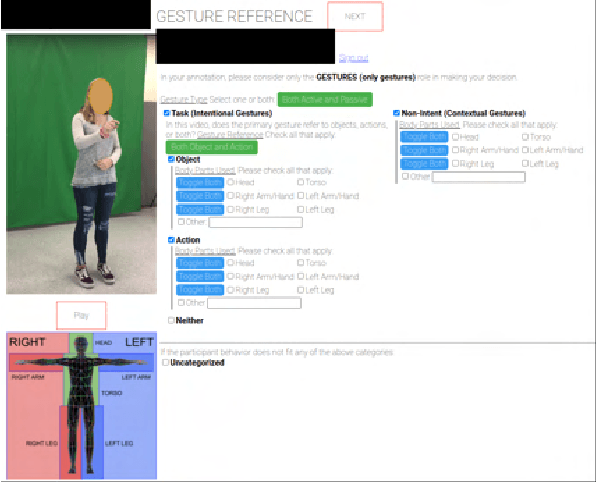
Recent advancements in multimodal Human-Robot Interaction (HRI) datasets have highlighted the fusion of speech and gesture, expanding robots' capabilities to absorb explicit and implicit HRI insights. However, existing speech-gesture HRI datasets often focus on elementary tasks, like object pointing and pushing, revealing limitations in scaling to intricate domains and prioritizing human command data over robot behavior records. To bridge these gaps, we introduce NatSGD, a multimodal HRI dataset encompassing human commands through speech and gestures that are natural, synchronized with robot behavior demonstrations. NatSGD serves as a foundational resource at the intersection of machine learning and HRI research, and we demonstrate its effectiveness in training robots to understand tasks through multimodal human commands, emphasizing the significance of jointly considering speech and gestures. We have released our dataset, simulator, and code to facilitate future research in human-robot interaction system learning; access these resources at https://www.snehesh.com/natsgd/
Event-based Vision for Early Prediction of Manipulation Actions
Jul 26, 2023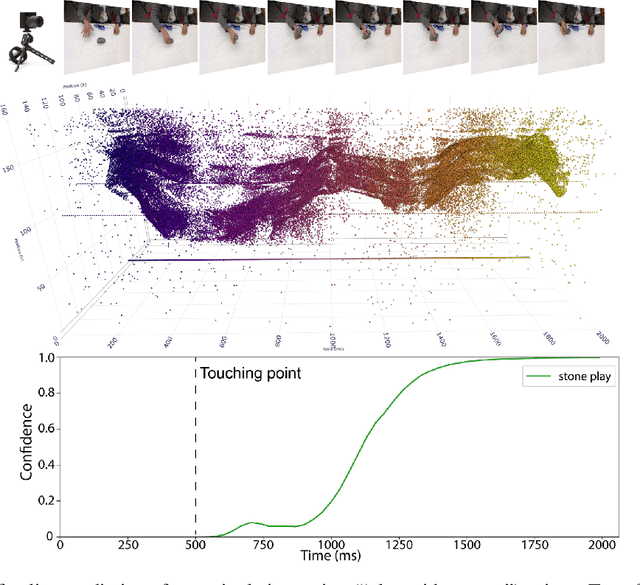



Neuromorphic visual sensors are artificial retinas that output sequences of asynchronous events when brightness changes occur in the scene. These sensors offer many advantages including very high temporal resolution, no motion blur and smart data compression ideal for real-time processing. In this study, we introduce an event-based dataset on fine-grained manipulation actions and perform an experimental study on the use of transformers for action prediction with events. There is enormous interest in the fields of cognitive robotics and human-robot interaction on understanding and predicting human actions as early as possible. Early prediction allows anticipating complex stages for planning, enabling effective and real-time interaction. Our Transformer network uses events to predict manipulation actions as they occur, using online inference. The model succeeds at predicting actions early on, building up confidence over time and achieving state-of-the-art classification. Moreover, the attention-based transformer architecture allows us to study the role of the spatio-temporal patterns selected by the model. Our experiments show that the Transformer network captures action dynamic features outperforming video-based approaches and succeeding with scenarios where the differences between actions lie in very subtle cues. Finally, we release the new event dataset, which is the first in the literature for manipulation action recognition. Code will be available at https://github.com/DaniDeniz/EventVisionTransformer.
Considerations for Minimizing Data Collection Biases for Eliciting Natural Behavior in Human-Robot Interaction
Apr 19, 2023
Many of us researchers take extra measures to control for known-unknowns. However, unknown-unknowns can, at best, be negligible, but otherwise, they could produce unreliable data that might have dire consequences in real-life downstream applications. Human-Robot Interaction standards informed by empirical data could save us time and effort and provide us with the path toward the robots of the future. To this end, we share some of our pilot studies, lessons learned, and how they affected the outcome of our experiments. While these aspects might not be publishable in themselves, we hope our work might save time and effort for other researchers towards their research and serve as additional considerations for discussion at the workshop.
Therbligs in Action: Video Understanding through Motion Primitives
Apr 06, 2023



In this paper we introduce a rule-based, compositional, and hierarchical modeling of action using Therbligs as our atoms. Introducing these atoms provides us with a consistent, expressive, contact-centered representation of action. Over the atoms we introduce a differentiable method of rule-based reasoning to regularize for logical consistency. Our approach is complementary to other approaches in that the Therblig-based representations produced by our architecture augment rather than replace existing architectures' representations. We release the first Therblig-centered annotations over two popular video datasets - EPIC Kitchens 100 and 50-Salads. We also broadly demonstrate benefits to adopting Therblig representations through evaluation on the following tasks: action segmentation, action anticipation, and action recognition - observing an average 10.5\%/7.53\%/6.5\% relative improvement, respectively, over EPIC Kitchens and an average 8.9\%/6.63\%/4.8\% relative improvement, respectively, over 50 Salads. Code and data will be made publicly available.
Gluing Neural Networks Symbolically Through Hyperdimensional Computing
May 31, 2022



Hyperdimensional Computing affords simple, yet powerful operations to create long Hyperdimensional Vectors (hypervectors) that can efficiently encode information, be used for learning, and are dynamic enough to be modified on the fly. In this paper, we explore the notion of using binary hypervectors to directly encode the final, classifying output signals of neural networks in order to fuse differing networks together at the symbolic level. This allows multiple neural networks to work together to solve a problem, with little additional overhead. Output signals just before classification are encoded as hypervectors and bundled together through consensus summation to train a classification hypervector. This process can be performed iteratively and even on single neural networks by instead making a consensus of multiple classification hypervectors. We find that this outperforms the state of the art, or is on a par with it, while using very little overhead, as hypervector operations are extremely fast and efficient in comparison to the neural networks. This consensus process can learn online and even grow or lose models in real time. Hypervectors act as memories that can be stored, and even further bundled together over time, affording life long learning capabilities. Additionally, this consensus structure inherits the benefits of Hyperdimensional Computing, without sacrificing the performance of modern Machine Learning. This technique can be extrapolated to virtually any neural model, and requires little modification to employ - one simply requires recording the output signals of networks when presented with a testing example.
Forecasting Action through Contact Representations from First Person Video
Feb 01, 2021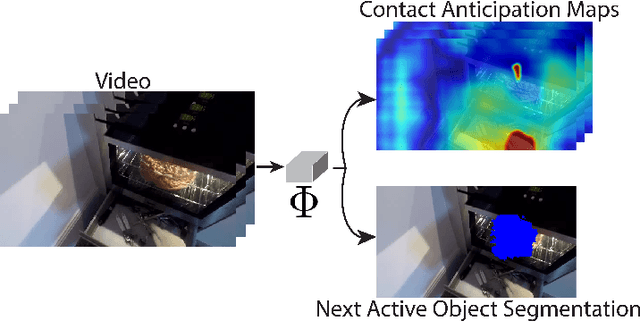
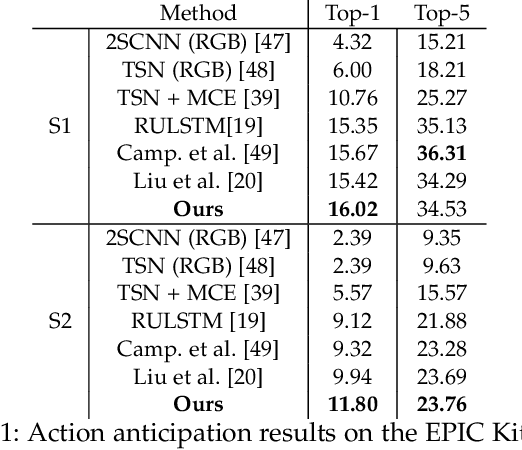
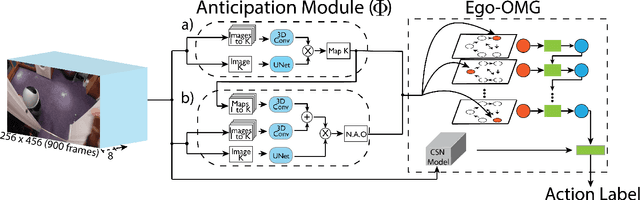

Human actions involving hand manipulations are structured according to the making and breaking of hand-object contact, and human visual understanding of action is reliant on anticipation of contact as is demonstrated by pioneering work in cognitive science. Taking inspiration from this, we introduce representations and models centered on contact, which we then use in action prediction and anticipation. We annotate a subset of the EPIC Kitchens dataset to include time-to-contact between hands and objects, as well as segmentations of hands and objects. Using these annotations we train the Anticipation Module, a module producing Contact Anticipation Maps and Next Active Object Segmentations - novel low-level representations providing temporal and spatial characteristics of anticipated near future action. On top of the Anticipation Module we apply Egocentric Object Manipulation Graphs (Ego-OMG), a framework for action anticipation and prediction. Ego-OMG models longer term temporal semantic relations through the use of a graph modeling transitions between contact delineated action states. Use of the Anticipation Module within Ego-OMG produces state-of-the-art results, achieving 1st and 2nd place on the unseen and seen test sets, respectively, of the EPIC Kitchens Action Anticipation Challenge, and achieving state-of-the-art results on the tasks of action anticipation and action prediction over EPIC Kitchens. We perform ablation studies over characteristics of the Anticipation Module to evaluate their utility.
A Deep 2-Dimensional Dynamical Spiking Neuronal Network for Temporal Encoding trained with STDP
Sep 01, 2020



The brain is known to be a highly complex, asynchronous dynamical system that is highly tailored to encode temporal information. However, recent deep learning approaches to not take advantage of this temporal coding. Spiking Neural Networks (SNNs) can be trained using biologically-realistic learning mechanisms, and can have neuronal activation rules that are biologically relevant. This type of network is also structured fundamentally around accepting temporal information through a time-decaying voltage update, a kind of input that current rate-encoding networks have difficulty with. Here we show that a large, deep layered SNN with dynamical, chaotic activity mimicking the mammalian cortex with biologically-inspired learning rules, such as STDP, is capable of encoding information from temporal data. We argue that the randomness inherent in the network weights allow the neurons to form groups that encode the temporal data being inputted after self-organizing with STDP. We aim to show that precise timing of input stimulus is critical in forming synchronous neural groups in a layered network. We analyze the network in terms of network entropy as a metric of information transfer. We hope to tackle two problems at once: the creation of artificial temporal neural systems for artificial intelligence, as well as solving coding mechanisms in the brain.
MOMS with Events: Multi-Object Motion Segmentation With Monocular Event Cameras
Jun 11, 2020
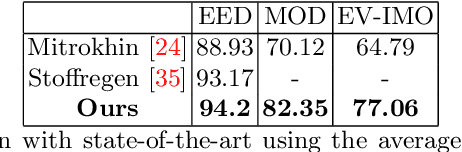
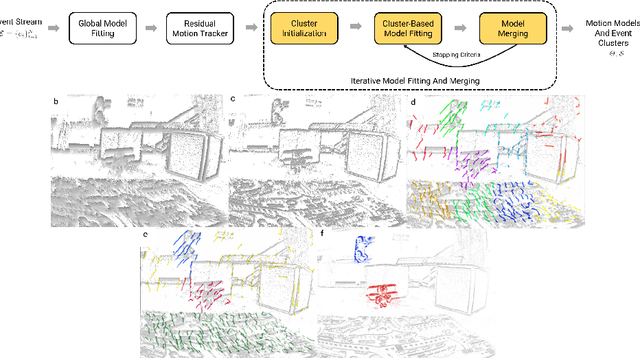
Segmentation of moving objects in dynamic scenes is a key process in scene understanding for both navigation and video recognition tasks. Without prior knowledge of the object structure and motion, the problem is very challenging due to the plethora of motion parameters to be estimated while being agnostic to motion blur and occlusions. Event sensors, because of their high temporal resolution, and lack of motion blur, seem well suited for addressing this problem. We propose a solution to multi-object motion segmentation using a combination of classical optimization methods along with deep learning and does not require prior knowledge of the 3D motion and the number and structure of objects. Using the events within a time-interval, the method estimates and compensates for the global rigid motion. Then it segments the scene into multiple motions by iteratively fitting and merging models using input tracked feature regions via alignment based on temporal gradients and contrast measures. The approach was successfully evaluated on both challenging real-world and synthetic scenarios from the EV-IMO, EED, and MOD datasets, and outperforms the state-of-the-art detection rate by as much as 12% achieving a new state-of-the-art average detection rate of 77.06%, 94.2% and 82.35% on the aforementioned datasets.