 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDan Luo
SOS-1K: A Fine-grained Suicide Risk Classification Dataset for Chinese Social Media Analysis
Apr 19, 2024
In the social media, users frequently express personal emotions, a subset of which may indicate potential suicidal tendencies. The implicit and varied forms of expression in internet language complicate accurate and rapid identification of suicidal intent on social media, thus creating challenges for timely intervention efforts. The development of deep learning models for suicide risk detection is a promising solution, but there is a notable lack of relevant datasets, especially in the Chinese context. To address this gap, this study presents a Chinese social media dataset designed for fine-grained suicide risk classification, focusing on indicators such as expressions of suicide intent, methods of suicide, and urgency of timing. Seven pre-trained models were evaluated in two tasks: high and low suicide risk, and fine-grained suicide risk classification on a level of 0 to 10. In our experiments, deep learning models show good performance in distinguishing between high and low suicide risk, with the best model achieving an F1 score of 88.39%. However, the results for fine-grained suicide risk classification were still unsatisfactory, with an weighted F1 score of 50.89%. To address the issues of data imbalance and limited dataset size, we investigated both traditional and advanced, large language model based data augmentation techniques, demonstrating that data augmentation can enhance model performance by up to 4.65% points in F1-score. Notably, the Chinese MentalBERT model, which was pre-trained on psychological domain data, shows superior performance in both tasks. This study provides valuable insights for automatic identification of suicidal individuals, facilitating timely psychological intervention on social media platforms. The source code and data are publicly available.
AI-Enhanced Cognitive Behavioral Therapy: Deep Learning and Large Language Models for Extracting Cognitive Pathways from Social Media Texts
Apr 17, 2024Cognitive Behavioral Therapy (CBT) is an effective technique for addressing the irrational thoughts stemming from mental illnesses, but it necessitates precise identification of cognitive pathways to be successfully implemented in patient care. In current society, individuals frequently express negative emotions on social media on specific topics, often exhibiting cognitive distortions, including suicidal behaviors in extreme cases. Yet, there is a notable absence of methodologies for analyzing cognitive pathways that could aid psychotherapists in conducting effective interventions online. In this study, we gathered data from social media and established the task of extracting cognitive pathways, annotating the data based on a cognitive theoretical framework. We initially categorized the task of extracting cognitive pathways as a hierarchical text classification with four main categories and nineteen subcategories. Following this, we structured a text summarization task to help psychotherapists quickly grasp the essential information. Our experiments evaluate the performance of deep learning and large language models (LLMs) on these tasks. The results demonstrate that our deep learning method achieved a micro-F1 score of 62.34% in the hierarchical text classification task. Meanwhile, in the text summarization task, GPT-4 attained a Rouge-1 score of 54.92 and a Rouge-2 score of 30.86, surpassing the experimental deep learning model's performance. However, it may suffer from an issue of hallucination. We have made all models and codes publicly available to support further research in this field.
Towards a Psychological Generalist AI: A Survey of Current Applications of Large Language Models and Future Prospects
Dec 01, 2023The complexity of psychological principles underscore a significant societal challenge, given the vast social implications of psychological problems. Bridging the gap between understanding these principles and their actual clinical and real-world applications demands rigorous exploration and adept implementation. In recent times, the swift advancement of highly adaptive and reusable artificial intelligence (AI) models has emerged as a promising way to unlock unprecedented capabilities in the realm of psychology. This paper emphasizes the importance of performance validation for these large-scale AI models, emphasizing the need to offer a comprehensive assessment of their verification from diverse perspectives. Moreover, we review the cutting-edge advancements and practical implementations of these expansive models in psychology, highlighting pivotal work spanning areas such as social media analytics, clinical nursing insights, vigilant community monitoring, and the nuanced exploration of psychological theories. Based on our review, we project an acceleration in the progress of psychological fields, driven by these large-scale AI models. These future generalist AI models harbor the potential to substantially curtail labor costs and alleviate social stress. However, this forward momentum will not be without its set of challenges, especially when considering the paradigm changes and upgrades required for medical instrumentation and related applications.
Improving Language Model-Based Zero-Shot Text-to-Speech Synthesis with Multi-Scale Acoustic Prompts
Sep 22, 2023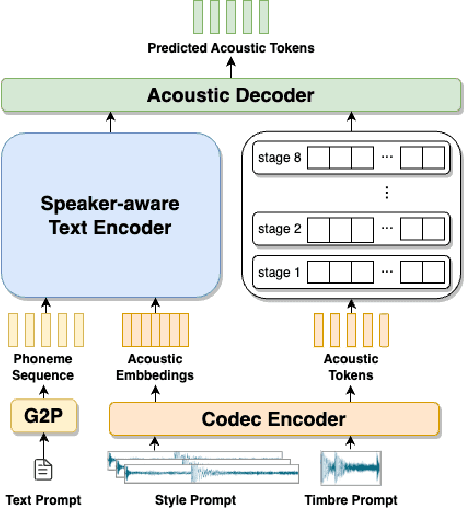
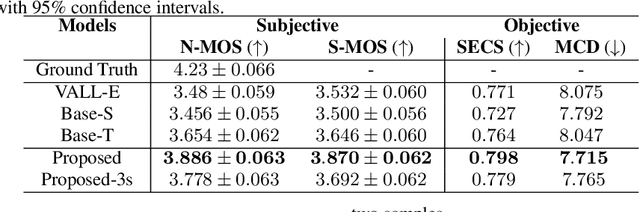
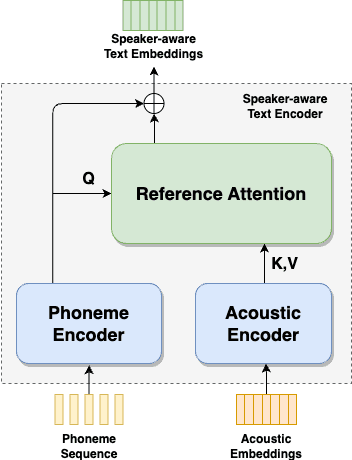
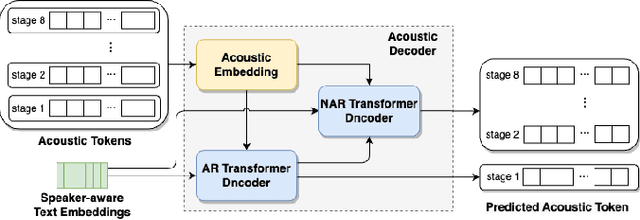
Zero-shot text-to-speech (TTS) synthesis aims to clone any unseen speaker's voice without adaptation parameters. By quantizing speech waveform into discrete acoustic tokens and modeling these tokens with the language model, recent language model-based TTS models show zero-shot speaker adaptation capabilities with only a 3-second acoustic prompt of an unseen speaker. However, they are limited by the length of the acoustic prompt, which makes it difficult to clone personal speaking style. In this paper, we propose a novel zero-shot TTS model with the multi-scale acoustic prompts based on a neural codec language model VALL-E. A speaker-aware text encoder is proposed to learn the personal speaking style at the phoneme-level from the style prompt consisting of multiple sentences. Following that, a VALL-E based acoustic decoder is utilized to model the timbre from the timbre prompt at the frame-level and generate speech. The experimental results show that our proposed method outperforms baselines in terms of naturalness and speaker similarity, and can achieve better performance by scaling out to a longer style prompt.
Evaluating the Efficacy of Supervised Learning vs Large Language Models for Identifying Cognitive Distortions and Suicidal Risks in Chinese Social Media
Sep 07, 2023
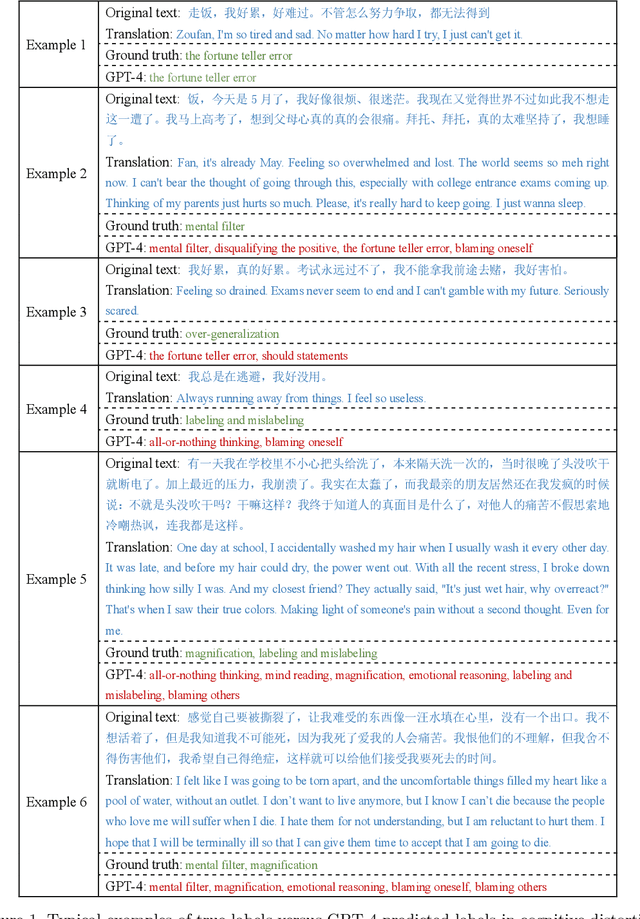
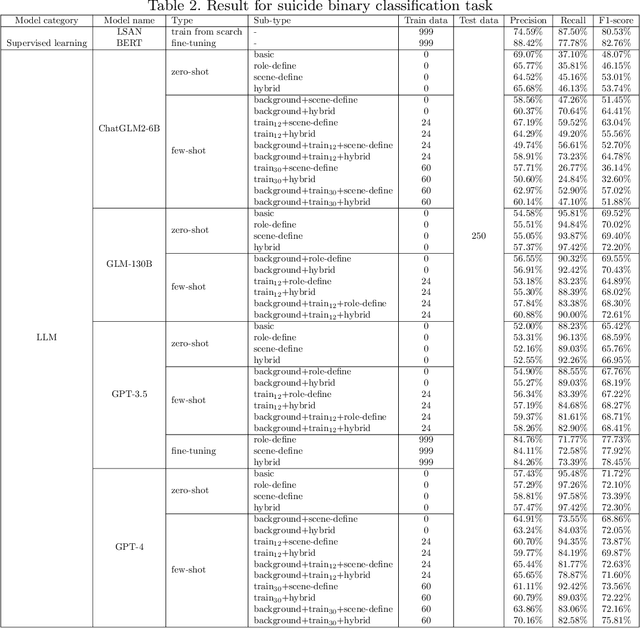

Large language models, particularly those akin to the rapidly progressing GPT series, are gaining traction for their expansive influence. While there is keen interest in their applicability within medical domains such as psychology, tangible explorations on real-world data remain scant. Concurrently, users on social media platforms are increasingly vocalizing personal sentiments; under specific thematic umbrellas, these sentiments often manifest as negative emotions, sometimes escalating to suicidal inclinations. Timely discernment of such cognitive distortions and suicidal risks is crucial to effectively intervene and potentially avert dire circumstances. Our study ventured into this realm by experimenting on two pivotal tasks: suicidal risk and cognitive distortion identification on Chinese social media platforms. Using supervised learning as a baseline, we examined and contrasted the efficacy of large language models via three distinct strategies: zero-shot, few-shot, and fine-tuning. Our findings revealed a discernible performance gap between the large language models and traditional supervised learning approaches, primarily attributed to the models' inability to fully grasp subtle categories. Notably, while GPT-4 outperforms its counterparts in multiple scenarios, GPT-3.5 shows significant enhancement in suicide risk classification after fine-tuning. To our knowledge, this investigation stands as the maiden attempt at gauging large language models on Chinese social media tasks. This study underscores the forward-looking and transformative implications of using large language models in the field of psychology. It lays the groundwork for future applications in psychological research and practice.
Enhancing Psychological Counseling with Large Language Model: A Multifaceted Decision-Support System for Non-Professionals
Aug 29, 2023
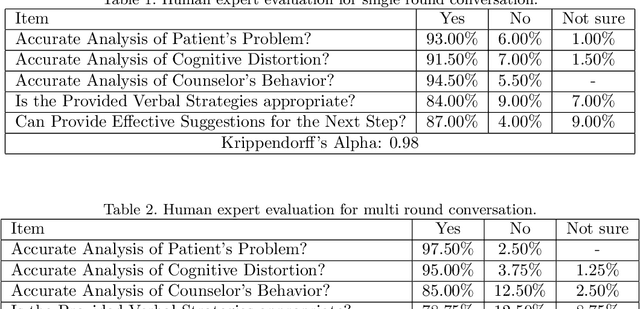

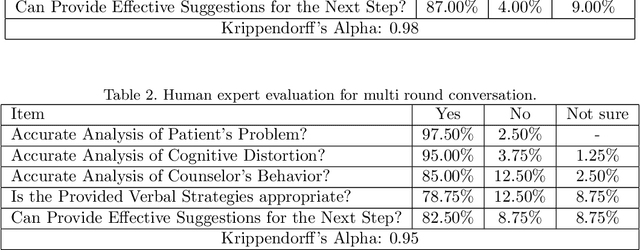
In the contemporary landscape of social media, an alarming number of users express negative emotions, some of which manifest as strong suicidal intentions. This situation underscores a profound need for trained psychological counselors who can enact effective mental interventions. However, the development of these professionals is often an imperative but time-consuming task. Consequently, the mobilization of non-professionals or volunteers in this capacity emerges as a pressing concern. Leveraging the capabilities of artificial intelligence, and in particular, the recent advances in large language models, offers a viable solution to this challenge. This paper introduces a novel model constructed on the foundation of large language models to fully assist non-professionals in providing psychological interventions on online user discourses. This framework makes it plausible to harness the power of non-professional counselors in a meaningful way. A comprehensive study was conducted involving ten professional psychological counselors of varying expertise, evaluating the system across five critical dimensions. The findings affirm that our system is capable of analyzing patients' issues with relative accuracy and proffering professional-level strategies recommendations, thereby enhancing support for non-professionals. This research serves as a compelling validation of the application of large language models in the field of psychology and lays the groundwork for a new paradigm of community-based mental health support.
Unconfounded Propensity Estimation for Unbiased Ranking
May 18, 2023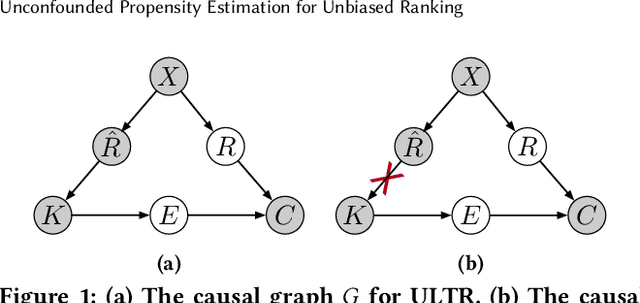
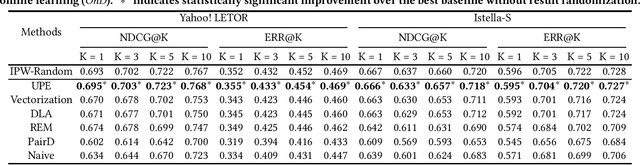
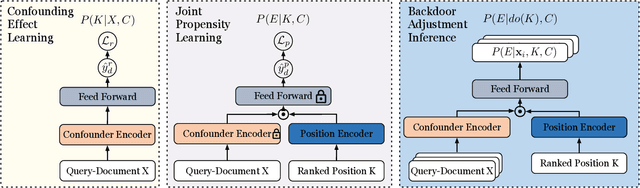
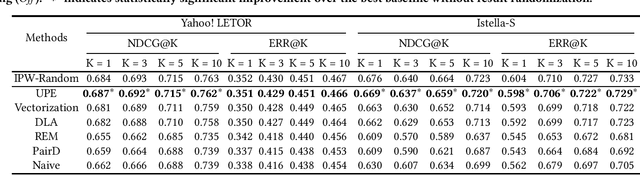
The goal of unbiased learning to rank (ULTR) is to leverage implicit user feedback for optimizing learning-to-rank systems. Among existing solutions, automatic ULTR algorithms that jointly learn user bias models (i.e., propensity models) with unbiased rankers have received a lot of attention due to their superior performance and low deployment cost in practice. Despite their theoretical soundness, the effectiveness is usually justified under a weak logging policy, where the ranking model can barely rank documents according to their relevance to the query. However, when the logging policy is strong, e.g., an industry-deployed ranking policy, the reported effectiveness cannot be reproduced. In this paper, we first investigate ULTR from a causal perspective and uncover a negative result: existing ULTR algorithms fail to address the issue of propensity overestimation caused by the query-document relevance confounder. Then, we propose a new learning objective based on backdoor adjustment and highlight its differences from conventional propensity models, which reveal the prevalence of propensity overestimation. On top of that, we introduce a novel propensity model called Logging-Policy-aware Propensity (LPP) model and its distinctive two-step optimization strategy, which allows for the joint learning of LPP and ranking models within the automatic ULTR framework, and actualize the unconfounded propensity estimation for ULTR. Extensive experiments on two benchmarks demonstrate the effectiveness and generalizability of the proposed method.
Cross-view Action Recognition via Contrastive View-invariant Representation
May 02, 2023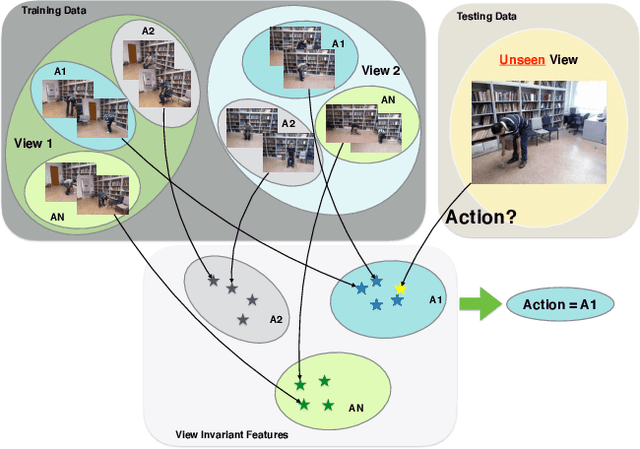

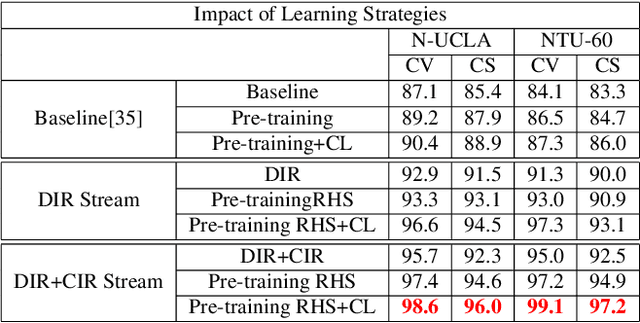
Cross view action recognition (CVAR) seeks to recognize a human action when observed from a previously unseen viewpoint. This is a challenging problem since the appearance of an action changes significantly with the viewpoint. Applications of CVAR include surveillance and monitoring of assisted living facilities where is not practical or feasible to collect large amounts of training data when adding a new camera. We present a simple yet efficient CVAR framework to learn invariant features from either RGB videos, 3D skeleton data, or both. The proposed approach outperforms the current state-of-the-art achieving similar levels of performance across input modalities: 99.4% (RGB) and 99.9% (3D skeletons), 99.4% (RGB) and 99.9% (3D Skeletons), 97.3% (RGB), and 99.2% (3D skeletons), and 84.4%(RGB) for the N-UCLA, NTU-RGB+D 60, NTU-RGB+D 120, and UWA3DII datasets, respectively.
Interpretable machine learning-accelerated seed treatment by nanomaterials for environmental stress alleviation
Apr 08, 2023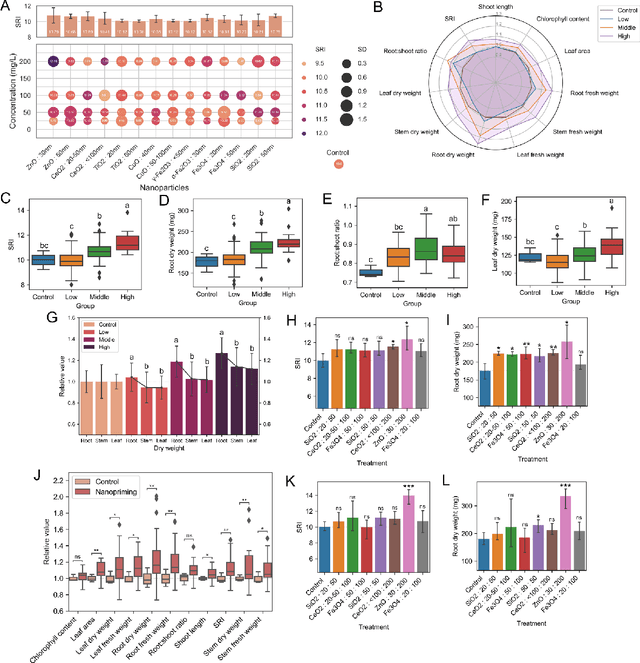
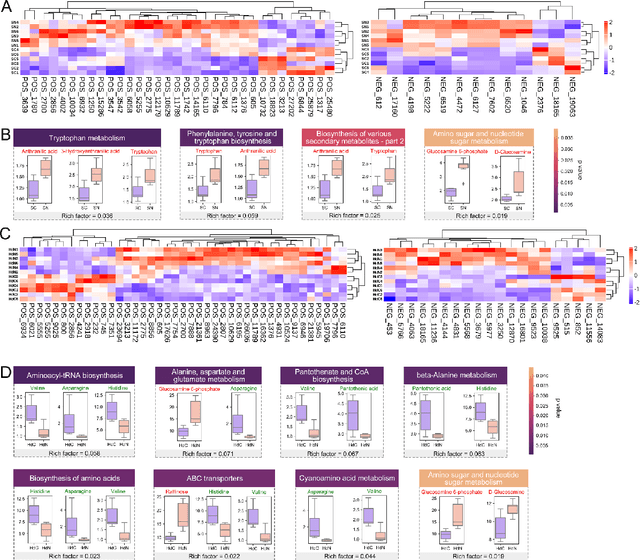
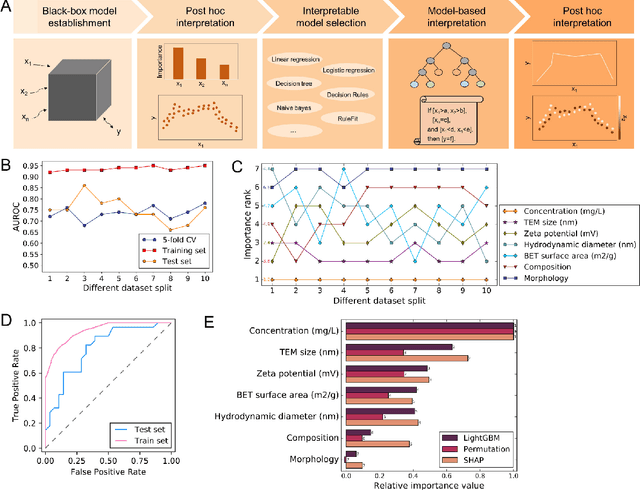
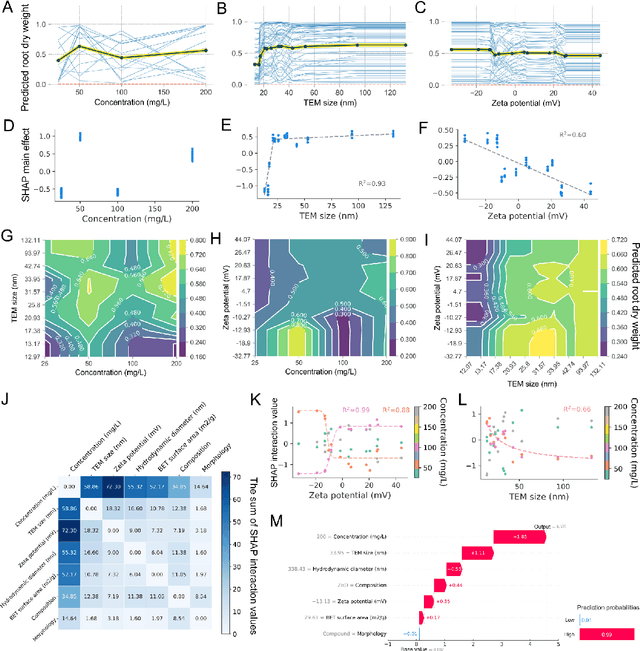
Crops are constantly challenged by different environmental conditions. Seed treatment by nanomaterials is a cost-effective and environmentally-friendly solution for environmental stress mitigation in crop plants. Here, 56 seed nanopriming treatments are used to alleviate environmental stresses in maize. Seven selected nanopriming treatments significantly increase the stress resistance index (SRI) by 13.9% and 12.6% under salinity stress and combined heat-drought stress, respectively. Metabolomics data reveals that ZnO nanopriming treatment, with the highest SRI value, mainly regulates the pathways of amino acid metabolism, secondary metabolite synthesis, carbohydrate metabolism, and translation. Understanding the mechanism of seed nanopriming is still difficult due to the variety of nanomaterials and the complexity of interactions between nanomaterials and plants. Using the nanopriming data, we present an interpretable structure-activity relationship (ISAR) approach based on interpretable machine learning for predicting and understanding its stress mitigation effects. The post hoc and model-based interpretation approaches of machine learning are combined to provide complementary benefits and give researchers or policymakers more illuminating or trustworthy results. The concentration, size, and zeta potential of nanoparticles are identified as dominant factors for correlating root dry weight under salinity stress, and their effects and interactions are explained. Additionally, a web-based interactive tool is developed for offering prediction-level interpretation and gathering more details about specific nanopriming treatments. This work offers a promising framework for accelerating the agricultural applications of nanomaterials and may profoundly contribute to nanosafety assessment.
Model-based Unbiased Learning to Rank
Jul 26, 2022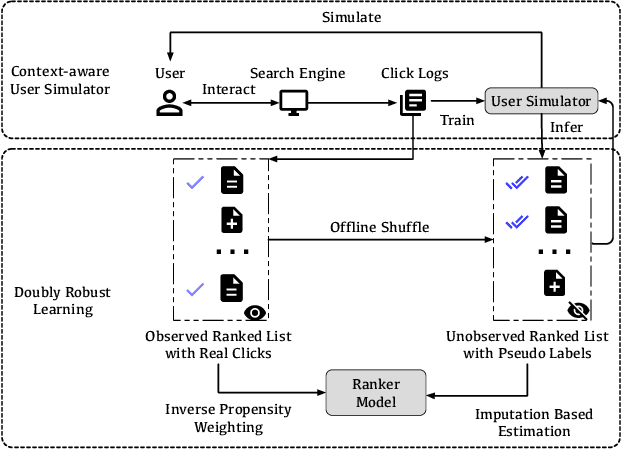
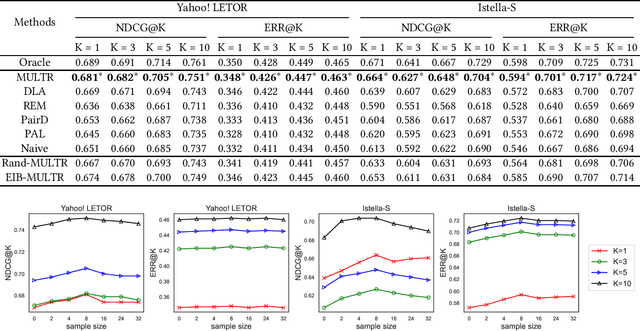
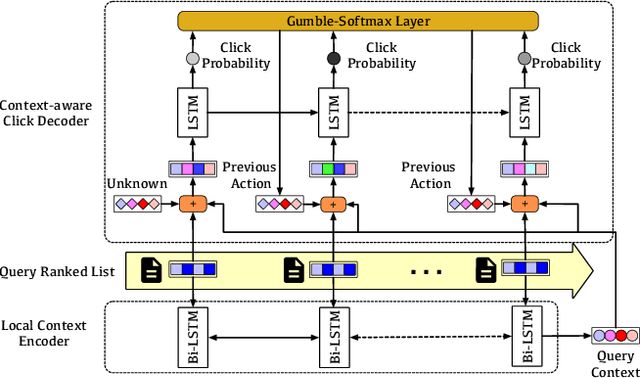
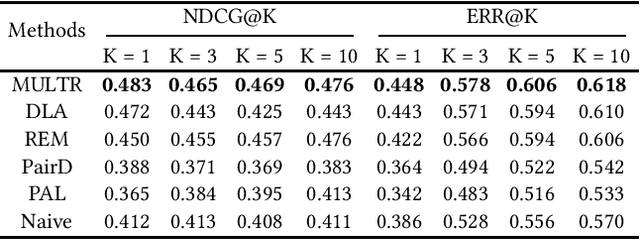
Unbiased Learning to Rank~(ULTR) that learns to rank documents with biased user feedback data is a well-known challenge in information retrieval. Existing methods in unbiased learning to rank typically rely on click modeling or inverse propensity weighting~(IPW). Unfortunately, the search engines are faced with severe long-tail query distribution, where neither click modeling nor IPW can handle well. Click modeling suffers from data sparsity problem since the same query-document pair appears limited times on tail queries; IPW suffers from high variance problem since it is highly sensitive to small propensity score values. Therefore, a general debiasing framework that works well under tail queries is in desperate need. To address this problem, we propose a model-based unbiased learning-to-rank framework. Specifically, we develop a general context-aware user simulator to generate pseudo clicks for unobserved ranked lists to train rankers, which addresses the data sparsity problem. In addition, considering the discrepancy between pseudo clicks and actual clicks, we take the observation of a ranked list as the treatment variable and further incorporate inverse propensity weighting with pseudo labels in a doubly robust way. The derived bias and variance indicate that the proposed model-based method is more robust than existing methods. Finally, extensive experiments on benchmark datasets, including simulated datasets and real click logs, demonstrate that the proposed model-based method consistently performs outperforms state-of-the-art methods in various scenarios.