 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDana Kulic
Alternative Interfaces for Human-initiated Natural Language Communication and Robot-initiated Haptic Feedback: Towards Better Situational Awareness in Human-Robot Collaboration
Jan 25, 2024
This article presents an implementation of a natural-language speech interface and a haptic feedback interface that enables a human supervisor to provide guidance to, request information, and receive status updates from a Spot robot. We provide insights gained during preliminary user testing of the interface in a realistic robot exploration scenario.
How Can Everyday Users Efficiently Teach Robots by Demonstrations?
Oct 19, 2023Learning from Demonstration (LfD) is a framework that allows lay users to easily program robots. However, the efficiency of robot learning and the robot's ability to generalize to task variations hinges upon the quality and quantity of the provided demonstrations. Our objective is to guide human teachers to furnish more effective demonstrations, thus facilitating efficient robot learning. To achieve this, we propose to use a measure of uncertainty, namely task-related information entropy, as a criterion for suggesting informative demonstration examples to human teachers to improve their teaching skills. In a conducted experiment (N=24), an augmented reality (AR)-based guidance system was employed to train novice users to produce additional demonstrations from areas with the highest entropy within the workspace. These novice users were trained for a few trials to teach the robot a generalizable task using a limited number of demonstrations. Subsequently, the users' performance after training was assessed first on the same task (retention) and then on a novel task (transfer) without guidance. The results indicated a substantial improvement in robot learning efficiency from the teacher's demonstrations, with an improvement of up to 198% observed on the novel task. Furthermore, the proposed approach was compared to a state-of-the-art heuristic rule and found to improve robot learning efficiency by 210% compared to the heuristic rule.
Auditory cueing strategy for stride length and cadence modification: a feasibility study with healthy adults
Aug 14, 2023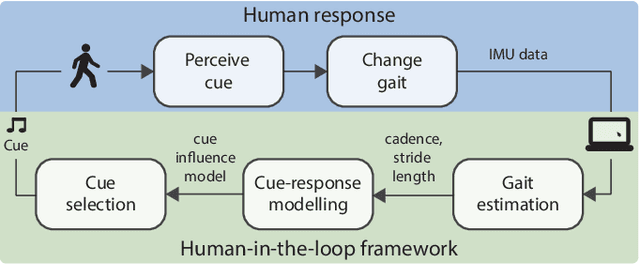
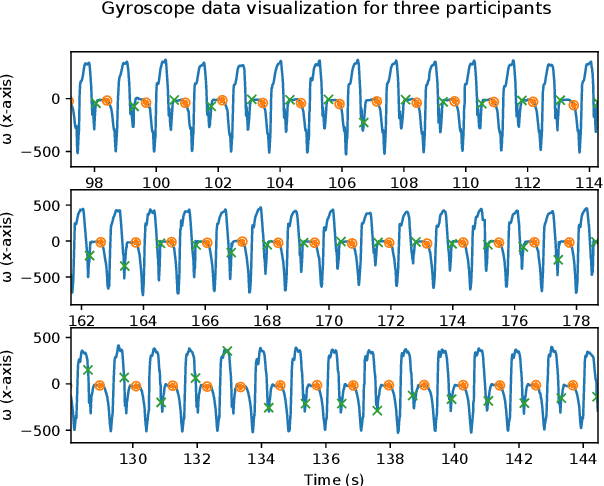
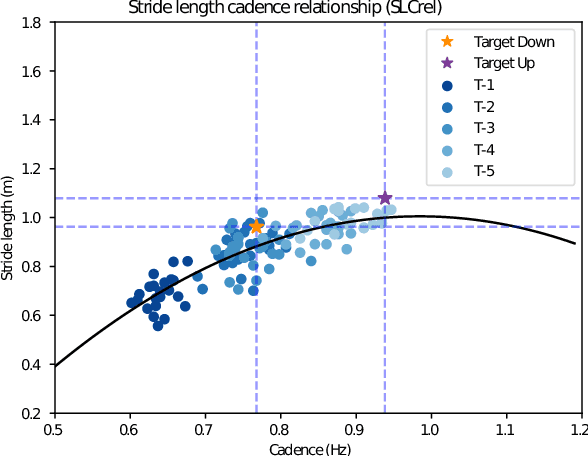
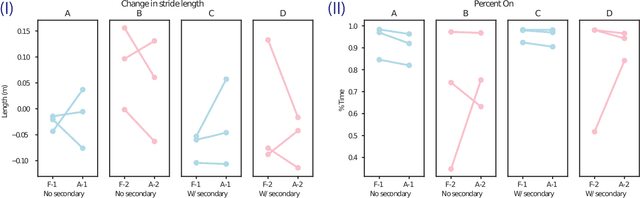
People with Parkinson's Disease experience gait impairments that significantly impact their quality of life. Visual, auditory, and tactile cues can alleviate gait impairments, but they can become less effective due to the progressive nature of the disease and changes in people's motor capability. In this study, we develop a human-in-the-loop (HIL) framework that monitors two key gait parameters, stride length and cadence, and continuously learns a person-specific model of how the parameters change in response to the feedback. The model is then used in an optimization algorithm to improve the gait parameters. This feasibility study examines whether auditory cues can be used to influence stride length in people without gait impairments. The results demonstrate the benefits of the HIL framework in maintaining people's stride length in the presence of a secondary task.
Quantifying Demonstration Quality for Robot Learning and Generalization
Mar 25, 2022
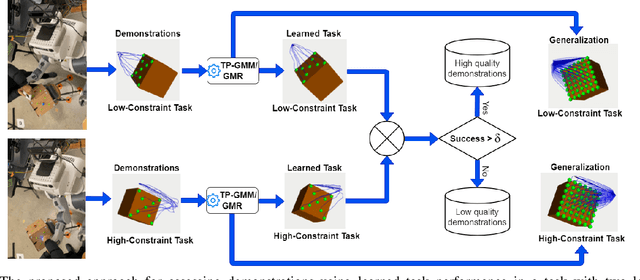
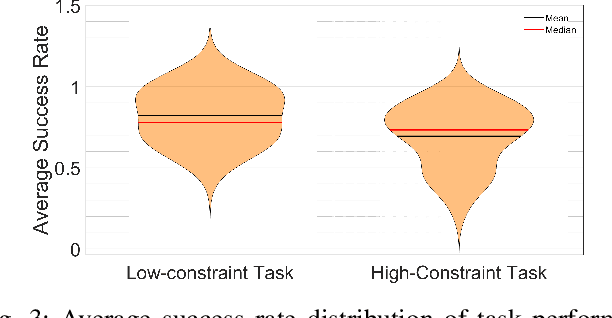
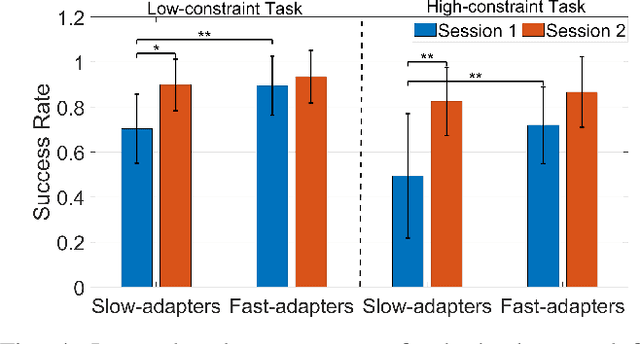
Learning from Demonstration (LfD) seeks to democratize robotics by enabling diverse end-users to teach robots to perform a task by providing demonstrations. However, most LfD techniques assume users provide optimal demonstrations. This is not always the case in real applications where users are likely to provide demonstrations of varying quality, that may change with expertise and other factors. Demonstration quality plays a crucial role in robot learning and generalization. Hence, it is important to quantify the quality of the provided demonstrations before using them for robot learning. In this paper, we propose quantifying the quality of the demonstrations based on how well they perform in the learned task. We hypothesize that task performance can give an indication of the generalization performance on similar tasks. The proposed approach is validated in a user study (N = 27). Users with different robotics expertise levels were recruited to teach a PR2 robot a generic task (pressing a button) under different task constraints. They taught the robot in two sessions on two different days to capture their teaching behaviour across sessions. The task performance was utilized to classify the provided demonstrations into high-quality and low-quality sets. The results show a significant Pearson correlation coefficient (R = 0.85, p < 0.0001) between the task performance and generalization performance across all participants. We also found that users clustered into two groups: Users who provided high-quality demonstrations from the first session, assigned to the fast-adapters group, and users who provided low-quality demonstrations in the first session and then improved with practice, assigned to the slow-adapters group. These results highlight the importance of quantifying demonstration quality, which can be indicative of the adaptation level of the user to the task.
A Proposed Set of Communicative Gestures for Human Robot Interaction and an RGB Image-based Gesture Recognizer Implemented in ROS
Sep 21, 2021

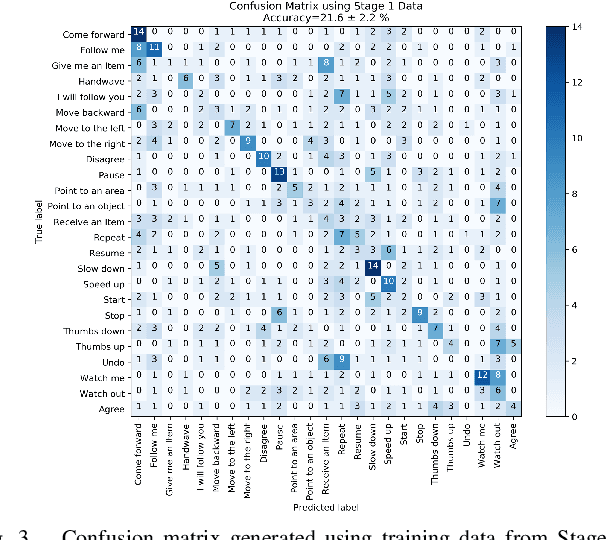
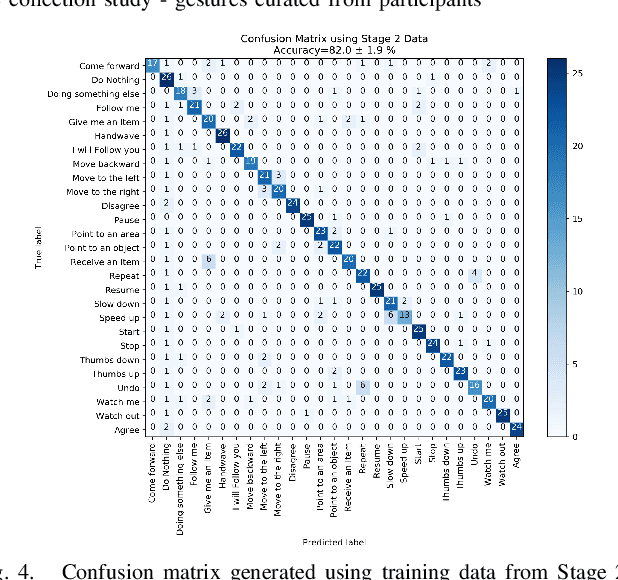
We propose a set of communicative gestures and develop a gesture recognition system with the aim of facilitating more intuitive Human-Robot Interaction (HRI) through gestures. First, we propose a set of commands commonly used for human-robot interaction. Next, an online user study with 190 participants was performed to investigate if there was an agreed set of gestures that people intuitively use to communicate the given commands to robots when no guidance or training were given. As we found large variations among the gestures exist between participants, we then proposed a set of gestures for the proposed commands to be used as a common foundation for robot interaction. We collected ~7500 video demonstrations of the proposed gestures and trained a gesture recognition model, adapting 3D Convolutional Neural Networks (CNN) as the classifier, with a final accuracy of 84.1% (sigma=2.4). The resulting model was capable of training successfully with a relatively small amount of training data. We integrated the gesture recognition model into the ROS framework and report details for a demonstrated use case, where a person commands a robot to perform a pick and place task using the proposed set. This integrated ROS gesture recognition system is made available for use, and built with the intention to allow for new adaptations depending on robot model and use case scenarios, for novel user applications.
Aligning Robot's Behaviours and Users' Perceptions Through Participatory Prototyping
Jan 11, 2021
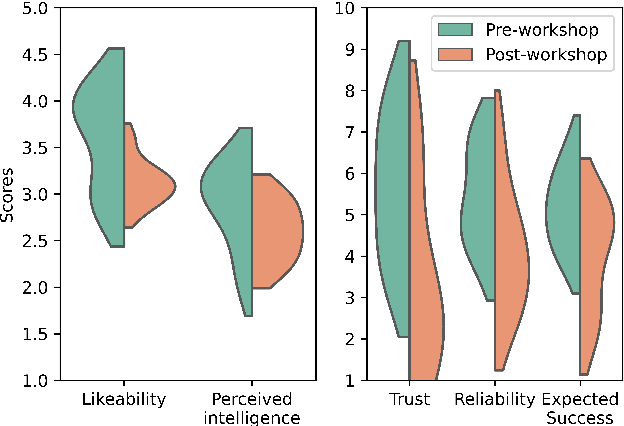
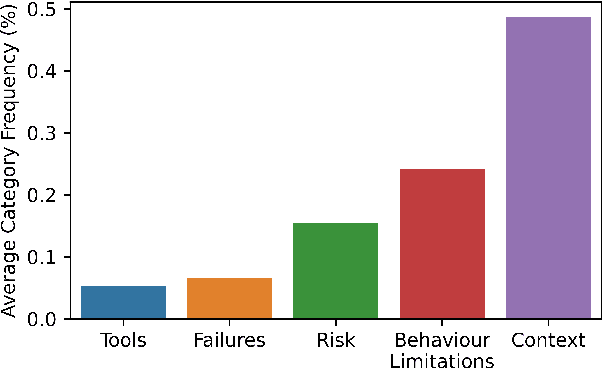
Robots are increasingly being deployed in public spaces. However, the general population rarely has the opportunity to nominate what they would prefer or expect a robot to do in these contexts. Since most people have little or no experience interacting with a robot, it is not surprising that robots deployed in the real world may fail to gain acceptance or engage their intended users. To address this issue, we examine users' understanding of robots in public spaces and their expectations of appropriate uses of robots in these spaces. Furthermore, we investigate how these perceptions and expectations change as users engage and interact with a robot. To support this goal, we conducted a participatory design workshop in which participants were actively involved in the prototyping and testing of a robot's behaviours in simulation and on the physical robot. Our work highlights how social and interaction contexts influence users' perception of robots in public spaces and how users' design and understanding of what are appropriate robot behaviors shifts as they observe the enactment of their designs.
Human-in-the-loop Cueing Strategy for Gait Rehabilitation
Nov 27, 2020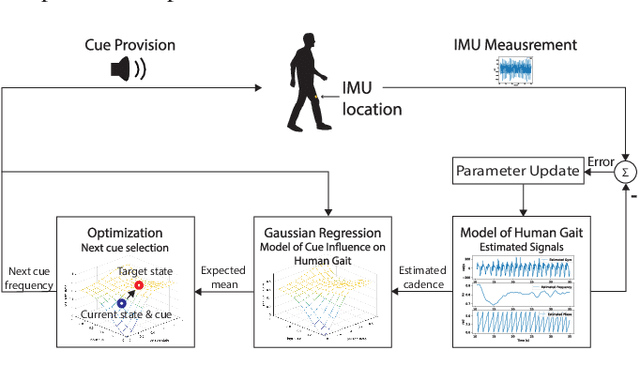
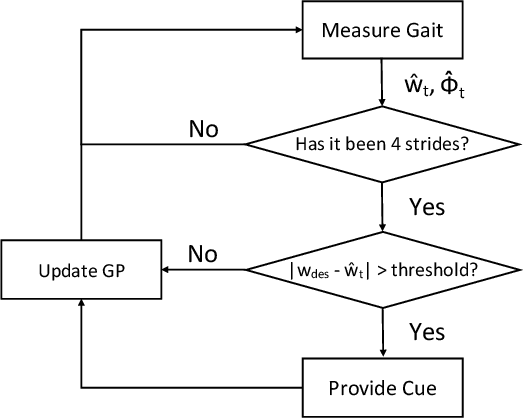
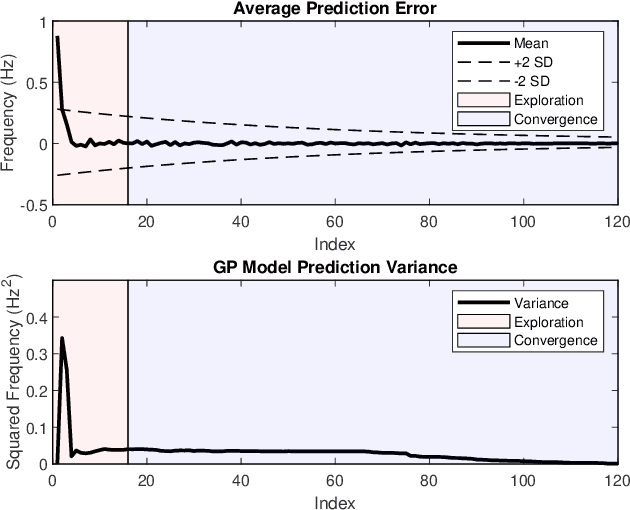
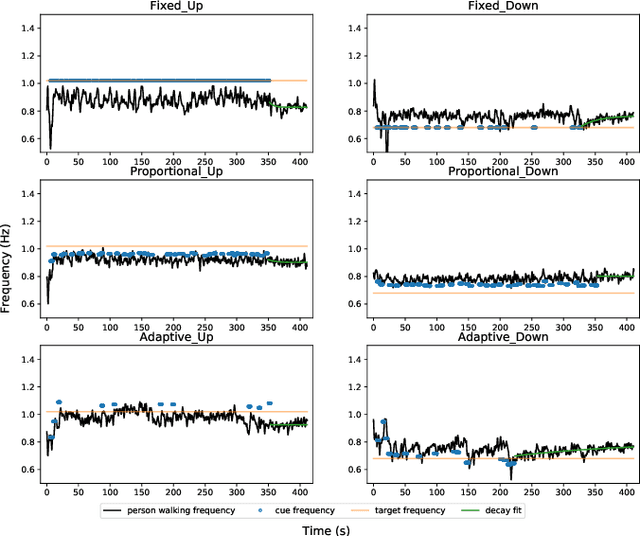
External feedback in the form of visual, auditory and tactile cues has been used to assist patients to overcome mobility challenges. However, these cues can become less effective over time. There is limited research on adapting cues to account for inter and intra-personal variations in cue responsiveness. We propose a cue-provision framework that consists of a gait performance monitoring algorithm and an adaptive cueing strategy to improve gait performance. The proposed approach learns a model of the person's response to cues using Gaussian Process regression. The model is then used within an on-line optimization algorithm to generate cues to improve gait performance. We conduct a study with healthy participants to evaluate the ability of the adaptive cueing strategy to influence human gait, and compare its effectiveness to two other cueing approaches: the standard fixed cue approach and a proportional cue approach. The results show that adaptive cueing is more effective in changing the person's gait state once the response model is learned compared to the other methods.
Joint Estimation of Expertise and Reward Preferences From Human Demonstrations
Nov 09, 2020
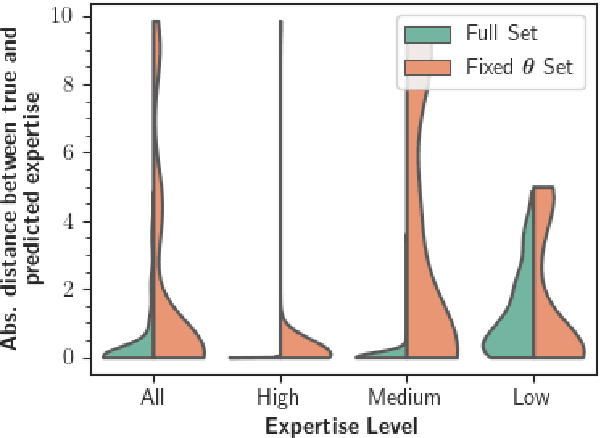
When a robot learns from human examples, most approaches assume that the human partner provides examples of optimal behavior. However, there are applications in which the robot learns from non-expert humans. We argue that the robot should learn not only about the human's objectives, but also about their expertise level. The robot could then leverage this joint information to reduce or increase the frequency at which it provides assistance to its human's partner or be more cautious when learning new skills from novice users. Similarly, by taking into account the human's expertise, the robot would also be able of inferring a human's true objectives even when the human's fails to properly demonstrate these objectives due to a lack of expertise. In this paper, we propose to jointly infer the expertise level and objective function of a human given observations of their (possibly) non-optimal demonstrations. Two inference approaches are proposed. In the first approach, inference is done over a finite, discrete set of possible objective functions and expertise levels. In the second approach, the robot optimizes over the space of all possible hypotheses and finds the objective function and expertise level that best explain the observed human behavior. We demonstrate our proposed approaches both in simulation and with real user data.
Strawberry Detection using Mixed Training on Simulated and Real Data
Aug 24, 2020
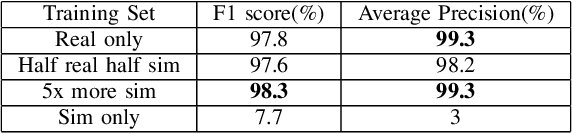
This paper demonstrates how simulated images can be useful for object detection tasks in the agricultural sector, where labeled data can be scarce and costly to collect. We consider training on mixed datasets with real and simulated data for strawberry detection in real images. Our results show that using the real dataset augmented by the simulated dataset resulted in slightly higher accuracy.
Object Handovers: a Review for Robotics
Jul 25, 2020
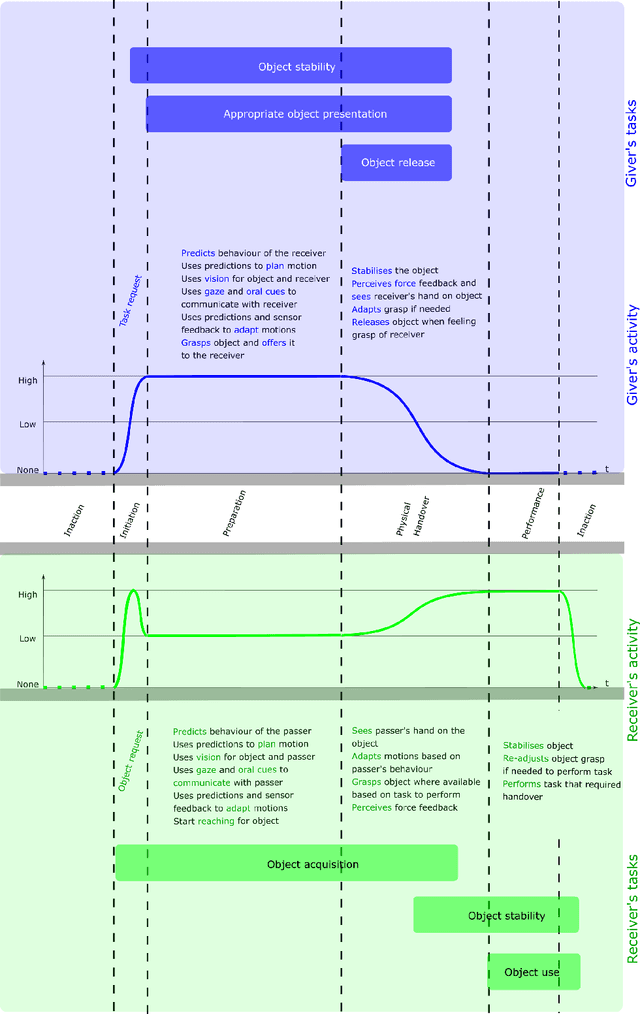
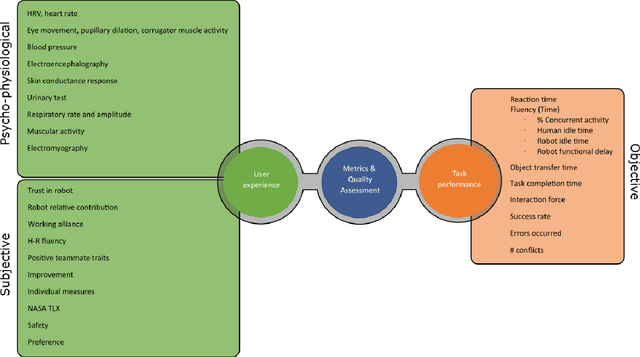
This article surveys the literature on human-robot object handovers. A handover is a collaborative joint action where an agent, the giver, gives an object to another agent, the receiver. The physical exchange starts when the receiver first contacts the object held by the giver and ends when the giver fully releases the object to the receiver. However, important cognitive and physical processes begin before the physical exchange, including initiating implicit agreement with respect to the location and timing of the exchange. From this perspective, we structure our review into the two main phases delimited by the aforementioned events: 1) a pre-handover phase, and 2) the physical exchange. We focus our analysis on the two actors (giver and receiver) and report the state of the art of robotic givers (robot-to-human handovers) and the robotic receivers (human-to-robot handovers). We report a comprehensive list of qualitative and quantitative metrics commonly used to assess the interaction. While focusing our review on the cognitive level (e.g., prediction, perception, motion planning, learning) and the physical level (e.g., motion, grasping, grip release) of the handover, we briefly discuss also the concepts of safety, social context, and ergonomics. We compare the behaviours displayed during human-to-human handovers to the state of the art of robotic assistants, and identify the major areas of improvement for robotic assistants to reach performance comparable to human interactions. Finally, we propose a minimal set of metrics that should be used in order to enable a fair comparison among the approaches.