 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDaquan Zhou
StoryDiffusion: Consistent Self-Attention for Long-Range Image and Video Generation
May 02, 2024
For recent diffusion-based generative models, maintaining consistent content across a series of generated images, especially those containing subjects and complex details, presents a significant challenge. In this paper, we propose a new way of self-attention calculation, termed Consistent Self-Attention, that significantly boosts the consistency between the generated images and augments prevalent pretrained diffusion-based text-to-image models in a zero-shot manner. To extend our method to long-range video generation, we further introduce a novel semantic space temporal motion prediction module, named Semantic Motion Predictor. It is trained to estimate the motion conditions between two provided images in the semantic spaces. This module converts the generated sequence of images into videos with smooth transitions and consistent subjects that are significantly more stable than the modules based on latent spaces only, especially in the context of long video generation. By merging these two novel components, our framework, referred to as StoryDiffusion, can describe a text-based story with consistent images or videos encompassing a rich variety of contents. The proposed StoryDiffusion encompasses pioneering explorations in visual story generation with the presentation of images and videos, which we hope could inspire more research from the aspect of architectural modifications. Our code is made publicly available at https://github.com/HVision-NKU/StoryDiffusion.
PLLaVA : Parameter-free LLaVA Extension from Images to Videos for Video Dense Captioning
Apr 29, 2024Vision-language pre-training has significantly elevated performance across a wide range of image-language applications. Yet, the pre-training process for video-related tasks demands exceptionally large computational and data resources, which hinders the progress of video-language models. This paper investigates a straight-forward, highly efficient, and resource-light approach to adapting an existing image-language pre-trained model for dense video understanding. Our preliminary experiments reveal that directly fine-tuning pre-trained image-language models with multiple frames as inputs on video datasets leads to performance saturation or even a drop. Our further investigation reveals that it is largely attributed to the bias of learned high-norm visual features. Motivated by this finding, we propose a simple but effective pooling strategy to smooth the feature distribution along the temporal dimension and thus reduce the dominant impacts from the extreme features. The new model is termed Pooling LLaVA, or PLLaVA in short. PLLaVA achieves new state-of-the-art performance on modern benchmark datasets for both video question-answer and captioning tasks. Notably, on the recent popular VideoChatGPT benchmark, PLLaVA achieves a score of 3.48 out of 5 on average of five evaluated dimensions, exceeding the previous SOTA results from GPT4V (IG-VLM) by 9%. On the latest multi-choice benchmark MVBench, PLLaVA achieves 58.1% accuracy on average across 20 sub-tasks, 14.5% higher than GPT4V (IG-VLM). Code is available at https://pllava.github.io/
Chain of Thought Explanation for Dialogue State Tracking
Mar 09, 2024

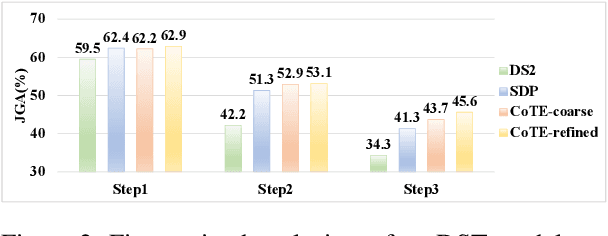
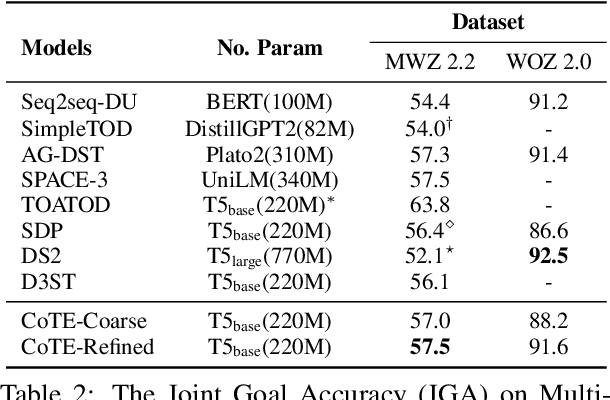
Dialogue state tracking (DST) aims to record user queries and goals during a conversational interaction achieved by maintaining a predefined set of slots and their corresponding values. Current approaches decide slot values opaquely, while humans usually adopt a more deliberate approach by collecting information from relevant dialogue turns and then reasoning the appropriate values. In this work, we focus on the steps needed to figure out slot values by proposing a model named Chain-of-Thought-Explanation (CoTE) for the DST task. CoTE, which is built on the generative DST framework, is designed to create detailed explanations step by step after determining the slot values. This process leads to more accurate and reliable slot values. More-over, to improve the reasoning ability of the CoTE, we further construct more fluent and high-quality explanations with automatic paraphrasing, leading the method CoTE-refined. Experimental results on three widely recognized DST benchmarks-MultiWOZ 2.2, WoZ 2.0, and M2M-demonstrate the remarkable effectiveness of the CoTE. Furthermore, through a meticulous fine-grained analysis, we observe significant benefits of our CoTE on samples characterized by longer dialogue turns, user responses, and reasoning steps.
Sora Generates Videos with Stunning Geometrical Consistency
Feb 27, 2024The recently developed Sora model [1] has exhibited remarkable capabilities in video generation, sparking intense discussions regarding its ability to simulate real-world phenomena. Despite its growing popularity, there is a lack of established metrics to evaluate its fidelity to real-world physics quantitatively. In this paper, we introduce a new benchmark that assesses the quality of the generated videos based on their adherence to real-world physics principles. We employ a method that transforms the generated videos into 3D models, leveraging the premise that the accuracy of 3D reconstruction is heavily contingent on the video quality. From the perspective of 3D reconstruction, we use the fidelity of the geometric constraints satisfied by the constructed 3D models as a proxy to gauge the extent to which the generated videos conform to real-world physics rules. Project page: https://sora-geometrical-consistency.github.io/
Magic-Me: Identity-Specific Video Customized Diffusion
Feb 14, 2024Creating content for a specific identity (ID) has shown significant interest in the field of generative models. In the field of text-to-image generation (T2I), subject-driven content generation has achieved great progress with the ID in the images controllable. However, extending it to video generation is not well explored. In this work, we propose a simple yet effective subject identity controllable video generation framework, termed Video Custom Diffusion (VCD). With a specified subject ID defined by a few images, VCD reinforces the identity information extraction and injects frame-wise correlation at the initialization stage for stable video outputs with identity preserved to a large extent. To achieve this, we propose three novel components that are essential for high-quality ID preservation: 1) an ID module trained with the cropped identity by prompt-to-segmentation to disentangle the ID information and the background noise for more accurate ID token learning; 2) a text-to-video (T2V) VCD module with 3D Gaussian Noise Prior for better inter-frame consistency and 3) video-to-video (V2V) Face VCD and Tiled VCD modules to deblur the face and upscale the video for higher resolution. Despite its simplicity, we conducted extensive experiments to verify that VCD is able to generate stable and high-quality videos with better ID over the selected strong baselines. Besides, due to the transferability of the ID module, VCD is also working well with finetuned text-to-image models available publically, further improving its usability. The codes are available at https://github.com/Zhen-Dong/Magic-Me.
MagicVideo-V2: Multi-Stage High-Aesthetic Video Generation
Jan 09, 2024The growing demand for high-fidelity video generation from textual descriptions has catalyzed significant research in this field. In this work, we introduce MagicVideo-V2 that integrates the text-to-image model, video motion generator, reference image embedding module and frame interpolation module into an end-to-end video generation pipeline. Benefiting from these architecture designs, MagicVideo-V2 can generate an aesthetically pleasing, high-resolution video with remarkable fidelity and smoothness. It demonstrates superior performance over leading Text-to-Video systems such as Runway, Pika 1.0, Morph, Moon Valley and Stable Video Diffusion model via user evaluation at large scale.
Factorization Vision Transformer: Modeling Long Range Dependency with Local Window Cost
Dec 14, 2023Transformers have astounding representational power but typically consume considerable computation which is quadratic with image resolution. The prevailing Swin transformer reduces computational costs through a local window strategy. However, this strategy inevitably causes two drawbacks: (1) the local window-based self-attention hinders global dependency modeling capability; (2) recent studies point out that local windows impair robustness. To overcome these challenges, we pursue a preferable trade-off between computational cost and performance. Accordingly, we propose a novel factorization self-attention mechanism (FaSA) that enjoys both the advantages of local window cost and long-range dependency modeling capability. By factorizing the conventional attention matrix into sparse sub-attention matrices, FaSA captures long-range dependencies while aggregating mixed-grained information at a computational cost equivalent to the local window-based self-attention. Leveraging FaSA, we present the factorization vision transformer (FaViT) with a hierarchical structure. FaViT achieves high performance and robustness, with linear computational complexity concerning input image spatial resolution. Extensive experiments have shown FaViT's advanced performance in classification and downstream tasks. Furthermore, it also exhibits strong model robustness to corrupted and biased data and hence demonstrates benefits in favor of practical applications. In comparison to the baseline model Swin-T, our FaViT-B2 significantly improves classification accuracy by 1% and robustness by 7%, while reducing model parameters by 14%. Our code will soon be publicly available at https://github.com/q2479036243/FaViT.
MAgIC: Investigation of Large Language Model Powered Multi-Agent in Cognition, Adaptability, Rationality and Collaboration
Nov 16, 2023Large Language Models (LLMs) have marked a significant advancement in the field of natural language processing, demonstrating exceptional capabilities in reasoning, tool usage, and memory. As their applications extend into multi-agent environments, a need has arisen for a comprehensive evaluation framework that captures their abilities in reasoning, planning, collaboration, and more. This work introduces a novel benchmarking framework specifically tailored to assess LLMs within multi-agent settings, providing quantitative metrics to evaluate their judgment, reasoning, deception, self-awareness, cooperation, coordination, and rationality. We utilize games such as Chameleon and Undercover, alongside game theory scenarios like Cost Sharing, Multi-player Prisoner's Dilemma, and Public Good, to create diverse testing environments. Our framework is fortified with the Probabilistic Graphical Modeling (PGM) method, enhancing the LLMs' capabilities in navigating complex social and cognitive dimensions. The benchmark evaluates seven multi-agent systems powered by different LLMs, quantitatively highlighting a significant capability gap over threefold between the strongest, GPT-4, and the weakest, Llama-2-70B. It also confirms that our PGM enhancement boosts the inherent abilities of all selected models by 50% on average. Our codes are released here https://github.com/cathyxl/MAgIC.
EPIM: Efficient Processing-In-Memory Accelerators based on Epitome
Nov 12, 2023The exploration of Processing-In-Memory (PIM) accelerators has garnered significant attention within the research community. However, the utilization of large-scale neural networks on Processing-In-Memory (PIM) accelerators encounters challenges due to constrained on-chip memory capacity. To tackle this issue, current works explore model compression algorithms to reduce the size of Convolutional Neural Networks (CNNs). Most of these algorithms either aim to represent neural operators with reduced-size parameters (e.g., quantization) or search for the best combinations of neural operators (e.g., neural architecture search). Designing neural operators to align with PIM accelerators' specifications is an area that warrants further study. In this paper, we introduce the Epitome, a lightweight neural operator offering convolution-like functionality, to craft memory-efficient CNN operators for PIM accelerators (EPIM). On the software side, we evaluate epitomes' latency and energy on PIM accelerators and introduce a PIM-aware layer-wise design method to enhance their hardware efficiency. We apply epitome-aware quantization to further reduce the size of epitomes. On the hardware side, we modify the datapath of current PIM accelerators to accommodate epitomes and implement a feature map reuse technique to reduce computation cost. Experimental results reveal that our 3-bit quantized EPIM-ResNet50 attains 71.59% top-1 accuracy on ImageNet, reducing crossbar areas by 30.65 times. EPIM surpasses the state-of-the-art pruning methods on PIM.
ChatAnything: Facetime Chat with LLM-Enhanced Personas
Nov 12, 2023In this technical report, we target generating anthropomorphized personas for LLM-based characters in an online manner, including visual appearance, personality and tones, with only text descriptions. To achieve this, we first leverage the in-context learning capability of LLMs for personality generation by carefully designing a set of system prompts. We then propose two novel concepts: the mixture of voices (MoV) and the mixture of diffusers (MoD) for diverse voice and appearance generation. For MoV, we utilize the text-to-speech (TTS) algorithms with a variety of pre-defined tones and select the most matching one based on the user-provided text description automatically. For MoD, we combine the recent popular text-to-image generation techniques and talking head algorithms to streamline the process of generating talking objects. We termed the whole framework as ChatAnything. With it, users could be able to animate anything with any personas that are anthropomorphic using just a few text inputs. However, we have observed that the anthropomorphic objects produced by current generative models are often undetectable by pre-trained face landmark detectors, leading to failure of the face motion generation, even if these faces possess human-like appearances because those images are nearly seen during the training (e.g., OOD samples). To address this issue, we incorporate pixel-level guidance to infuse human face landmarks during the image generation phase. To benchmark these metrics, we have built an evaluation dataset. Based on it, we verify that the detection rate of the face landmark is significantly increased from 57.0% to 92.5% thus allowing automatic face animation based on generated speech content. The code and more results can be found at https://chatanything.github.io/.