 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDavid Cortes
Isolation forests: looking beyond tree depth
Nov 23, 2021
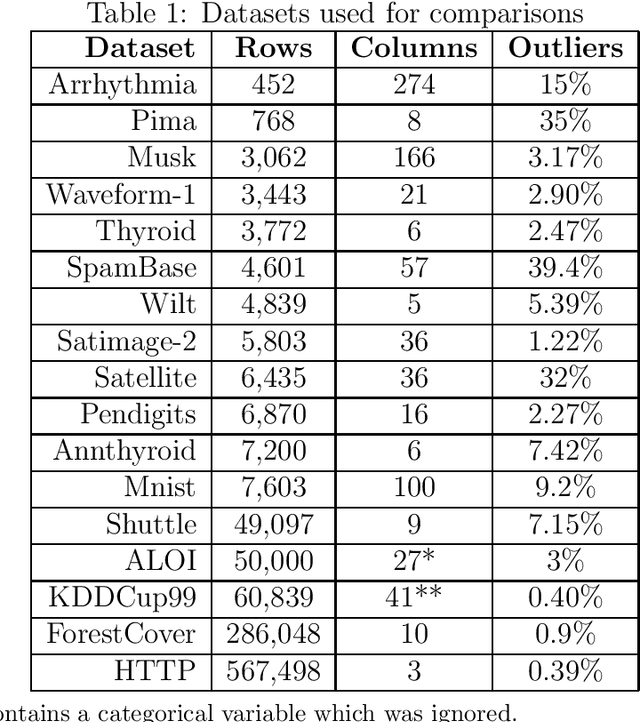
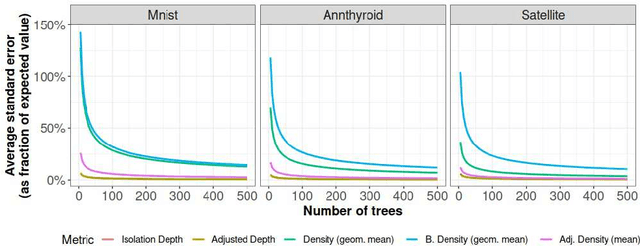
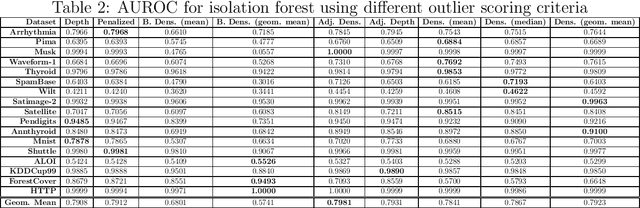
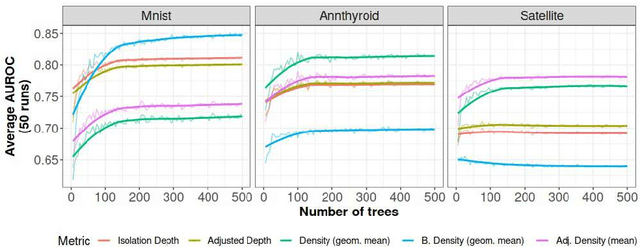
The isolation forest algorithm for outlier detection exploits a simple yet effective observation: if taking some multivariate data and making uniformly random cuts across the feature space recursively, it will take fewer such random cuts for an outlier to be left alone in a given subspace as compared to regular observations. The original idea proposed an outlier score based on the tree depth (number of random cuts) required for isolation, but experiments here show that using information about the size of the feature space taken and the number of points assigned to it can result in improved results in many situations without any modification to the tree structure, especially in the presence of categorical features.
Revisiting randomized choices in isolation forests
Nov 03, 2021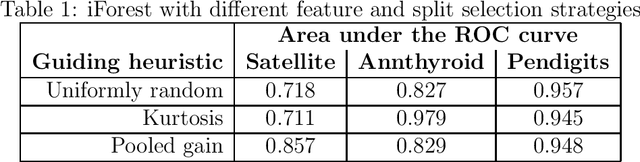
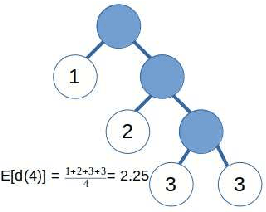
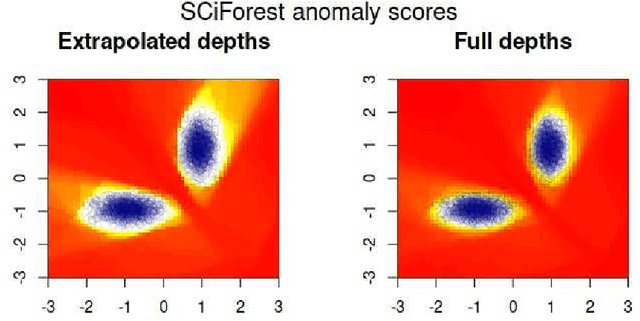
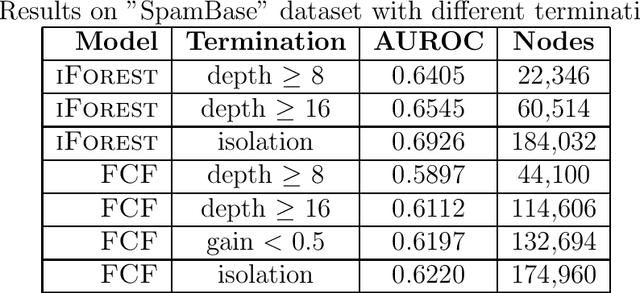
Isolation forest or "iForest" is an intuitive and widely used algorithm for anomaly detection that follows a simple yet effective idea: in a given data distribution, if a threshold (split point) is selected uniformly at random within the range of some variable and data points are divided according to whether they are greater or smaller than this threshold, outlier points are more likely to end up alone or in the smaller partition. The original procedure suggested the choice of variable to split and split point within a variable to be done uniformly at random at each step, but this paper shows that "clustered" diverse outliers - oftentimes a more interesting class of outliers than others - can be more easily identified by applying a non-uniformly-random choice of variables and/or thresholds. Different split guiding criteria are compared and some are found to result in significantly better outlier discrimination for certain classes of outliers.
Explainable outlier detection through decision tree conditioning
Jan 02, 2020This work describes an outlier detection procedure (named "OutlierTree") loosely based on the GritBot software developed by RuleQuest research, which works by evaluating and following supervised decision tree splits on variables, in whose branches 1-d confidence intervals are constructed for the target variable and potential outliers flagged according to these confidence intervals. Under this logic, it's possible to produce human-readable explanations for why a given value of a variable in an observation can be considered as outlier, by considering the decision tree branch conditions along with general distribution statistics among the non-outlier observations that fell into the same branch, which can then be contrasted against the value which lies outside the CI. The supervised splits help to ensure that the generated conditions are not spurious, but rather related to the target variable and having logical breakpoints.
Distance approximation using Isolation Forests
Nov 23, 2019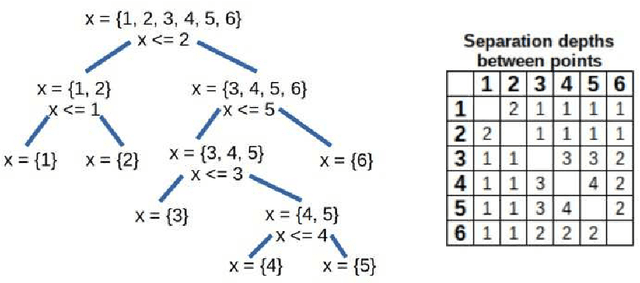

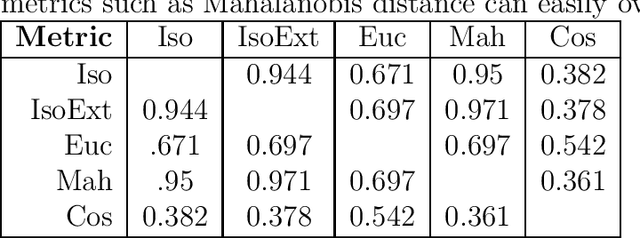
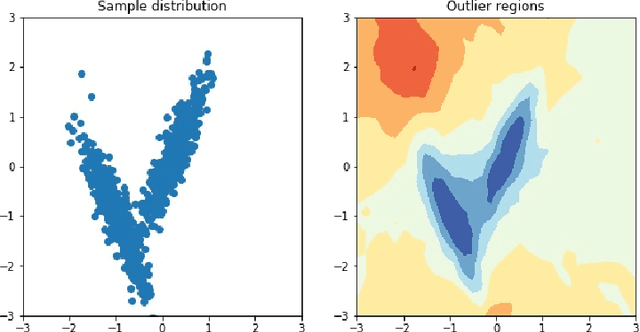
This work briefly explores the possibility of approximating spatial distance (alternatively, similarity) between data points using the Isolation Forest method envisioned for outlier detection. The logic is similar to that of isolation: the more similar or closer two points are, the more random splits it will take to separate them. The separation depth between two points can be standardized in the same way as the isolation depth, transforming it into a distance metric that is limited in range, centered, and in compliance with the axioms of distance. This metric presents some desirable properties such as being invariant to the scales of variables or being able to account for non-linear relationships between variables, which other metrics such as Euclidean or Mahalanobis distance do not. Extensions to the Isolation Forest method are also proposed for handling categorical variables and missing values, resulting in a more generalizable and robust metric.
Imputing missing values with unsupervised random trees
Nov 21, 2019
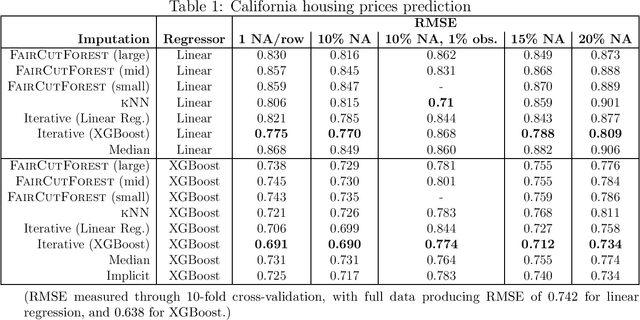
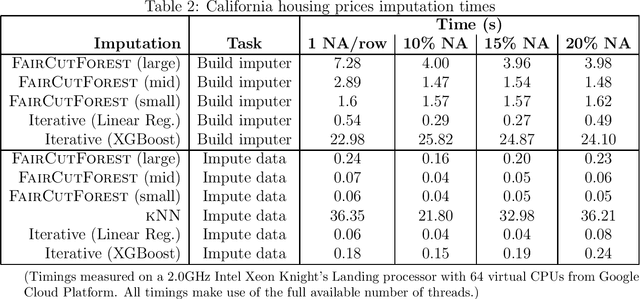
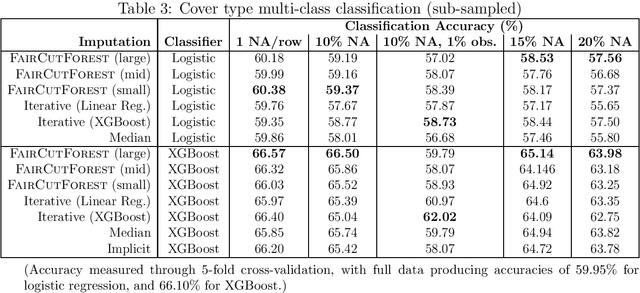
This work proposes a non-iterative strategy for missing value imputations which is guided by similarity between observations, but instead of explicitly determining distances or nearest neighbors, it assigns observations to overlapping buckets through recursive semi-random hyperplane cuts, in which weighted averages are determined as imputations for each variable. The quality of these imputations is oftentimes not as good as that of chained equations, but the proposed technique is much faster, non-iterative, can make imputations on new data without re-calculating anything, and scales easily to large and high-dimensional datasets, providing a significant boost over simple mean/median imputation in regression and classification metrics with imputed values when other methods are not feasible.
Adapting multi-armed bandits policies to contextual bandits scenarios
Nov 11, 2018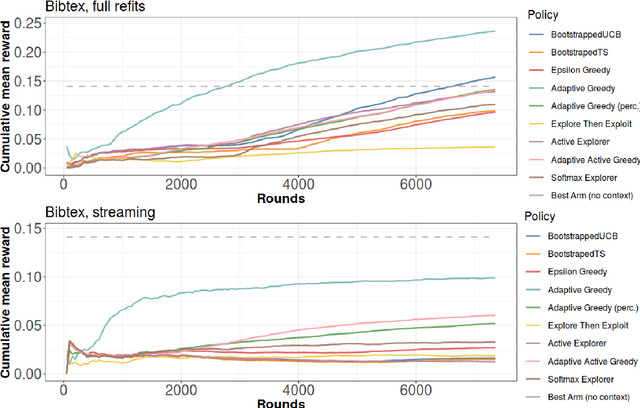
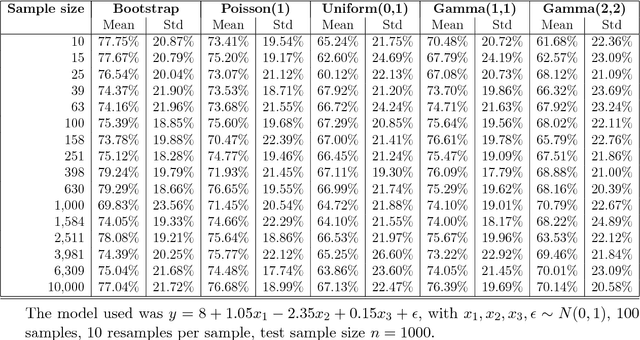
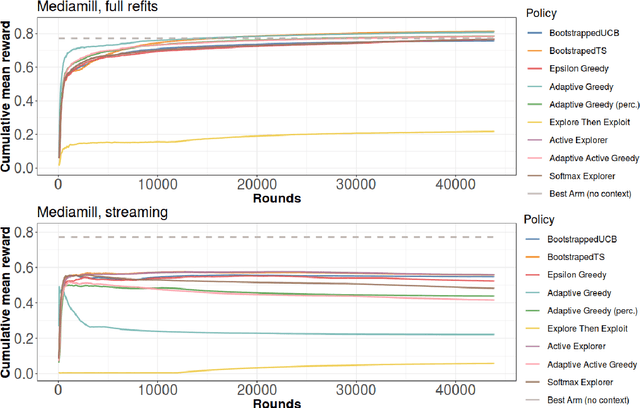
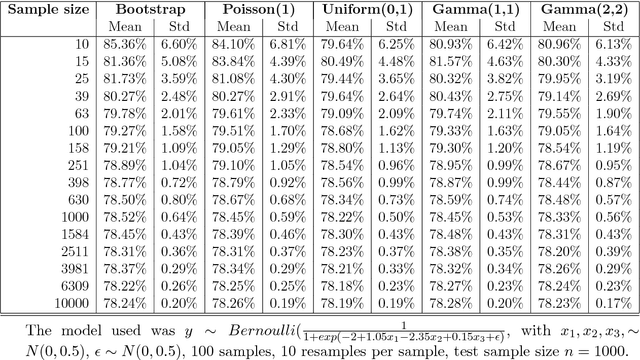
This work explores adaptations of successful multi-armed bandits policies to the online contextual bandits scenario with binary rewards using binary classification algorithms such as logistic regression as black-box oracles. Some of these adaptations are achieved through bootstrapping or approximate bootstrapping, while others rely on other forms of randomness, resulting in more scalable approaches than previous works, and the ability to work with any type of classification algorithm. In particular, the Adaptive-Greedy algorithm shows a lot of promise, in many cases achieving better performance than upper confidence bound and Thompson sampling strategies, at the expense of more hyperparameters to tune.
Fast Non-Bayesian Poisson Factorization for Implicit-Feedback Recommendations
Nov 05, 2018
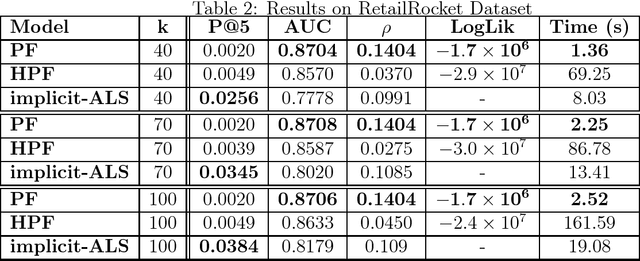
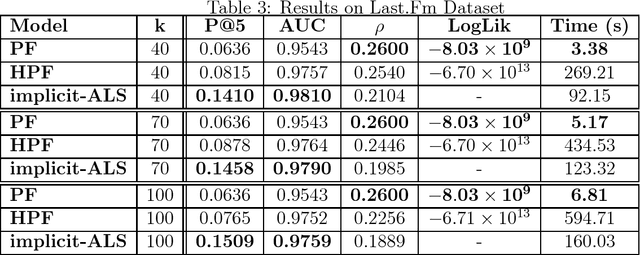
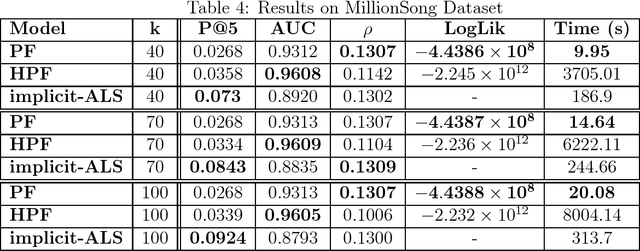
This work explores non-negative matrix factorization based on regularized Poisson models for recommender systems with implicit-feedback data. The properties of Poisson likelihood allow a shortcut for very fast computation and optimization over elements with zero-value when the latent-factor matrices are non-negative, making it a more suitable approach than squared loss for very sparse inputs such as implicit-feedback data. A simple and embarrassingly parallel optimization approach based on proximal gradients is presented, which in large datasets converges 2-3 orders of magnitude faster than its Bayesian counterpart (Hierarchical Poisson Factorization) fit through variational inference techniques, and 1 order of magnitude faster than implicit-ALS fit with the Conjugate Gradient method.