 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDavid R. Mortensen
Neural Proto-Language Reconstruction
Apr 24, 2024
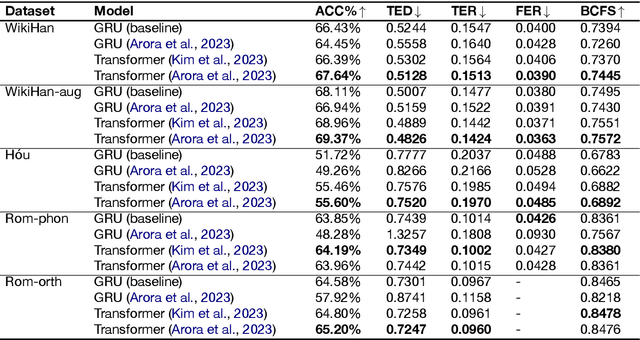
Proto-form reconstruction has been a painstaking process for linguists. Recently, computational models such as RNN and Transformers have been proposed to automate this process. We take three different approaches to improve upon previous methods, including data augmentation to recover missing reflexes, adding a VAE structure to the Transformer model for proto-to-language prediction, and using a neural machine translation model for the reconstruction task. We find that with the additional VAE structure, the Transformer model has a better performance on the WikiHan dataset, and the data augmentation step stabilizes the training.
Improved Neural Protoform Reconstruction via Reflex Prediction
Mar 27, 2024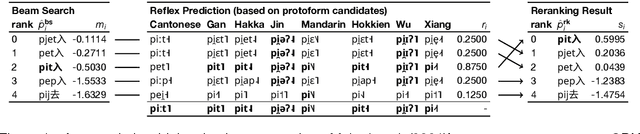


Protolanguage reconstruction is central to historical linguistics. The comparative method, one of the most influential theoretical and methodological frameworks in the history of the language sciences, allows linguists to infer protoforms (reconstructed ancestral words) from their reflexes (related modern words) based on the assumption of regular sound change. Not surprisingly, numerous computational linguists have attempted to operationalize comparative reconstruction through various computational models, the most successful of which have been supervised encoder-decoder models, which treat the problem of predicting protoforms given sets of reflexes as a sequence-to-sequence problem. We argue that this framework ignores one of the most important aspects of the comparative method: not only should protoforms be inferable from cognate sets (sets of related reflexes) but the reflexes should also be inferable from the protoforms. Leveraging another line of research -- reflex prediction -- we propose a system in which candidate protoforms from a reconstruction model are reranked by a reflex prediction model. We show that this more complete implementation of the comparative method allows us to surpass state-of-the-art protoform reconstruction methods on three of four Chinese and Romance datasets.
Verbing Weirds Language (Models): Evaluation of English Zero-Derivation in Five LLMs
Mar 26, 2024
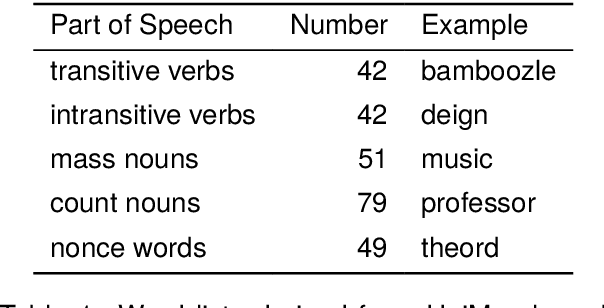
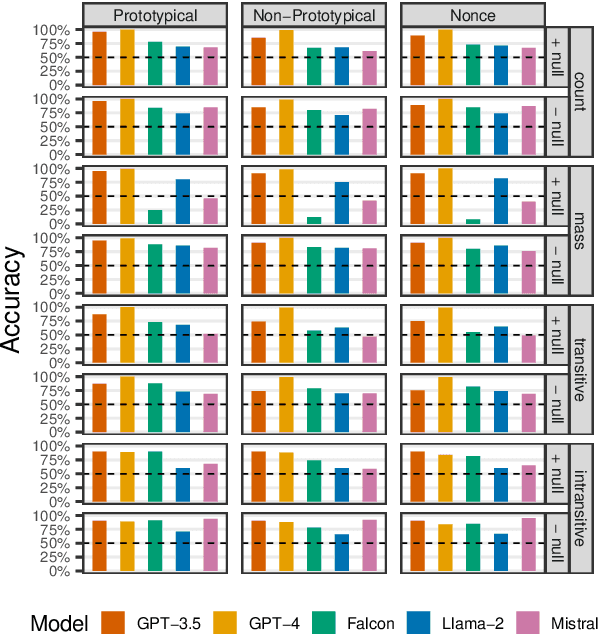

Lexical-syntactic flexibility, in the form of conversion (or zero-derivation) is a hallmark of English morphology. In conversion, a word with one part of speech is placed in a non-prototypical context, where it is coerced to behave as if it had a different part of speech. However, while this process affects a large part of the English lexicon, little work has been done to establish the degree to which language models capture this type of generalization. This paper reports the first study on the behavior of large language models with reference to conversion. We design a task for testing lexical-syntactic flexibility -- the degree to which models can generalize over words in a construction with a non-prototypical part of speech. This task is situated within a natural language inference paradigm. We test the abilities of five language models -- two proprietary models (GPT-3.5 and GPT-4), three open-source models (Mistral 7B, Falcon 40B, and Llama 2 70B). We find that GPT-4 performs best on the task, followed by GPT-3.5, but that the open source language models are also able to perform it and that the 7B parameter Mistral displays as little difference between its baseline performance on the natural language inference task and the non-prototypical syntactic category task, as the massive GPT-4.
Constructions Are So Difficult That Even Large Language Models Get Them Right for the Wrong Reasons
Mar 26, 2024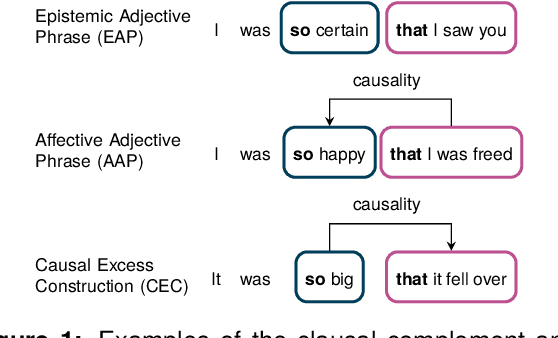
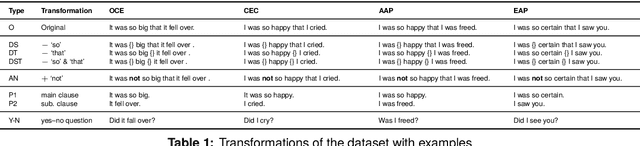
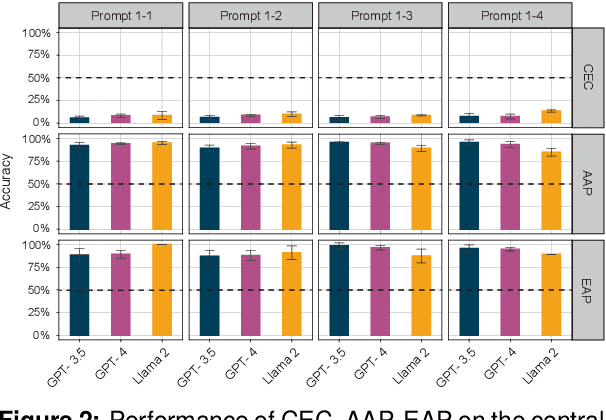
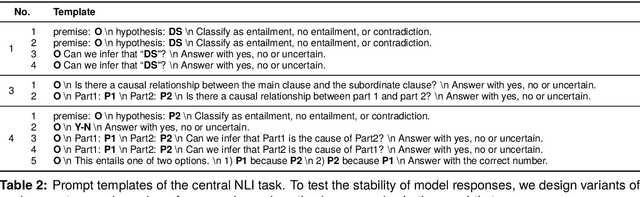
In this paper, we make a contribution that can be understood from two perspectives: from an NLP perspective, we introduce a small challenge dataset for NLI with large lexical overlap, which minimises the possibility of models discerning entailment solely based on token distinctions, and show that GPT-4 and Llama 2 fail it with strong bias. We then create further challenging sub-tasks in an effort to explain this failure. From a Computational Linguistics perspective, we identify a group of constructions with three classes of adjectives which cannot be distinguished by surface features. This enables us to probe for LLM's understanding of these constructions in various ways, and we find that they fail in a variety of ways to distinguish between them, suggesting that they don't adequately represent their meaning or capture the lexical properties of phrasal heads.
Wav2Gloss: Generating Interlinear Glossed Text from Speech
Mar 19, 2024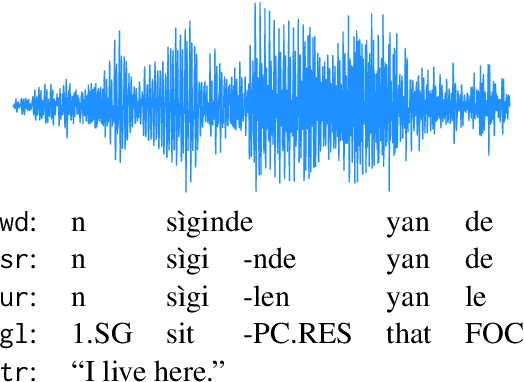
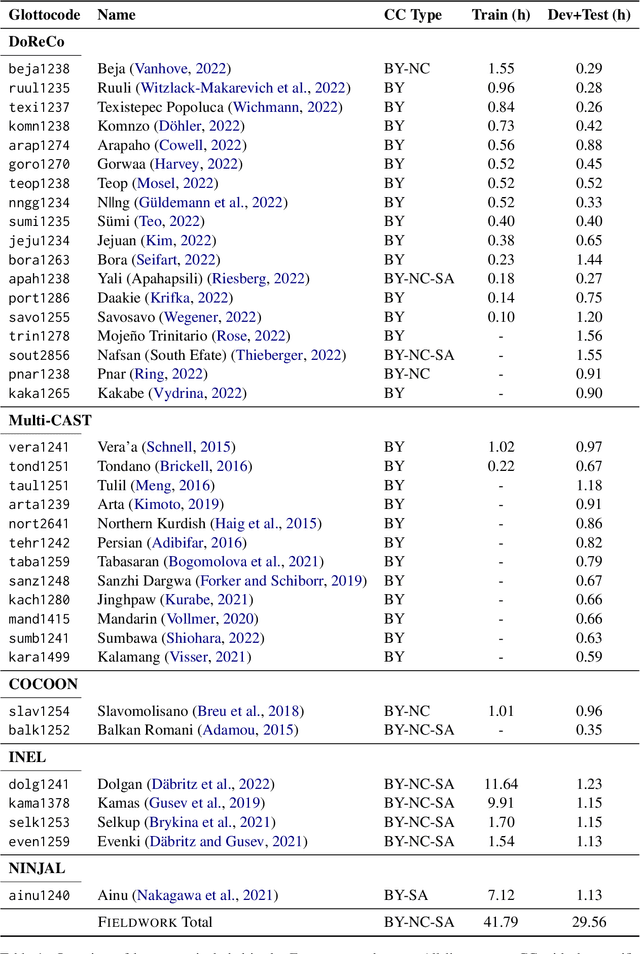
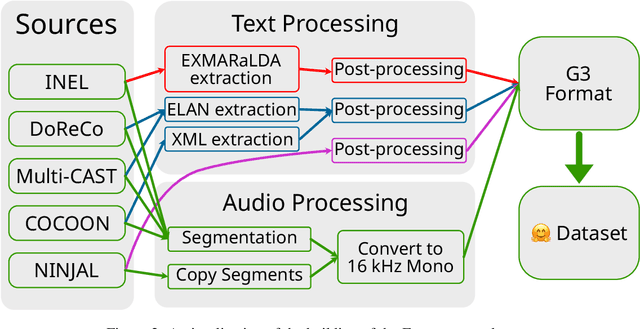
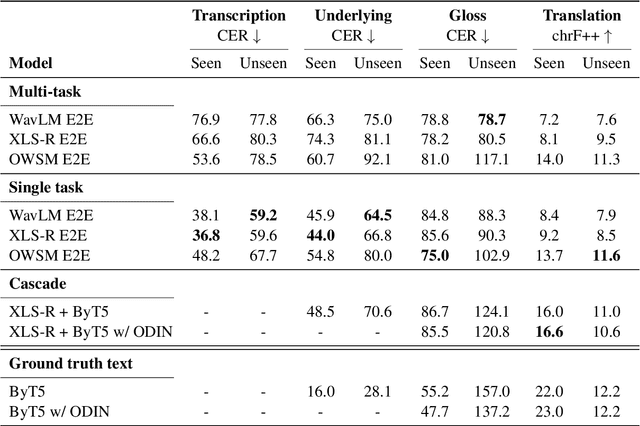
Thousands of the world's languages are in danger of extinction--a tremendous threat to cultural identities and human language diversity. Interlinear Glossed Text (IGT) is a form of linguistic annotation that can support documentation and resource creation for these languages' communities. IGT typically consists of (1) transcriptions, (2) morphological segmentation, (3) glosses, and (4) free translations to a majority language. We propose Wav2Gloss: a task to extract these four annotation components automatically from speech, and introduce the first dataset to this end, Fieldwork: a corpus of speech with all these annotations covering 37 languages with standard formatting and train/dev/test splits. We compare end-to-end and cascaded Wav2Gloss methods, with analysis suggesting that pre-trained decoders assist with translation and glossing, that multi-task and multilingual approaches are underperformant, and that end-to-end systems perform better than cascaded systems, despite the text-only systems' advantages. We provide benchmarks to lay the ground work for future research on IGT generation from speech.
Mitigating the Linguistic Gap with Phonemic Representations for Robust Multilingual Language Understanding
Feb 22, 2024Approaches to improving multilingual language understanding often require multiple languages during the training phase, rely on complicated training techniques, and -- importantly -- struggle with significant performance gaps between high-resource and low-resource languages. We hypothesize that the performance gaps between languages are affected by linguistic gaps between those languages and provide a novel solution for robust multilingual language modeling by employing phonemic representations (specifically, using phonemes as input tokens to LMs rather than subwords). We present quantitative evidence from three cross-lingual tasks that demonstrate the effectiveness of phonemic representation, which is further justified by a theoretical analysis of the cross-lingual performance gap.
Phonotactic Complexity across Dialects
Feb 20, 2024Received wisdom in linguistic typology holds that if the structure of a language becomes more complex in one dimension, it will simplify in another, building on the assumption that all languages are equally complex (Joseph and Newmeyer, 2012). We study this claim on a micro-level, using a tightly-controlled sample of Dutch dialects (across 366 collection sites) and Min dialects (across 60 sites), which enables a more fair comparison across varieties. Even at the dialect level, we find empirical evidence for a tradeoff between word length and a computational measure of phonotactic complexity from a LSTM-based phone-level language model-a result previously documented only at the language level. A generalized additive model (GAM) shows that dialects with low phonotactic complexity concentrate around the capital regions, which we hypothesize to correspond to prior hypotheses that language varieties of greater or more diverse populations show reduced phonotactic complexity. We also experiment with incorporating the auxiliary task of predicting syllable constituency, but do not find an increase in the negative correlation observed.
Automating Sound Change Prediction for Phylogenetic Inference: A Tukanoan Case Study
Feb 02, 2024We describe a set of new methods to partially automate linguistic phylogenetic inference given (1) cognate sets with their respective protoforms and sound laws, (2) a mapping from phones to their articulatory features and (3) a typological database of sound changes. We train a neural network on these sound change data to weight articulatory distances between phones and predict intermediate sound change steps between historical protoforms and their modern descendants, replacing a linguistic expert in part of a parsimony-based phylogenetic inference algorithm. In our best experiments on Tukanoan languages, this method produces trees with a Generalized Quartet Distance of 0.12 from a tree that used expert annotations, a significant improvement over other semi-automated baselines. We discuss potential benefits and drawbacks to our neural approach and parsimony-based tree prediction. We also experiment with a minimal generalization learner for automatic sound law induction, finding it comparably effective to sound laws from expert annotation. Our code is publicly available at https://github.com/cmu-llab/aiscp.
Counting the Bugs in ChatGPT's Wugs: A Multilingual Investigation into the Morphological Capabilities of a Large Language Model
Oct 26, 2023Large language models (LLMs) have recently reached an impressive level of linguistic capability, prompting comparisons with human language skills. However, there have been relatively few systematic inquiries into the linguistic capabilities of the latest generation of LLMs, and those studies that do exist (i) ignore the remarkable ability of humans to generalize, (ii) focus only on English, and (iii) investigate syntax or semantics and overlook other capabilities that lie at the heart of human language, like morphology. Here, we close these gaps by conducting the first rigorous analysis of the morphological capabilities of ChatGPT in four typologically varied languages (specifically, English, German, Tamil, and Turkish). We apply a version of Berko's (1958) wug test to ChatGPT, using novel, uncontaminated datasets for the four examined languages. We find that ChatGPT massively underperforms purpose-built systems, particularly in English. Overall, our results -- through the lens of morphology -- cast a new light on the linguistic capabilities of ChatGPT, suggesting that claims of human-like language skills are premature and misleading.
ChatGPT MT: Competitive for High- (but not Low-) Resource Languages
Sep 14, 2023
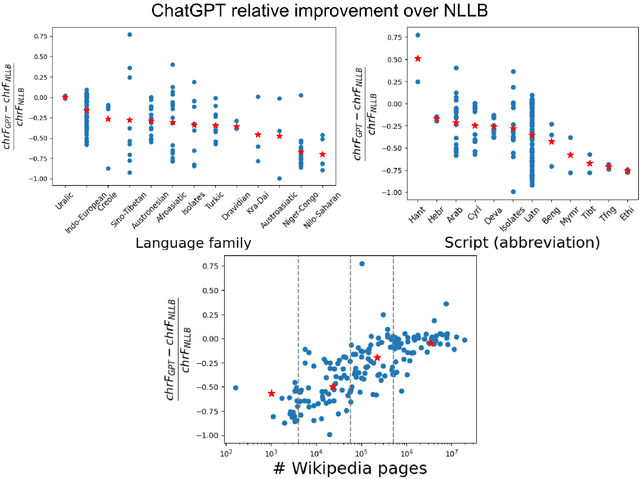

Large language models (LLMs) implicitly learn to perform a range of language tasks, including machine translation (MT). Previous studies explore aspects of LLMs' MT capabilities. However, there exist a wide variety of languages for which recent LLM MT performance has never before been evaluated. Without published experimental evidence on the matter, it is difficult for speakers of the world's diverse languages to know how and whether they can use LLMs for their languages. We present the first experimental evidence for an expansive set of 204 languages, along with MT cost analysis, using the FLORES-200 benchmark. Trends reveal that GPT models approach or exceed traditional MT model performance for some high-resource languages (HRLs) but consistently lag for low-resource languages (LRLs), under-performing traditional MT for 84.1% of languages we covered. Our analysis reveals that a language's resource level is the most important feature in determining ChatGPT's relative ability to translate it, and suggests that ChatGPT is especially disadvantaged for LRLs and African languages.