 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDebasmita Bhattacharya
Measuring Entrainment in Spontaneous Code-switched Speech
Nov 13, 2023
It is well-known that interlocutors who entrain to one another have more successful conversations than those who do not. Previous research has shown that interlocutors entrain on linguistic features in both written and spoken monolingual domains. More recent work on code-switched communication has also shown preliminary evidence of entrainment on certain aspects of code-switching (CSW). However, such studies of entrainment in code-switched domains have been extremely few and restricted to human-machine textual interactions. Our work studies code-switched spontaneous speech between humans by answering the following questions: 1) Do patterns of written and spoken entrainment in monolingual settings generalize to code-switched settings? 2) Do patterns of entrainment on code-switching in generated text generalize to spontaneous code-switched speech? We find evidence of affirmative answers to both of these questions, with important implications for the potentially "universal" nature of entrainment as a communication phenomenon, and potential applications in inclusive and interactive speech technology.
Examining Racial Bias in an Online Abuse Corpus with Structural Topic Modeling
May 26, 2020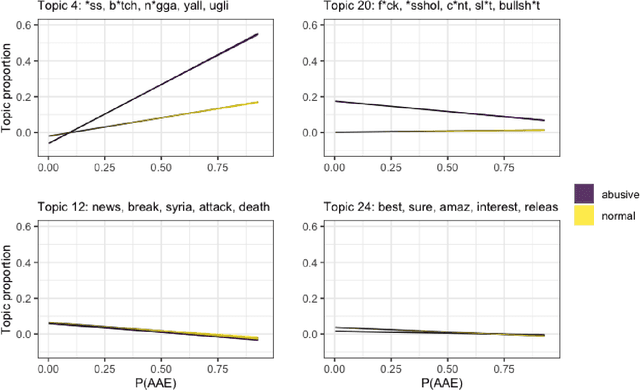
We use structural topic modeling to examine racial bias in data collected to train models to detect hate speech and abusive language in social media posts. We augment the abusive language dataset by adding an additional feature indicating the predicted probability of the tweet being written in African-American English. We then use structural topic modeling to examine the content of the tweets and how the prevalence of different topics is related to both abusiveness annotation and dialect prediction. We find that certain topics are disproportionately racialized and considered abusive. We discuss how topic modeling may be a useful approach for identifying bias in annotated data.
Racial Bias in Hate Speech and Abusive Language Detection Datasets
May 29, 2019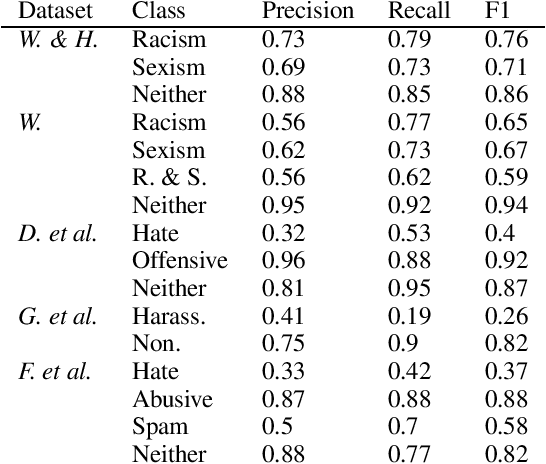
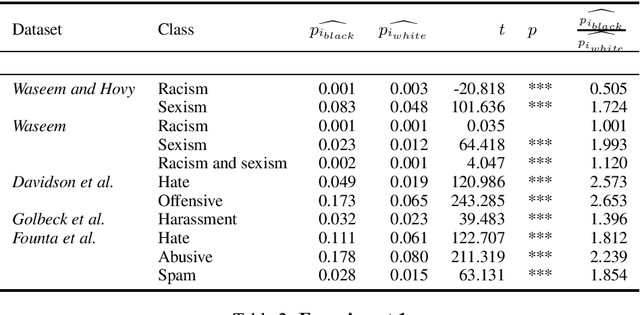
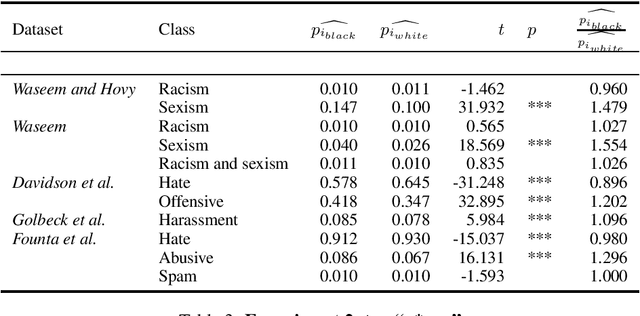
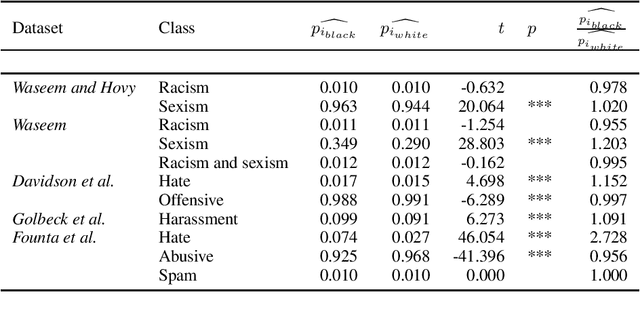
Technologies for abusive language detection are being developed and applied with little consideration of their potential biases. We examine racial bias in five different sets of Twitter data annotated for hate speech and abusive language. We train classifiers on these datasets and compare the predictions of these classifiers on tweets written in African-American English with those written in Standard American English. The results show evidence of systematic racial bias in all datasets, as classifiers trained on them tend to predict that tweets written in African-American English are abusive at substantially higher rates. If these abusive language detection systems are used in the field they will therefore have a disproportionate negative impact on African-American social media users. Consequently, these systems may discriminate against the groups who are often the targets of the abuse we are trying to detect.