 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDenny Zhou
Best Practices and Lessons Learned on Synthetic Data for Language Models
Apr 11, 2024
The success of AI models relies on the availability of large, diverse, and high-quality datasets, which can be challenging to obtain due to data scarcity, privacy concerns, and high costs. Synthetic data has emerged as a promising solution by generating artificial data that mimics real-world patterns. This paper provides an overview of synthetic data research, discussing its applications, challenges, and future directions. We present empirical evidence from prior art to demonstrate its effectiveness and highlight the importance of ensuring its factuality, fidelity, and unbiasedness. We emphasize the need for responsible use of synthetic data to build more powerful, inclusive, and trustworthy language models.
Chain of Thought Empowers Transformers to Solve Inherently Serial Problems
Feb 20, 2024Instructing the model to generate a sequence of intermediate steps, a.k.a., a chain of thought (CoT), is a highly effective method to improve the accuracy of large language models (LLMs) on arithmetics and symbolic reasoning tasks. However, the mechanism behind CoT remains unclear. This work provides a theoretical understanding of the power of CoT for decoder-only transformers through the lens of expressiveness. Conceptually, CoT empowers the model with the ability to perform inherently serial computation, which is otherwise lacking in transformers, especially when depth is low. Given input length $n$, previous works have shown that constant-depth transformers with finite precision $\mathsf{poly}(n)$ embedding size can only solve problems in $\mathsf{TC}^0$ without CoT. We first show an even tighter expressiveness upper bound for constant-depth transformers with constant-bit precision, which can only solve problems in $\mathsf{AC}^0$, a proper subset of $ \mathsf{TC}^0$. However, with $T$ steps of CoT, constant-depth transformers using constant-bit precision and $O(\log n)$ embedding size can solve any problem solvable by boolean circuits of size $T$. Empirically, enabling CoT dramatically improves the accuracy for tasks that are hard for parallel computation, including the composition of permutation groups, iterated squaring, and circuit value problems, especially for low-depth transformers.
Chain-of-Thought Reasoning Without Prompting
Feb 15, 2024In enhancing the reasoning capabilities of large language models (LLMs), prior research primarily focuses on specific prompting techniques such as few-shot or zero-shot chain-of-thought (CoT) prompting. These methods, while effective, often involve manually intensive prompt engineering. Our study takes a novel approach by asking: Can LLMs reason effectively without prompting? Our findings reveal that, intriguingly, CoT reasoning paths can be elicited from pre-trained LLMs by simply altering the \textit{decoding} process. Rather than conventional greedy decoding, we investigate the top-$k$ alternative tokens, uncovering that CoT paths are frequently inherent in these sequences. This approach not only bypasses the confounders of prompting but also allows us to assess the LLMs' \textit{intrinsic} reasoning abilities. Moreover, we observe that the presence of a CoT in the decoding path correlates with a higher confidence in the model's decoded answer. This confidence metric effectively differentiates between CoT and non-CoT paths. Extensive empirical studies on various reasoning benchmarks show that the proposed CoT-decoding substantially outperforms the standard greedy decoding.
Premise Order Matters in Reasoning with Large Language Models
Feb 14, 2024Large language models (LLMs) have accomplished remarkable reasoning performance in various domains. However, in the domain of reasoning tasks, we discover a frailty: LLMs are surprisingly brittle to the ordering of the premises, despite the fact that such ordering does not alter the underlying task. In particular, we observe that LLMs achieve the best performance when the premise order aligns with the context required in intermediate reasoning steps. For example, in deductive reasoning tasks, presenting the premises in the same order as the ground truth proof in the prompt (as opposed to random ordering) drastically increases the model's accuracy. We first examine the effect of premise ordering on deductive reasoning on a variety of LLMs, and our evaluation shows that permuting the premise order can cause a performance drop of over 30%. In addition, we release the benchmark R-GSM, based on GSM8K, to examine the ordering effect for mathematical problem-solving, and we again observe a significant drop in accuracy, relative to the original GSM8K benchmark.
Transformers Can Achieve Length Generalization But Not Robustly
Feb 14, 2024Length generalization, defined as the ability to extrapolate from shorter training sequences to longer test ones, is a significant challenge for language models. This issue persists even with large-scale Transformers handling relatively straightforward tasks. In this paper, we test the Transformer's ability of length generalization using the task of addition of two integers. We show that the success of length generalization is intricately linked to the data format and the type of position encoding. Using the right combination of data format and position encodings, we show for the first time that standard Transformers can extrapolate to a sequence length that is 2.5x the input length. Nevertheless, unlike in-distribution generalization, length generalization remains fragile, significantly influenced by factors like random weight initialization and training data order, leading to large variances across different random seeds.
Self-Discover: Large Language Models Self-Compose Reasoning Structures
Feb 06, 2024We introduce SELF-DISCOVER, a general framework for LLMs to self-discover the task-intrinsic reasoning structures to tackle complex reasoning problems that are challenging for typical prompting methods. Core to the framework is a self-discovery process where LLMs select multiple atomic reasoning modules such as critical thinking and step-by-step thinking, and compose them into an explicit reasoning structure for LLMs to follow during decoding. SELF-DISCOVER substantially improves GPT-4 and PaLM 2's performance on challenging reasoning benchmarks such as BigBench-Hard, grounded agent reasoning, and MATH, by as much as 32% compared to Chain of Thought (CoT). Furthermore, SELF-DISCOVER outperforms inference-intensive methods such as CoT-Self-Consistency by more than 20%, while requiring 10-40x fewer inference compute. Finally, we show that the self-discovered reasoning structures are universally applicable across model families: from PaLM 2-L to GPT-4, and from GPT-4 to Llama2, and share commonalities with human reasoning patterns.
Universal Self-Consistency for Large Language Model Generation
Nov 29, 2023Self-consistency with chain-of-thought prompting (CoT) has demonstrated remarkable performance gains on various challenging tasks, by utilizing multiple reasoning paths sampled from large language models (LLMs). However, self-consistency relies on the answer extraction process to aggregate multiple solutions, which is not applicable to free-form answers. In this work, we propose Universal Self-Consistency (USC), which leverages LLMs themselves to select the most consistent answer among multiple candidates. We evaluate USC on a variety of benchmarks, including mathematical reasoning, code generation, long-context summarization, and open-ended question answering. On open-ended generation tasks where the original self-consistency method is not applicable, USC effectively utilizes multiple samples and improves the performance. For mathematical reasoning, USC matches the standard self-consistency performance without requiring the answer formats to be similar. Finally, without access to execution results, USC also matches the execution-based voting performance on code generation.
Instruction-Following Evaluation for Large Language Models
Nov 14, 2023One core capability of Large Language Models (LLMs) is to follow natural language instructions. However, the evaluation of such abilities is not standardized: Human evaluations are expensive, slow, and not objectively reproducible, while LLM-based auto-evaluation is potentially biased or limited by the ability of the evaluator LLM. To overcome these issues, we introduce Instruction-Following Eval (IFEval) for large language models. IFEval is a straightforward and easy-to-reproduce evaluation benchmark. It focuses on a set of "verifiable instructions" such as "write in more than 400 words" and "mention the keyword of AI at least 3 times". We identified 25 types of those verifiable instructions and constructed around 500 prompts, with each prompt containing one or more verifiable instructions. We show evaluation results of two widely available LLMs on the market. Our code and data can be found at https://github.com/google-research/google-research/tree/master/instruction_following_eval
Large Language Models can Learn Rules
Oct 10, 2023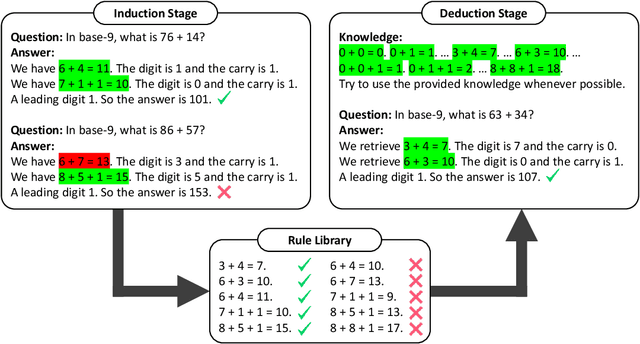
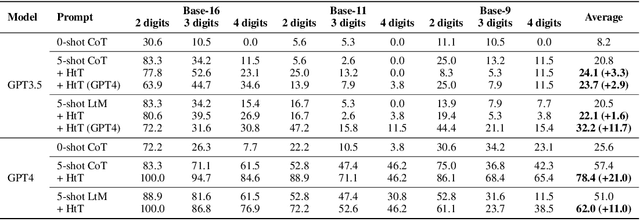
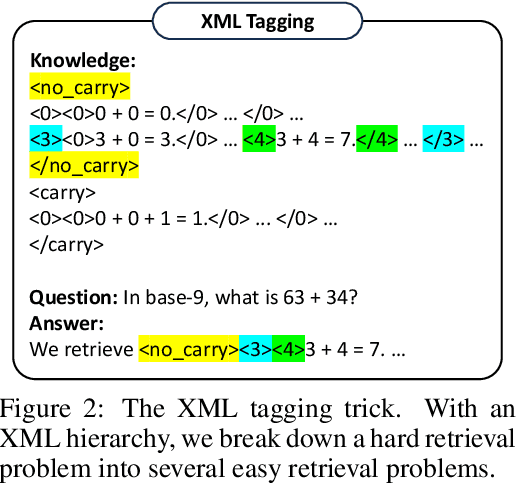
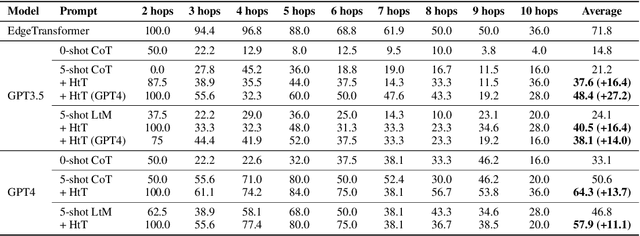
When prompted with a few examples and intermediate steps, large language models (LLMs) have demonstrated impressive performance in various reasoning tasks. However, prompting methods that rely on implicit knowledge in an LLM often hallucinate incorrect answers when the implicit knowledge is wrong or inconsistent with the task. To tackle this problem, we present Hypotheses-to-Theories (HtT), a framework that learns a rule library for reasoning with LLMs. HtT contains two stages, an induction stage and a deduction stage. In the induction stage, an LLM is first asked to generate and verify rules over a set of training examples. Rules that appear and lead to correct answers sufficiently often are collected to form a rule library. In the deduction stage, the LLM is then prompted to employ the learned rule library to perform reasoning to answer test questions. Experiments on both numerical reasoning and relational reasoning problems show that HtT improves existing prompting methods, with an absolute gain of 11-27% in accuracy. The learned rules are also transferable to different models and to different forms of the same problem.
Take a Step Back: Evoking Reasoning via Abstraction in Large Language Models
Oct 09, 2023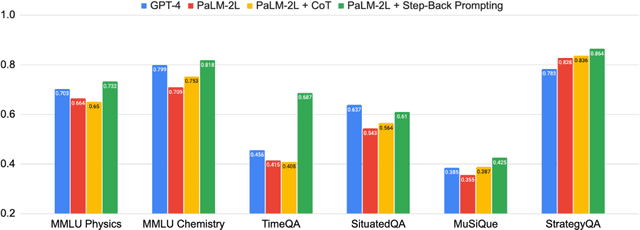
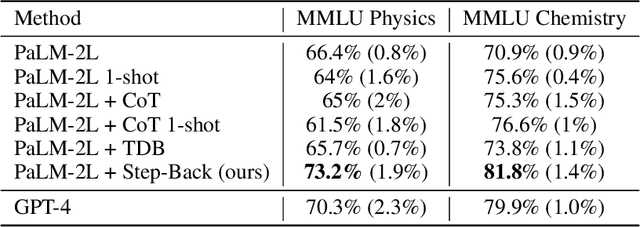
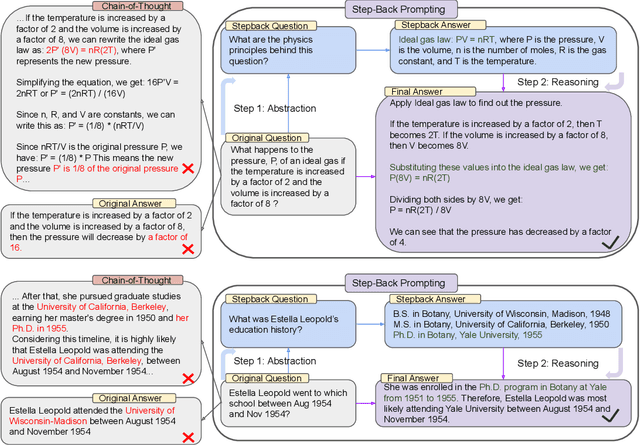
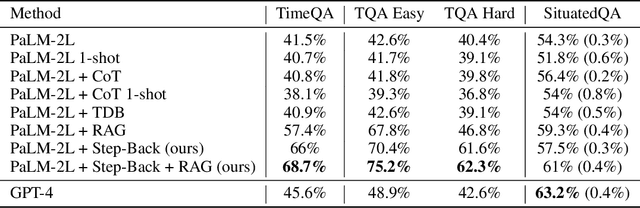
We present Step-Back Prompting, a simple prompting technique that enables LLMs to do abstractions to derive high-level concepts and first principles from instances containing specific details. Using the concepts and principles to guide the reasoning steps, LLMs significantly improve their abilities in following a correct reasoning path towards the solution. We conduct experiments of Step-Back Prompting with PaLM-2L models and observe substantial performance gains on a wide range of challenging reasoning-intensive tasks including STEM, Knowledge QA, and Multi-Hop Reasoning. For instance, Step-Back Prompting improves PaLM-2L performance on MMLU Physics and Chemistry by 7% and 11%, TimeQA by 27%, and MuSiQue by 7%.