 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDimitris Spathis
A collection of the accepted papers for the Human-Centric Representation Learning workshop at AAAI 2024
Mar 14, 2024
This non-archival index is not complete, as some accepted papers chose to opt-out of inclusion. The list of all accepted papers is available on the workshop website.
Learning under Label Noise through Few-Shot Human-in-the-Loop Refinement
Jan 25, 2024Wearable technologies enable continuous monitoring of various health metrics, such as physical activity, heart rate, sleep, and stress levels. A key challenge with wearable data is obtaining quality labels. Unlike modalities like video where the videos themselves can be effectively used to label objects or events, wearable data do not contain obvious cues about the physical manifestation of the users and usually require rich metadata. As a result, label noise can become an increasingly thorny issue when labeling such data. In this paper, we propose a novel solution to address noisy label learning, entitled Few-Shot Human-in-the-Loop Refinement (FHLR). Our method initially learns a seed model using weak labels. Next, it fine-tunes the seed model using a handful of expert corrections. Finally, it achieves better generalizability and robustness by merging the seed and fine-tuned models via weighted parameter averaging. We evaluate our approach on four challenging tasks and datasets, and compare it against eight competitive baselines designed to deal with noisy labels. We show that FHLR achieves significantly better performance when learning from noisy labels and achieves state-of-the-art by a large margin, with up to 19% accuracy improvement under symmetric and asymmetric noise. Notably, we find that FHLR is particularly robust to increased label noise, unlike prior works that suffer from severe performance degradation. Our work not only achieves better generalization in high-stakes health sensing benchmarks but also sheds light on how noise affects commonly-used models.
Balancing Continual Learning and Fine-tuning for Human Activity Recognition
Jan 04, 2024Wearable-based Human Activity Recognition (HAR) is a key task in human-centric machine learning due to its fundamental understanding of human behaviours. Due to the dynamic nature of human behaviours, continual learning promises HAR systems that are tailored to users' needs. However, because of the difficulty in collecting labelled data with wearable sensors, existing approaches that focus on supervised continual learning have limited applicability, while unsupervised continual learning methods only handle representation learning while delaying classifier training to a later stage. This work explores the adoption and adaptation of CaSSLe, a continual self-supervised learning model, and Kaizen, a semi-supervised continual learning model that balances representation learning and down-stream classification, for the task of wearable-based HAR. These schemes re-purpose contrastive learning for knowledge retention and, Kaizen combines that with self-training in a unified scheme that can leverage unlabelled and labelled data for continual learning. In addition to comparing state-of-the-art self-supervised continual learning schemes, we further investigated the importance of different loss terms and explored the trade-off between knowledge retention and learning from new tasks. In particular, our extensive evaluation demonstrated that the use of a weighting factor that reflects the ratio between learned and new classes achieves the best overall trade-off in continual learning.
Evaluating Fairness in Self-supervised and Supervised Models for Sequential Data
Jan 03, 2024Self-supervised learning (SSL) has become the de facto training paradigm of large models where pre-training is followed by supervised fine-tuning using domain-specific data and labels. Hypothesizing that SSL models would learn more generic, hence less biased, representations, this study explores the impact of pre-training and fine-tuning strategies on fairness (i.e., performing equally on different demographic breakdowns). Motivated by human-centric applications on real-world timeseries data, we interpret inductive biases on the model, layer, and metric levels by systematically comparing SSL models to their supervised counterparts. Our findings demonstrate that SSL has the capacity to achieve performance on par with supervised methods while significantly enhancing fairness--exhibiting up to a 27% increase in fairness with a mere 1% loss in performance through self-supervision. Ultimately, this work underscores SSL's potential in human-centric computing, particularly high-stakes, data-scarce application domains like healthcare.
FairComp: Workshop on Fairness and Robustness in Machine Learning for Ubiquitous Computing
Sep 22, 2023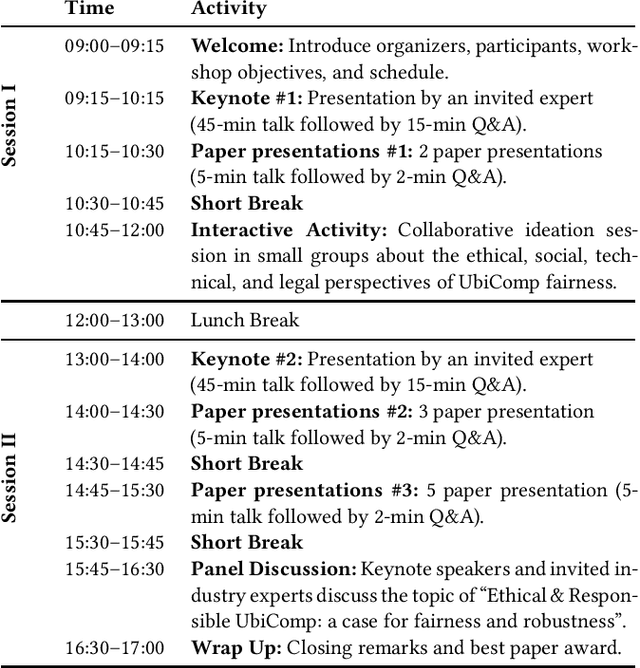
How can we ensure that Ubiquitous Computing (UbiComp) research outcomes are both ethical and fair? While fairness in machine learning (ML) has gained traction in recent years, fairness in UbiComp remains unexplored. This workshop aims to discuss fairness in UbiComp research and its social, technical, and legal implications. From a social perspective, we will examine the relationship between fairness and UbiComp research and identify pathways to ensure that ubiquitous technologies do not cause harm or infringe on individual rights. From a technical perspective, we will initiate a discussion on data practices to develop bias mitigation approaches tailored to UbiComp research. From a legal perspective, we will examine how new policies shape our community's work and future research. We aim to foster a vibrant community centered around the topic of responsible UbiComp, while also charting a clear path for future research endeavours in this field.
The first step is the hardest: Pitfalls of Representing and Tokenizing Temporal Data for Large Language Models
Sep 12, 2023
Large Language Models (LLMs) have demonstrated remarkable generalization across diverse tasks, leading individuals to increasingly use them as personal assistants and universal computing engines. Nevertheless, a notable obstacle emerges when feeding numerical/temporal data into these models, such as data sourced from wearables or electronic health records. LLMs employ tokenizers in their input that break down text into smaller units. However, tokenizers are not designed to represent numerical values and might struggle to understand repetitive patterns and context, treating consecutive values as separate tokens and disregarding their temporal relationships. Here, we discuss recent works that employ LLMs for human-centric tasks such as in mobile health sensing and present a case study showing that popular LLMs tokenize temporal data incorrectly. To address that, we highlight potential solutions such as prompt tuning with lightweight embedding layers as well as multimodal adapters, that can help bridge this "modality gap". While the capability of language models to generalize to other modalities with minimal or no finetuning is exciting, this paper underscores the fact that their outputs cannot be meaningful if they stumble over input nuances.
Latent Masking for Multimodal Self-supervised Learning in Health Timeseries
Jul 31, 2023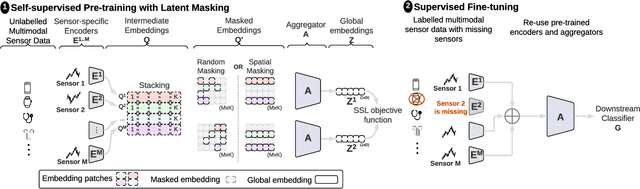
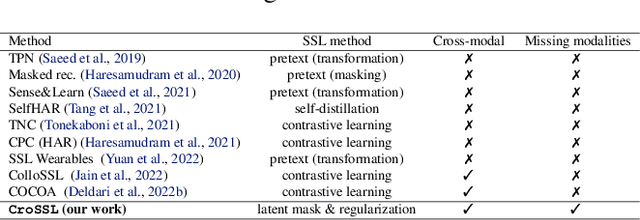
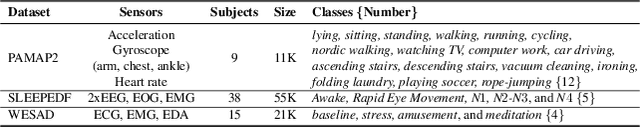
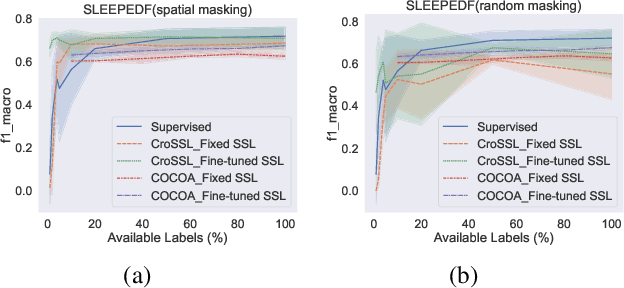
Limited availability of labeled data for machine learning on biomedical time-series hampers progress in the field. Self-supervised learning (SSL) is a promising approach to learning data representations without labels. However, current SSL methods require expensive computations for negative pairs and are designed for single modalities, limiting their versatility. To overcome these limitations, we introduce CroSSL (Cross-modal SSL). CroSSL introduces two novel concepts: masking intermediate embeddings from modality-specific encoders and aggregating them into a global embedding using a cross-modal aggregator. This enables the handling of missing modalities and end-to-end learning of cross-modal patterns without prior data preprocessing or time-consuming negative-pair sampling. We evaluate CroSSL on various multimodal time-series benchmarks, including both medical-grade and consumer biosignals. Our results demonstrate superior performance compared to previous SSL techniques and supervised benchmarks with minimal labeled data. We additionally analyze the impact of different masking ratios and strategies and assess the robustness of the learned representations to missing modalities. Overall, our work achieves state-of-the-art performance while highlighting the benefits of masking latent embeddings for cross-modal learning in temporal health data.
UDAMA: Unsupervised Domain Adaptation through Multi-discriminator Adversarial Training with Noisy Labels Improves Cardio-fitness Prediction
Jul 31, 2023Deep learning models have shown great promise in various healthcare monitoring applications. However, most healthcare datasets with high-quality (gold-standard) labels are small-scale, as directly collecting ground truth is often costly and time-consuming. As a result, models developed and validated on small-scale datasets often suffer from overfitting and do not generalize well to unseen scenarios. At the same time, large amounts of imprecise (silver-standard) labeled data, annotated by approximate methods with the help of modern wearables and in the absence of ground truth validation, are starting to emerge. However, due to measurement differences, this data displays significant label distribution shifts, which motivates the use of domain adaptation. To this end, we introduce UDAMA, a method with two key components: Unsupervised Domain Adaptation and Multidiscriminator Adversarial Training, where we pre-train on the silver-standard data and employ adversarial adaptation with the gold-standard data along with two domain discriminators. In particular, we showcase the practical potential of UDAMA by applying it to Cardio-respiratory fitness (CRF) prediction. CRF is a crucial determinant of metabolic disease and mortality, and it presents labels with various levels of noise (goldand silver-standard), making it challenging to establish an accurate prediction model. Our results show promising performance by alleviating distribution shifts in various label shift settings. Additionally, by using data from two free-living cohort studies (Fenland and BBVS), we show that UDAMA consistently outperforms up to 12% compared to competitive transfer learning and state-of-the-art domain adaptation models, paving the way for leveraging noisy labeled data to improve fitness estimation at scale.
Practical self-supervised continual learning with continual fine-tuning
Mar 30, 2023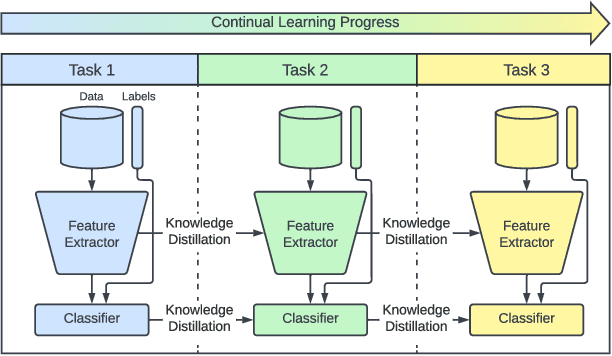
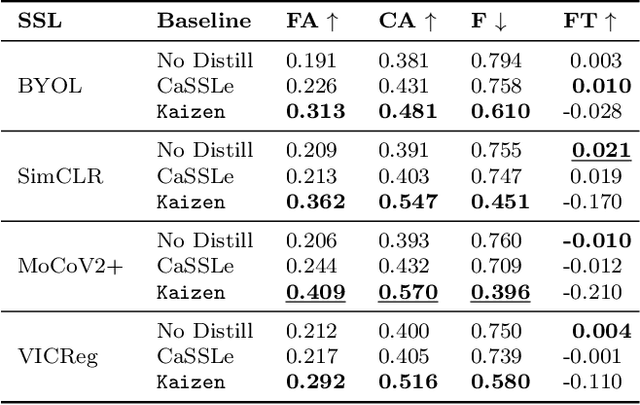
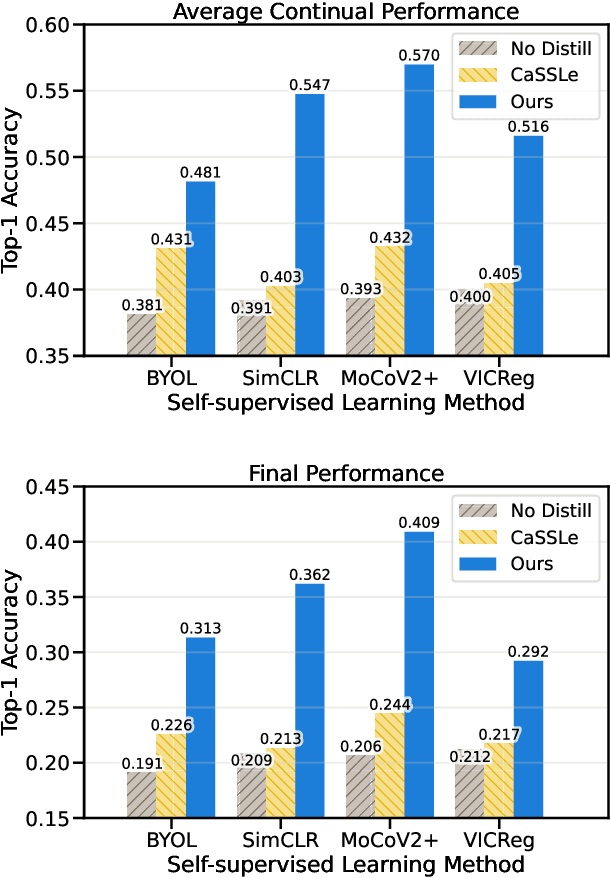

Self-supervised learning (SSL) has shown remarkable performance in computer vision tasks when trained offline. However, in a Continual Learning (CL) scenario where new data is introduced progressively, models still suffer from catastrophic forgetting. Retraining a model from scratch to adapt to newly generated data is time-consuming and inefficient. Previous approaches suggested re-purposing self-supervised objectives with knowledge distillation to mitigate forgetting across tasks, assuming that labels from all tasks are available during fine-tuning. In this paper, we generalize self-supervised continual learning in a practical setting where available labels can be leveraged in any step of the SSL process. With an increasing number of continual tasks, this offers more flexibility in the pre-training and fine-tuning phases. With Kaizen, we introduce a training architecture that is able to mitigate catastrophic forgetting for both the feature extractor and classifier with a carefully designed loss function. By using a set of comprehensive evaluation metrics reflecting different aspects of continual learning, we demonstrated that Kaizen significantly outperforms previous SSL models in competitive vision benchmarks, with up to 16.5% accuracy improvement on split CIFAR-100. Kaizen is able to balance the trade-off between knowledge retention and learning from new data with an end-to-end model, paving the way for practical deployment of continual learning systems.
Beyond Accuracy: A Critical Review of Fairness in Machine Learning for Mobile and Wearable Computing
Mar 27, 2023

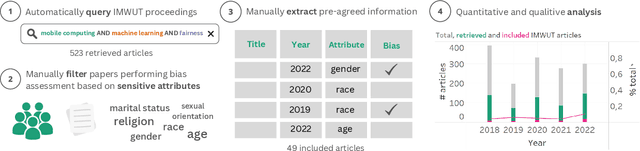

The field of mobile, wearable, and ubiquitous computing (UbiComp) is undergoing a revolutionary integration of machine learning. Devices can now diagnose diseases, predict heart irregularities, and unlock the full potential of human cognition. However, the underlying algorithms are not immune to biases with respect to sensitive attributes (e.g., gender, race), leading to discriminatory outcomes. The research communities of HCI and AI-Ethics have recently started to explore ways of reporting information about datasets to surface and, eventually, counter those biases. The goal of this work is to explore the extent to which the UbiComp community has adopted such ways of reporting and highlight potential shortcomings. Through a systematic review of papers published in the Proceedings of the ACM Interactive, Mobile, Wearable and Ubiquitous Technologies (IMWUT) journal over the past 5 years (2018-2022), we found that progress on algorithmic fairness within the UbiComp community lags behind. Our findings show that only a small portion (5%) of published papers adheres to modern fairness reporting, while the overwhelming majority thereof focuses on accuracy or error metrics. In light of these findings, our work provides practical guidelines for the design and development of ubiquitous technologies that not only strive for accuracy but also for fairness.