 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDimitris Stripelis
MetisFL: An Embarrassingly Parallelized Controller for Scalable & Efficient Federated Learning Workflows
Nov 13, 2023




A Federated Learning (FL) system typically consists of two core processing entities: the federation controller and the learners. The controller is responsible for managing the execution of FL workflows across learners and the learners for training and evaluating federated models over their private datasets. While executing an FL workflow, the FL system has no control over the computational resources or data of the participating learners. Still, it is responsible for other operations, such as model aggregation, task dispatching, and scheduling. These computationally heavy operations generally need to be handled by the federation controller. Even though many FL systems have been recently proposed to facilitate the development of FL workflows, most of these systems overlook the scalability of the controller. To meet this need, we designed and developed a novel FL system called MetisFL, where the federation controller is the first-class citizen. MetisFL re-engineers all the operations conducted by the federation controller to accelerate the training of large-scale FL workflows. By quantitatively comparing MetisFL against other state-of-the-art FL systems, we empirically demonstrate that MetisFL leads to a 10-fold wall-clock time execution boost across a wide range of challenging FL workflows with increasing model sizes and federation sites.
Federated Learning over Harmonized Data Silos
May 15, 2023



Federated Learning is a distributed machine learning approach that enables geographically distributed data silos to collaboratively learn a joint machine learning model without sharing data. Most of the existing work operates on unstructured data, such as images or text, or on structured data assumed to be consistent across the different sites. However, sites often have different schemata, data formats, data values, and access patterns. The field of data integration has developed many methods to address these challenges, including techniques for data exchange and query rewriting using declarative schema mappings, and for entity linkage. Therefore, we propose an architectural vision for an end-to-end Federated Learning and Integration system, incorporating the critical steps of data harmonization and data imputation, to spur further research on the intersection of data management information systems and machine learning.
Towards Sparsified Federated Neuroimaging Models via Weight Pruning
Aug 24, 2022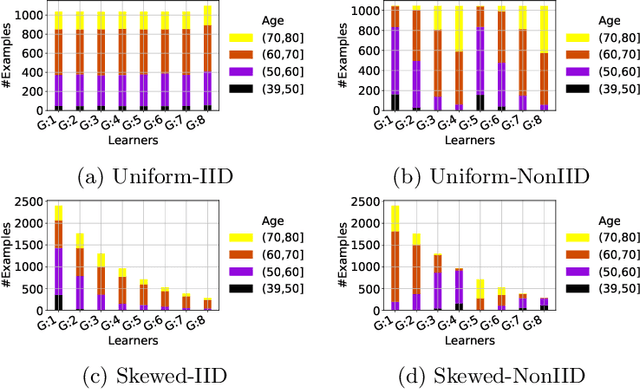
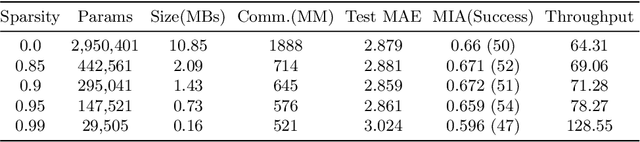
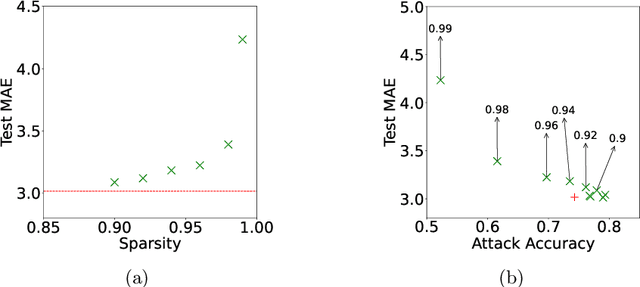
Federated training of large deep neural networks can often be restrictive due to the increasing costs of communicating the updates with increasing model sizes. Various model pruning techniques have been designed in centralized settings to reduce inference times. Combining centralized pruning techniques with federated training seems intuitive for reducing communication costs -- by pruning the model parameters right before the communication step. Moreover, such a progressive model pruning approach during training can also reduce training times/costs. To this end, we propose FedSparsify, which performs model pruning during federated training. In our experiments in centralized and federated settings on the brain age prediction task (estimating a person's age from their brain MRI), we demonstrate that models can be pruned up to 95% sparsity without affecting performance even in challenging federated learning environments with highly heterogeneous data distributions. One surprising benefit of model pruning is improved model privacy. We demonstrate that models with high sparsity are less susceptible to membership inference attacks, a type of privacy attack.
Secure Federated Learning for Neuroimaging
May 11, 2022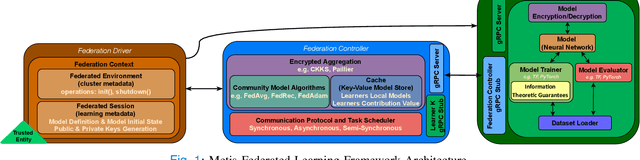
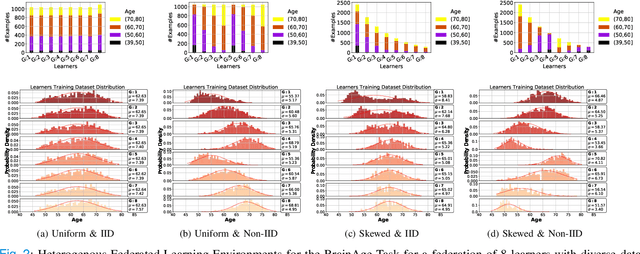
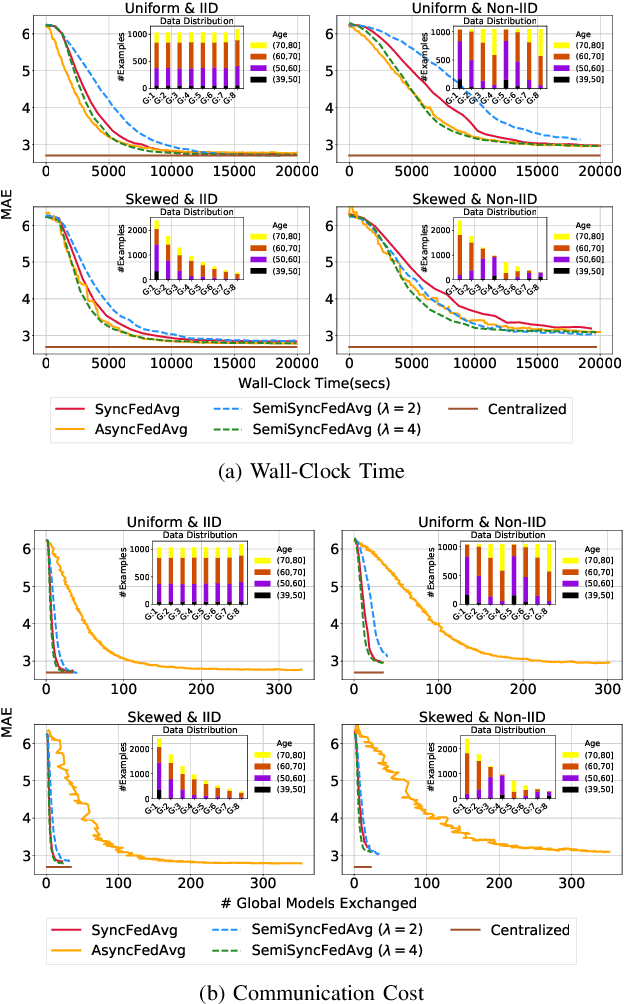
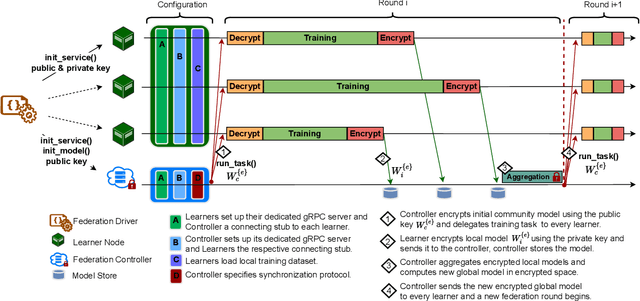
The amount of biomedical data continues to grow rapidly. However, the ability to collect data from multiple sites for joint analysis remains challenging due to security, privacy, and regulatory concerns. We present a Secure Federated Learning architecture, MetisFL, which enables distributed training of neural networks over multiple data sources without sharing data. Each site trains the neural network over its private data for some time, then shares the neural network parameters (i.e., weights, gradients) with a Federation Controller, which in turn aggregates the local models, sends the resulting community model back to each site, and the process repeats. Our architecture provides strong security and privacy. First, sample data never leaves a site. Second, neural parameters are encrypted before transmission and the community model is computed under fully-homomorphic encryption. Finally, we use information-theoretic methods to limit information leakage from the neural model to prevent a curious site from performing membership attacks. We demonstrate this architecture in neuroimaging. Specifically, we investigate training neural models to classify Alzheimer's disease, and estimate Brain Age, from magnetic resonance imaging datasets distributed across multiple sites, including heterogeneous environments where sites have different amounts of data, statistical distributions, and computational capabilities.
Performance Weighting for Robust Federated Learning Against Corrupted Sources
May 02, 2022



Federated Learning has emerged as a dominant computational paradigm for distributed machine learning. Its unique data privacy properties allow us to collaboratively train models while offering participating clients certain privacy-preserving guarantees. However, in real-world applications, a federated environment may consist of a mixture of benevolent and malicious clients, with the latter aiming to corrupt and degrade federated model's performance. Different corruption schemes may be applied such as model poisoning and data corruption. Here, we focus on the latter, the susceptibility of federated learning to various data corruption attacks. We show that the standard global aggregation scheme of local weights is inefficient in the presence of corrupted clients. To mitigate this problem, we propose a class of task-oriented performance-based methods computed over a distributed validation dataset with the goal to detect and mitigate corrupted clients. Specifically, we construct a robust weight aggregation scheme based on geometric mean and demonstrate its effectiveness under random label shuffling and targeted label flipping attacks.
Federated Progressive Sparsification (Purge, Merge, Tune)+
Apr 26, 2022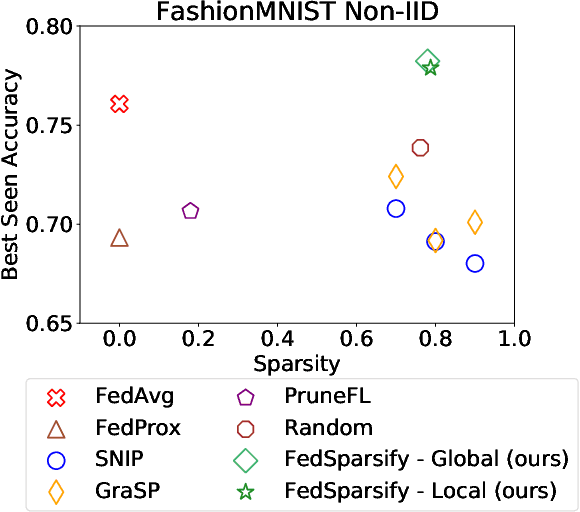
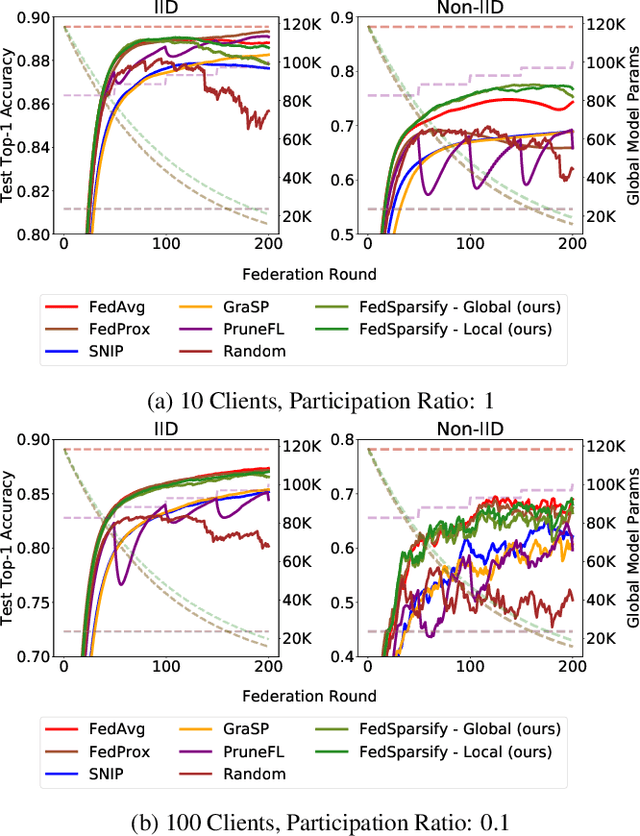


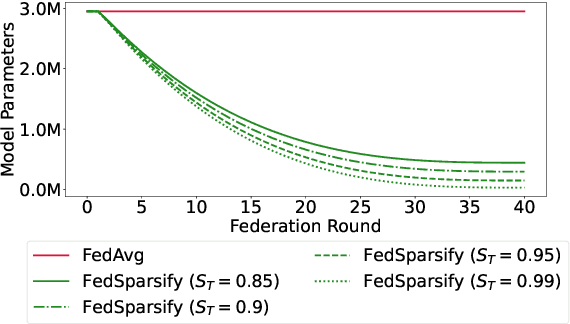
To improve federated training of neural networks, we develop FedSparsify, a sparsification strategy based on progressive weight magnitude pruning. Our method has several benefits. First, since the size of the network becomes increasingly smaller, computation and communication costs during training are reduced. Second, the models are incrementally constrained to a smaller set of parameters, which facilitates alignment/merging of the local models and improved learning performance at high sparsification rates. Third, the final sparsified model is significantly smaller, which improves inference efficiency and optimizes operations latency during encrypted communication. We show experimentally that FedSparsify learns a subnetwork of both high sparsity and learning performance. Our sparse models can reach a tenth of the size of the original model with the same or better accuracy compared to existing pruning and nonpruning baselines.
Federated Named Entity Recognition
Mar 28, 2022



We present an analysis of the performance of Federated Learning in a paradigmatic natural-language processing task: Named-Entity Recognition (NER). For our evaluation, we use the language-independent CoNLL-2003 dataset as our benchmark dataset and a Bi-LSTM-CRF model as our benchmark NER model. We show that federated training reaches almost the same performance as the centralized model, though with some performance degradation as the learning environments become more heterogeneous. We also show the convergence rate of federated models for NER. Finally, we discuss existing challenges of Federated Learning for NLP applications that can foster future research directions.
Secure Neuroimaging Analysis using Federated Learning with Homomorphic Encryption
Aug 07, 2021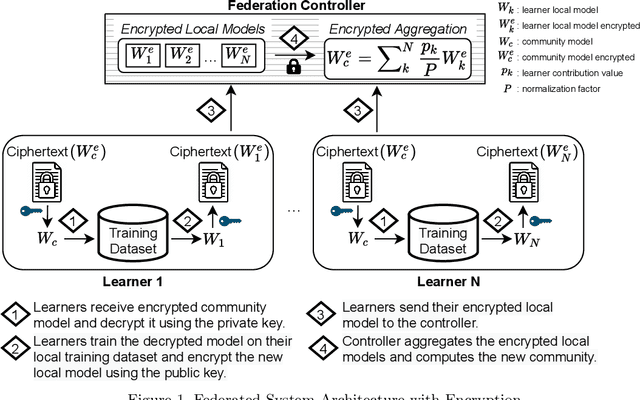
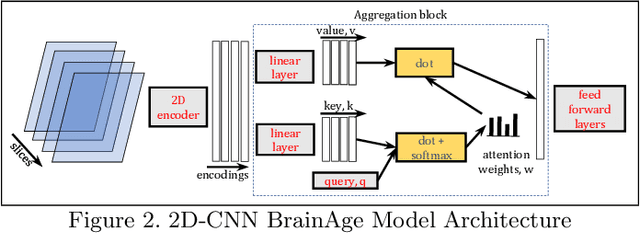
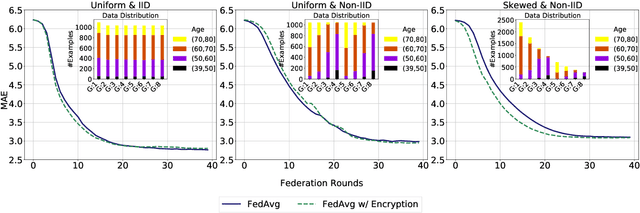
Federated learning (FL) enables distributed computation of machine learning models over various disparate, remote data sources, without requiring to transfer any individual data to a centralized location. This results in an improved generalizability of models and efficient scaling of computation as more sources and larger datasets are added to the federation. Nevertheless, recent membership attacks show that private or sensitive personal data can sometimes be leaked or inferred when model parameters or summary statistics are shared with a central site, requiring improved security solutions. In this work, we propose a framework for secure FL using fully-homomorphic encryption (FHE). Specifically, we use the CKKS construction, an approximate, floating point compatible scheme that benefits from ciphertext packing and rescaling. In our evaluation on large-scale brain MRI datasets, we use our proposed secure FL framework to train a deep learning model to predict a person's age from distributed MRI scans, a common benchmarking task, and demonstrate that there is no degradation in the learning performance between the encrypted and non-encrypted federated models.
Membership Inference Attacks on Deep Regression Models for Neuroimaging
Jun 03, 2021


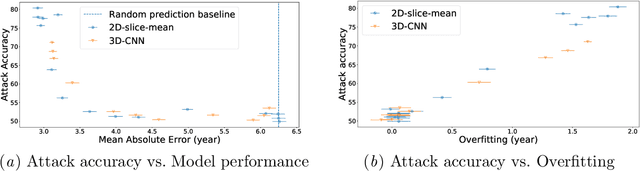
Ensuring the privacy of research participants is vital, even more so in healthcare environments. Deep learning approaches to neuroimaging require large datasets, and this often necessitates sharing data between multiple sites, which is antithetical to the privacy objectives. Federated learning is a commonly proposed solution to this problem. It circumvents the need for data sharing by sharing parameters during the training process. However, we demonstrate that allowing access to parameters may leak private information even if data is never directly shared. In particular, we show that it is possible to infer if a sample was used to train the model given only access to the model prediction (black-box) or access to the model itself (white-box) and some leaked samples from the training data distribution. Such attacks are commonly referred to as Membership Inference attacks. We show realistic Membership Inference attacks on deep learning models trained for 3D neuroimaging tasks in a centralized as well as decentralized setup. We demonstrate feasible attacks on brain age prediction models (deep learning models that predict a person's age from their brain MRI scan). We correctly identified whether an MRI scan was used in model training with a 60% to over 80% success rate depending on model complexity and security assumptions.
Scaling Neuroscience Research using Federated Learning
Feb 16, 2021
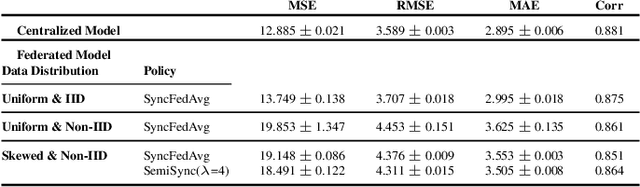

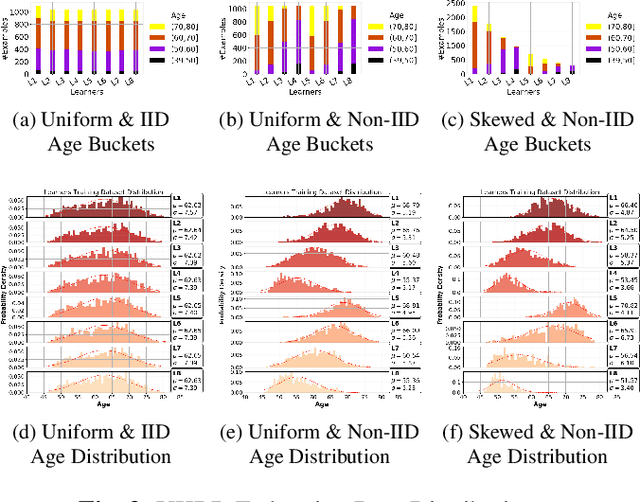
The amount of biomedical data continues to grow rapidly. However, the ability to analyze these data is limited due to privacy and regulatory concerns. Machine learning approaches that require data to be copied to a single location are hampered by the challenges of data sharing. Federated Learning is a promising approach to learn a joint model over data silos. This architecture does not share any subject data across sites, only aggregated parameters, often in encrypted environments, thus satisfying privacy and regulatory requirements. Here, we describe our Federated Learning architecture and training policies. We demonstrate our approach on a brain age prediction model on structural MRI scans distributed across multiple sites with diverse amounts of data and subject (age) distributions. In these heterogeneous environments, our Semi-Synchronous protocol provides faster convergence.