 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDirk Sudholt
A Tight $O(4^k/p_c)$ Runtime Bound for a ($μ$+1) GA on Jump$_k$ for Realistic Crossover Probabilities
Apr 10, 2024
The Jump$_k$ benchmark was the first problem for which crossover was proven to give a speedup over mutation-only evolutionary algorithms. Jansen and Wegener (2002) proved an upper bound of $O({\rm poly}(n) + 4^k/p_c)$ for the ($\mu$+1)~Genetic Algorithm ($(\mu+1)$ GA), but only for unrealistically small crossover probabilities $p_c$. To this date, it remains an open problem to prove similar upper bounds for realistic~$p_c$; the best known runtime bound for $p_c = \Omega(1)$ is $O((n/\chi)^{k-1})$, $\chi$ a positive constant. Using recently developed techniques, we analyse the evolution of the population diversity, measured as sum of pairwise Hamming distances, for a variant of the \muga on Jump$_k$. We show that population diversity converges to an equilibrium of near-perfect diversity. This yields an improved and tight time bound of $O(\mu n \log(k) + 4^k/p_c)$ for a range of~$k$ under the mild assumptions $p_c = O(1/k)$ and $\mu \in \Omega(kn)$. For all constant~$k$ the restriction is satisfied for some $p_c = \Omega(1)$. Our work partially solves a problem that has been open for more than 20 years.
Analysing the Robustness of NSGA-II under Noise
Jun 07, 2023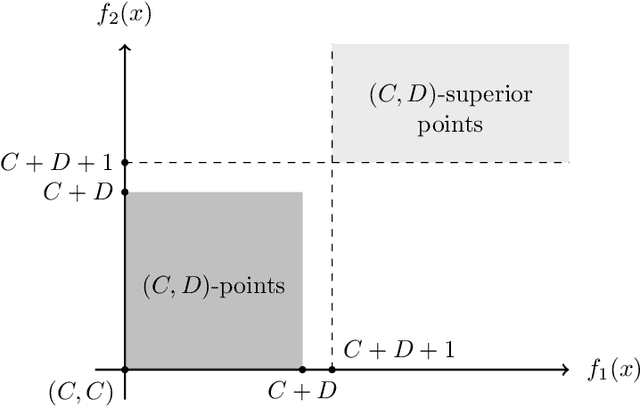
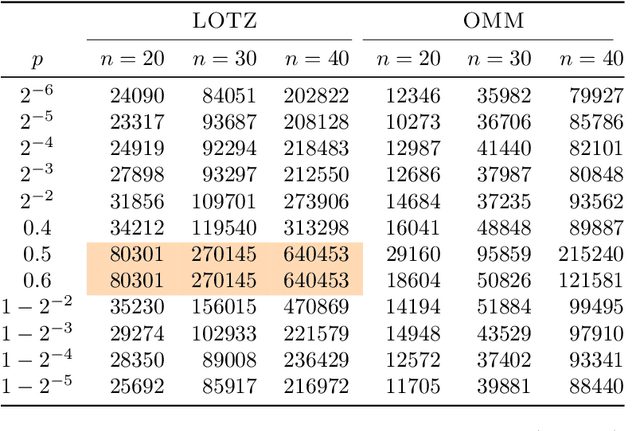

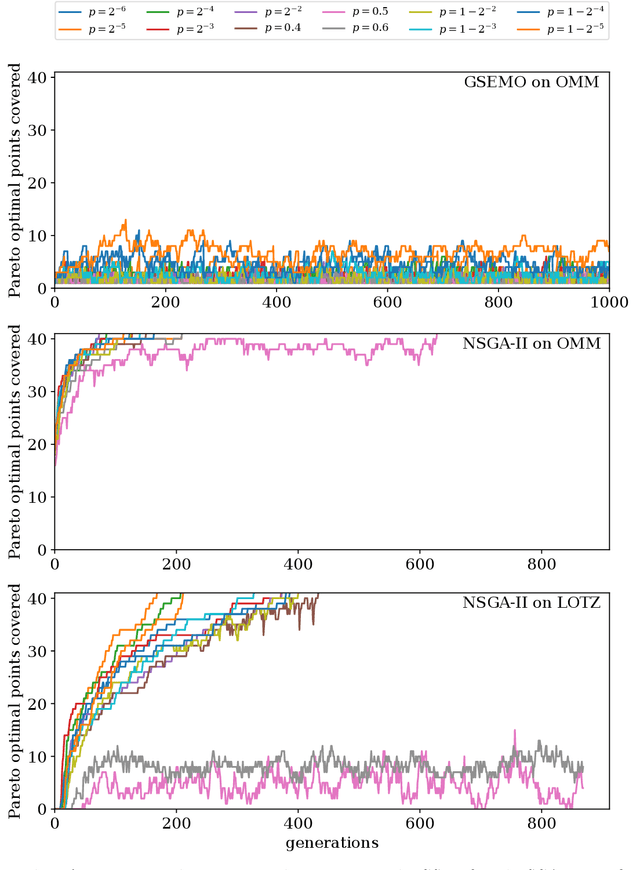
Runtime analysis has produced many results on the efficiency of simple evolutionary algorithms like the (1+1) EA, and its analogue called GSEMO in evolutionary multiobjective optimisation (EMO). Recently, the first runtime analyses of the famous and highly cited EMO algorithm NSGA-II have emerged, demonstrating that practical algorithms with thousands of applications can be rigorously analysed. However, these results only show that NSGA-II has the same performance guarantees as GSEMO and it is unclear how and when NSGA-II can outperform GSEMO. We study this question in noisy optimisation and consider a noise model that adds large amounts of posterior noise to all objectives with some constant probability $p$ per evaluation. We show that GSEMO fails badly on every noisy fitness function as it tends to remove large parts of the population indiscriminately. In contrast, NSGA-II is able to handle the noise efficiently on \textsc{LeadingOnesTrailingZeroes} when $p<1/2$, as the algorithm is able to preserve useful search points even in the presence of noise. We identify a phase transition at $p=1/2$ where the expected time to cover the Pareto front changes from polynomial to exponential. To our knowledge, this is the first proof that NSGA-II can outperform GSEMO and the first runtime analysis of NSGA-II in noisy optimisation.
Runtime Analysis of Quality Diversity Algorithms
May 30, 2023Quality diversity~(QD) is a branch of evolutionary computation that gained increasing interest in recent years. The Map-Elites QD approach defines a feature space, i.e., a partition of the search space, and stores the best solution for each cell of this space. We study a simple QD algorithm in the context of pseudo-Boolean optimisation on the ``number of ones'' feature space, where the $i$th cell stores the best solution amongst those with a number of ones in $[(i-1)k, ik-1]$. Here $k$ is a granularity parameter $1 \leq k \leq n+1$. We give a tight bound on the expected time until all cells are covered for arbitrary fitness functions and for all $k$ and analyse the expected optimisation time of QD on \textsc{OneMax} and other problems whose structure aligns favourably with the feature space. On combinatorial problems we show that QD finds a ${(1-1/e)}$-approximation when maximising any monotone sub-modular function with a single uniform cardinality constraint efficiently. Defining the feature space as the number of connected components of a connected graph, we show that QD finds a minimum spanning tree in expected polynomial time.
Comma Selection Outperforms Plus Selection on OneMax with Randomly Planted Optima
Apr 19, 2023It is an ongoing debate whether and how comma selection in evolutionary algorithms helps to escape local optima. We propose a new benchmark function to investigate the benefits of comma selection: OneMax with randomly planted local optima, generated by frozen noise. We show that comma selection (the $(1,\lambda)$ EA) is faster than plus selection (the $(1+\lambda)$ EA) on this benchmark, in a fixed-target scenario, and for offspring population sizes $\lambda$ for which both algorithms behave differently. For certain parameters, the $(1,\lambda)$ EA finds the target in $\Theta(n \ln n)$ evaluations, with high probability (w.h.p.), while the $(1+\lambda)$ EA) w.h.p. requires almost $\Theta((n\ln n)^2)$ evaluations. We further show that the advantage of comma selection is not arbitrarily large: w.h.p. comma selection outperforms plus selection at most by a factor of $O(n \ln n)$ for most reasonable parameter choices. We develop novel methods for analysing frozen noise and give powerful and general fixed-target results with tail bounds that are of independent interest.
Analysing Equilibrium States for Population Diversity
Apr 19, 2023Population diversity is crucial in evolutionary algorithms as it helps with global exploration and facilitates the use of crossover. Despite many runtime analyses showing advantages of population diversity, we have no clear picture of how diversity evolves over time. We study how population diversity of $(\mu+1)$ algorithms, measured by the sum of pairwise Hamming distances, evolves in a fitness-neutral environment. We give an exact formula for the drift of population diversity and show that it is driven towards an equilibrium state. Moreover, we bound the expected time for getting close to the equilibrium state. We find that these dynamics, including the location of the equilibrium, are unaffected by surprisingly many algorithmic choices. All unbiased mutation operators with the same expected number of bit flips have the same effect on the expected diversity. Many crossover operators have no effect at all, including all binary unbiased, respectful operators. We review crossover operators from the literature and identify crossovers that are neutral towards the evolution of diversity and crossovers that are not.
A Proof that Using Crossover Can Guarantee Exponential Speed-Ups in Evolutionary Multi-Objective Optimisation
Jan 31, 2023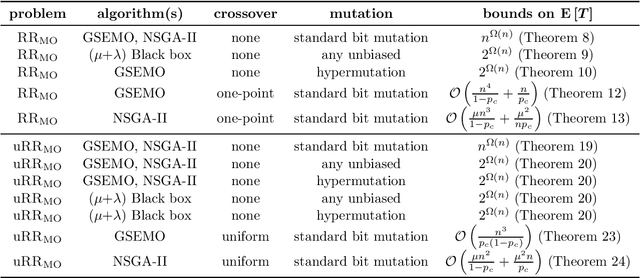
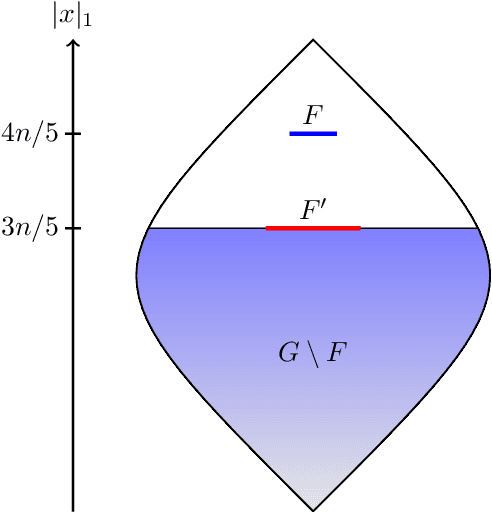
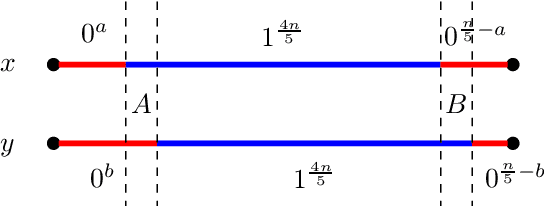
Evolutionary algorithms are popular algorithms for multiobjective optimisation (also called Pareto optimisation) as they use a population to store trade-offs between different objectives. Despite their popularity, the theoretical foundation of multiobjective evolutionary optimisation (EMO) is still in its early development. Fundamental questions such as the benefits of the crossover operator are still not fully understood. We provide a theoretical analysis of well-known EMO algorithms GSEMO and NSGA-II to showcase the possible advantages of crossover. We propose a class of problems on which these EMO algorithms using crossover find the Pareto set in expected polynomial time. In sharp contrast, they and many other EMO algorithms without crossover require exponential time to even find a single Pareto-optimal point. This is the first example of an exponential performance gap through the use of crossover for the widely used NSGA-II algorithm.
Hard Problems are Easier for Success-based Parameter Control
Apr 12, 2022Recent works showed that simple success-based rules for self-adjusting parameters in evolutionary algorithms (EAs) can match or outperform the best fixed parameters on discrete problems. Non-elitism in a (1,$\lambda$) EA combined with a self-adjusting offspring population size $\lambda$ outperforms common EAs on the multimodal Cliff problem. However, it was shown that this only holds if the success rate $s$ that governs self-adjustment is small enough. Otherwise, even on OneMax, the self-adjusting (1,$\lambda$) EA stagnates on an easy slope, where frequent successes drive down the offspring population size. We show that self-adjustment works as intended in the absence of easy slopes. We define everywhere hard functions, for which successes are never easy to find and show that the self-adjusting (1,$\lambda$) EA is robust with respect to the choice of success rates $s$. We give a general fitness-level upper bound on the number of evaluations and show that the expected number of generations is at most $O(d + \log(1/p_{\min}))$ where $d$ is the number of non-optimal fitness values and $p_{\min}$ is the smallest probability of finding an improvement from a non-optimal search point. We discuss implications for the everywhere hard function LeadingOnes and a new class OneMaxBlocks of everywhere hard functions with tunable difficulty.
The Compact Genetic Algorithm Struggles on Cliff Functions
Apr 11, 2022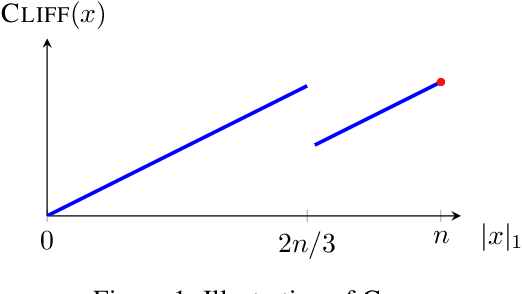
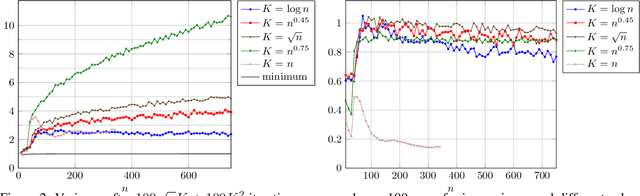
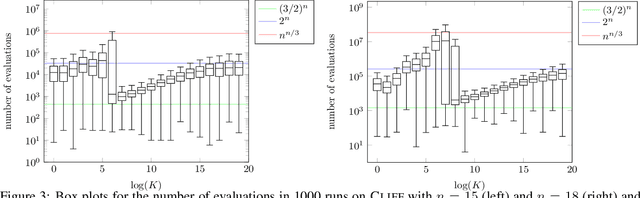
The compact genetic algorithm (cGA) is an non-elitist estimation of distribution algorithm which has shown to be able to deal with difficult multimodal fitness landscapes that are hard to solve by elitist algorithms. In this paper, we investigate the cGA on the CLIFF function for which it has been shown recently that non-elitist evolutionary algorithms and artificial immune systems optimize it in expected polynomial time. We point out that the cGA faces major difficulties when solving the CLIFF function and investigate its dynamics both experimentally and theoretically around the cliff. Our experimental results indicate that the cGA requires exponential time for all values of the update strength $K$. We show theoretically that, under sensible assumptions, there is a negative drift when sampling around the location of the cliff. Experiments further suggest that there is a phase transition for $K$ where the expected optimization time drops from $n^{\Theta(n)}$ to $2^{\Theta(n)}$.
Runtime Analysis of Restricted Tournament Selection for Bimodal Optimisation
Jan 17, 2022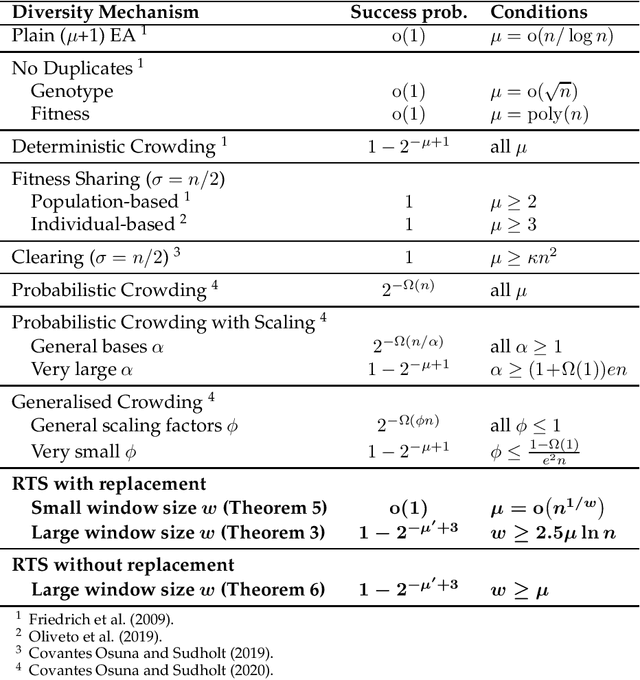
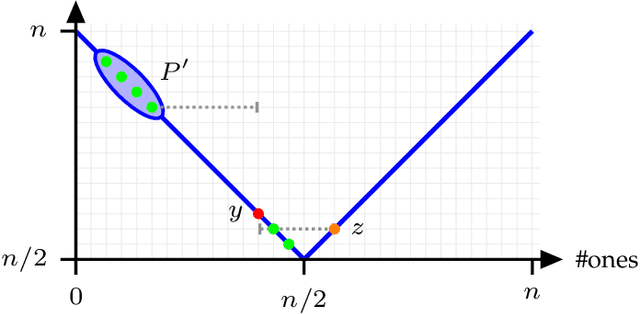
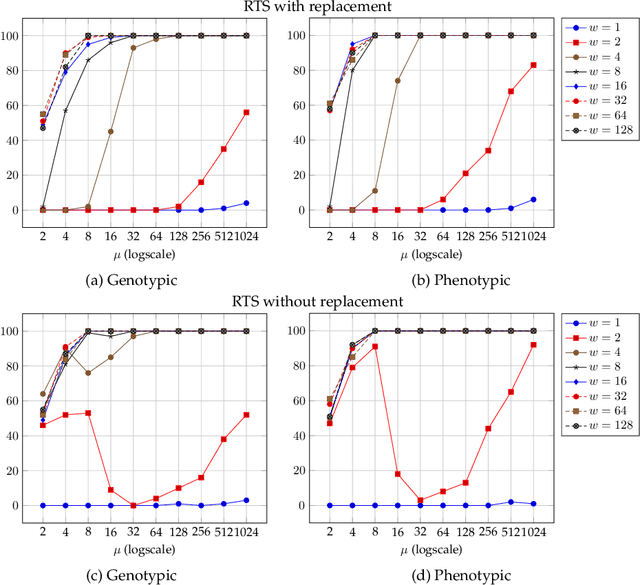
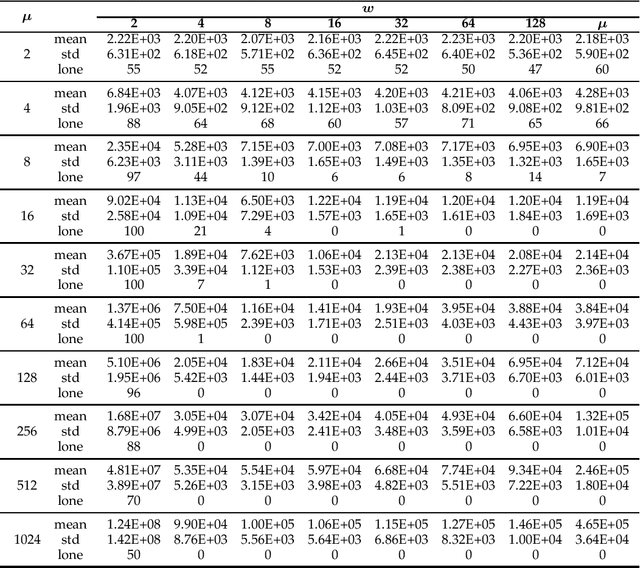
Niching methods have been developed to maintain the population diversity, to investigate many peaks in parallel and to reduce the effect of genetic drift. We present the first rigorous runtime analyses of restricted tournament selection (RTS), embedded in a ($\mu$+1) EA, and analyse its effectiveness at finding both optima of the bimodal function ${\rm T{\small WO}M{\small AX}}$. In RTS, an offspring competes against the closest individual, with respect to some distance measure, amongst $w$ (window size) population members (chosen uniformly at random with replacement), to encourage competition within the same niche. We prove that RTS finds both optima on ${\rm T{\small WO}M{\small AX}}$ efficiently if the window size $w$ is large enough. However, if $w$ is too small, RTS fails to find both optima even in exponential time, with high probability. We further consider a variant of RTS selecting individuals for the tournament \emph{without} replacement. It yields a more diverse tournament and is more effective at preventing one niche from taking over the other. However, this comes at the expense of a slower progress towards optima when a niche collapses to a single individual. Our theoretical results are accompanied by experimental studies that shed light on parameters not covered by the theoretical results and support a conjectured lower runtime bound.
Time Complexity Analysis of Randomized Search Heuristics for the Dynamic Graph Coloring Problem
May 26, 2021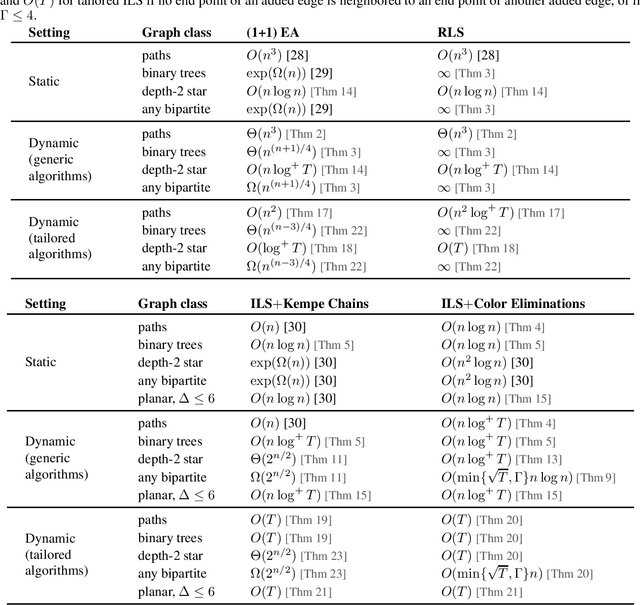

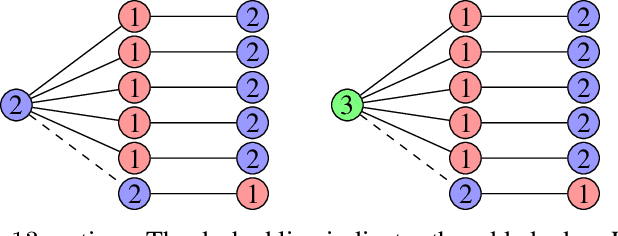

We contribute to the theoretical understanding of randomized search heuristics for dynamic problems. We consider the classical vertex coloring problem on graphs and investigate the dynamic setting where edges are added to the current graph. We then analyze the expected time for randomized search heuristics to recompute high quality solutions. The (1+1)~Evolutionary Algorithm and RLS operate in a setting where the number of colors is bounded and we are minimizing the number of conflicts. Iterated local search algorithms use an unbounded color palette and aim to use the smallest colors and, consequently, the smallest number of colors. We identify classes of bipartite graphs where reoptimization is as hard as or even harder than optimization from scratch, i.e., starting with a random initialization. Even adding a single edge can lead to hard symmetry problems. However, graph classes that are hard for one algorithm turn out to be easy for others. In most cases our bounds show that reoptimization is faster than optimizing from scratch. We further show that tailoring mutation operators to parts of the graph where changes have occurred can significantly reduce the expected reoptimization time. In most settings the expected reoptimization time for such tailored algorithms is linear in the number of added edges. However, tailored algorithms cannot prevent exponential times in settings where the original algorithm is inefficient.