 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDongdong Wang
Enhancing Traffic Safety with Parallel Dense Video Captioning for End-to-End Event Analysis
Apr 12, 2024
This paper introduces our solution for Track 2 in AI City Challenge 2024. The task aims to solve traffic safety description and analysis with the dataset of Woven Traffic Safety (WTS), a real-world Pedestrian-Centric Traffic Video Dataset for Fine-grained Spatial-Temporal Understanding. Our solution mainly focuses on the following points: 1) To solve dense video captioning, we leverage the framework of dense video captioning with parallel decoding (PDVC) to model visual-language sequences and generate dense caption by chapters for video. 2) Our work leverages CLIP to extract visual features to more efficiently perform cross-modality training between visual and textual representations. 3) We conduct domain-specific model adaptation to mitigate domain shift problem that poses recognition challenge in video understanding. 4) Moreover, we leverage BDD-5K captioned videos to conduct knowledge transfer for better understanding WTS videos and more accurate captioning. Our solution has yielded on the test set, achieving 6th place in the competition. The open source code will be available at https://github.com/UCF-SST-Lab/AICity2024CVPRW
The Causal Impact of Credit Lines on Spending Distributions
Dec 16, 2023Consumer credit services offered by e-commerce platforms provide customers with convenient loan access during shopping and have the potential to stimulate sales. To understand the causal impact of credit lines on spending, previous studies have employed causal estimators, based on direct regression (DR), inverse propensity weighting (IPW), and double machine learning (DML) to estimate the treatment effect. However, these estimators do not consider the notion that an individual's spending can be understood and represented as a distribution, which captures the range and pattern of amounts spent across different orders. By disregarding the outcome as a distribution, valuable insights embedded within the outcome distribution might be overlooked. This paper develops a distribution-valued estimator framework that extends existing real-valued DR-, IPW-, and DML-based estimators to distribution-valued estimators within Rubin's causal framework. We establish their consistency and apply them to a real dataset from a large e-commerce platform. Our findings reveal that credit lines positively influence spending across all quantiles; however, as credit lines increase, consumers allocate more to luxuries (higher quantiles) than necessities (lower quantiles).
DeLELSTM: Decomposition-based Linear Explainable LSTM to Capture Instantaneous and Long-term Effects in Time Series
Aug 26, 2023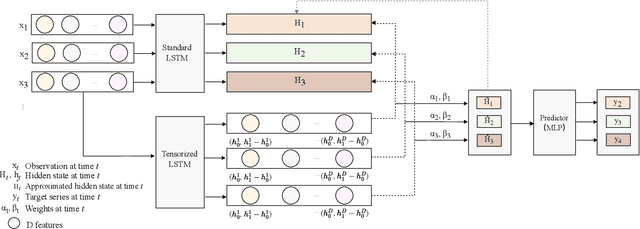

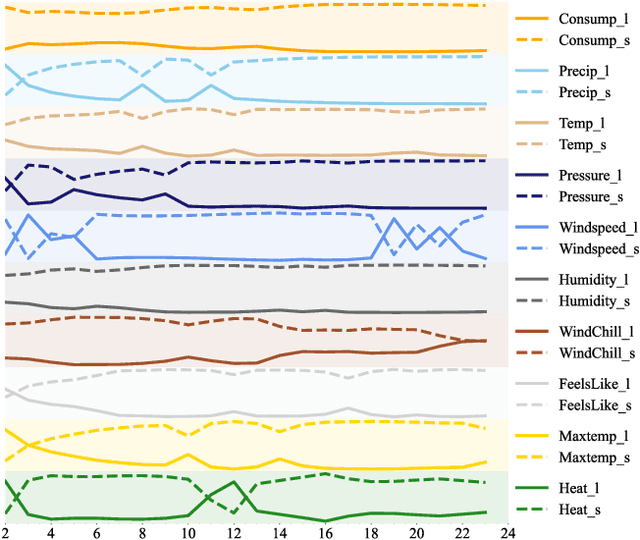

Time series forecasting is prevalent in various real-world applications. Despite the promising results of deep learning models in time series forecasting, especially the Recurrent Neural Networks (RNNs), the explanations of time series models, which are critical in high-stakes applications, have received little attention. In this paper, we propose a Decomposition-based Linear Explainable LSTM (DeLELSTM) to improve the interpretability of LSTM. Conventionally, the interpretability of RNNs only concentrates on the variable importance and time importance. We additionally distinguish between the instantaneous influence of new coming data and the long-term effects of historical data. Specifically, DeLELSTM consists of two components, i.e., standard LSTM and tensorized LSTM. The tensorized LSTM assigns each variable with a unique hidden state making up a matrix $\mathbf{h}_t$, and the standard LSTM models all the variables with a shared hidden state $\mathbf{H}_t$. By decomposing the $\mathbf{H}_t$ into the linear combination of past information $\mathbf{h}_{t-1}$ and the fresh information $\mathbf{h}_{t}-\mathbf{h}_{t-1}$, we can get the instantaneous influence and the long-term effect of each variable. In addition, the advantage of linear regression also makes the explanation transparent and clear. We demonstrate the effectiveness and interpretability of DeLELSTM on three empirical datasets. Extensive experiments show that the proposed method achieves competitive performance against the baseline methods and provides a reliable explanation relative to domain knowledge.
TrafficSafetyGPT: Tuning a Pre-trained Large Language Model to a Domain-Specific Expert in Transportation Safety
Jul 28, 2023Large Language Models (LLMs) have shown remarkable effectiveness in various general-domain natural language processing (NLP) tasks. However, their performance in transportation safety domain tasks has been suboptimal, primarily attributed to the requirement for specialized transportation safety expertise in generating accurate responses [1]. To address this challenge, we introduce TrafficSafetyGPT, a novel LLAMA-based model, which has undergone supervised fine-tuning using TrafficSafety-2K dataset which has human labels from government produced guiding books and ChatGPT-generated instruction-output pairs. Our proposed TrafficSafetyGPT model and TrafficSafety-2K train dataset are accessible at https://github.com/ozheng1993/TrafficSafetyGPT.
Deep into The Domain Shift: Transfer Learning through Dependence Regularization
May 31, 2023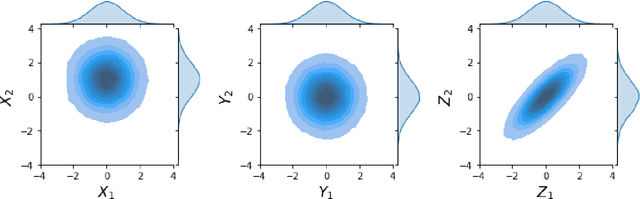
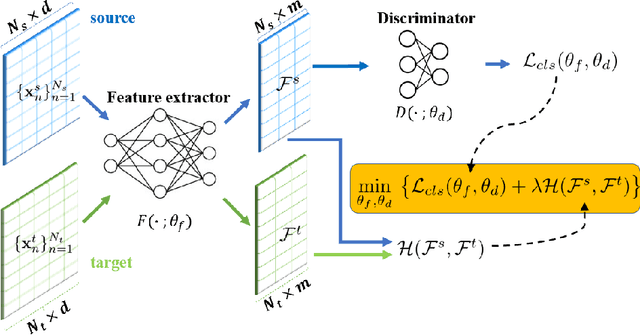
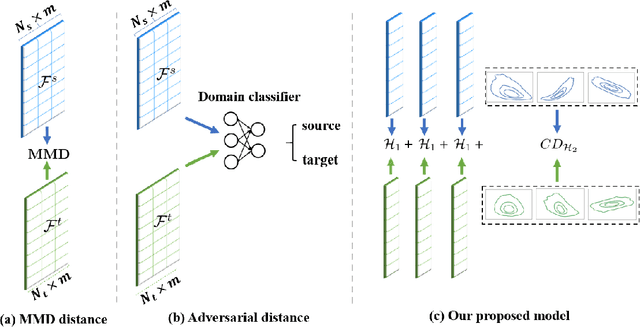

Classical Domain Adaptation methods acquire transferability by regularizing the overall distributional discrepancies between features in the source domain (labeled) and features in the target domain (unlabeled). They often do not differentiate whether the domain differences come from the marginals or the dependence structures. In many business and financial applications, the labeling function usually has different sensitivities to the changes in the marginals versus changes in the dependence structures. Measuring the overall distributional differences will not be discriminative enough in acquiring transferability. Without the needed structural resolution, the learned transfer is less optimal. This paper proposes a new domain adaptation approach in which one can measure the differences in the internal dependence structure separately from those in the marginals. By optimizing the relative weights among them, the new regularization strategy greatly relaxes the rigidness of the existing approaches. It allows a learning machine to pay special attention to places where the differences matter the most. Experiments on three real-world datasets show that the improvements are quite notable and robust compared to various benchmark domain adaptation models.
AVOID: Autonomous Vehicle Operation Incident Dataset Across the Globe
Mar 22, 2023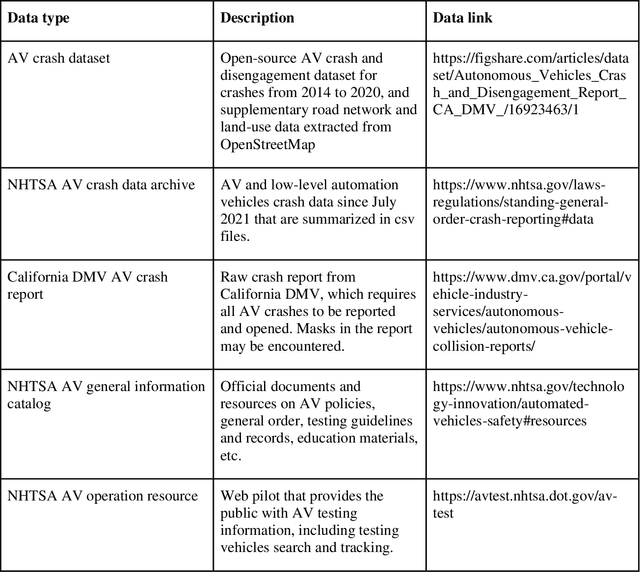


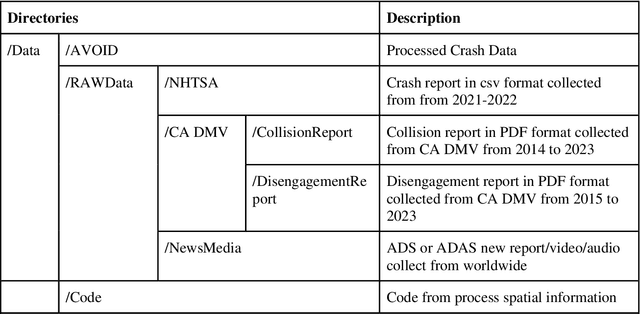
Crash data of autonomous vehicles (AV) or vehicles equipped with advanced driver assistance systems (ADAS) are the key information to understand the crash nature and to enhance the automation systems. However, most of the existing crash data sources are either limited by the sample size or suffer from missing or unverified data. To contribute to the AV safety research community, we introduce AVOID: an open AV crash dataset. Three types of vehicles are considered: Advanced Driving System (ADS) vehicles, Advanced Driver Assistance Systems (ADAS) vehicles, and low-speed autonomous shuttles. The crash data are collected from the National Highway Traffic Safety Administration (NHTSA), California Department of Motor Vehicles (CA DMV) and incident news worldwide, and the data are manually verified and summarized in ready-to-use format. In addition, land use, weather, and geometry information are also provided. The dataset is expected to accelerate the research on AV crash analysis and potential risk identification by providing the research community with data of rich samples, diverse data sources, clear data structure, and high data quality.
ChatGPT Is on the Horizon: Could a Large Language Model Be All We Need for Intelligent Transportation?
Mar 21, 2023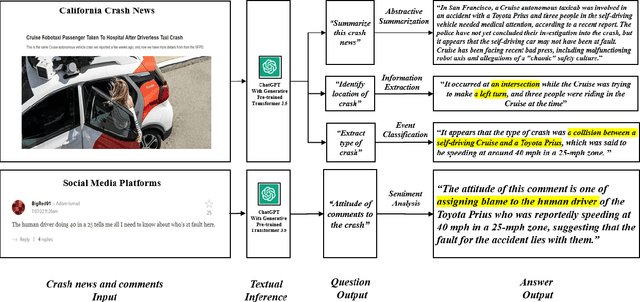

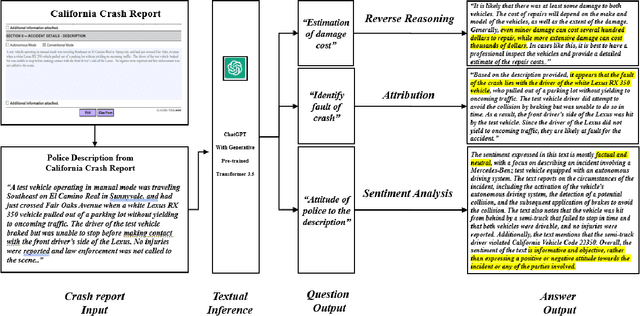
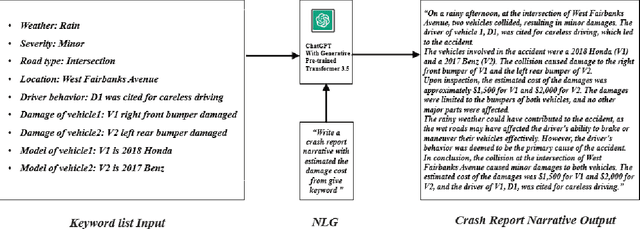
ChatGPT, developed by OpenAI, is one of the milestone large language models (LLMs) with 6 billion parameters. ChatGPT has demonstrated the impressive language understanding capability of LLM, particularly in generating conversational response. As LLMs start to gain more attention in various research or engineering domains, it is time to envision how LLM may revolutionize the way we approach intelligent transportation systems. This paper explores the future applications of LLM in addressing key transportation problems. By leveraging LLM with cross-modal encoder, an intelligent system can also process traffic data from different modalities and execute transportation operations through an LLM. We present and validate these potential transportation applications equipped by LLM. To further demonstrate this potential, we also provide a concrete smartphone-based crash report auto-generation and analysis framework as a use case. Despite the potential benefits, challenges related to data privacy, data quality, and model bias must be considered. Overall, the use of LLM in intelligent transport systems holds promise for more efficient, intelligent, and sustainable transportation systems that further improve daily life around the world.
On Calibrating Semantic Segmentation Models: Analysis and An Algorithm
Dec 22, 2022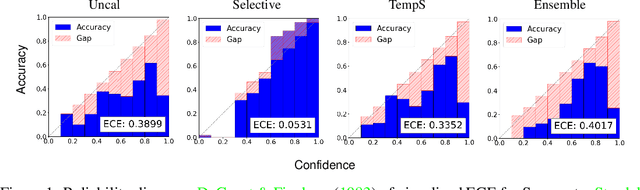
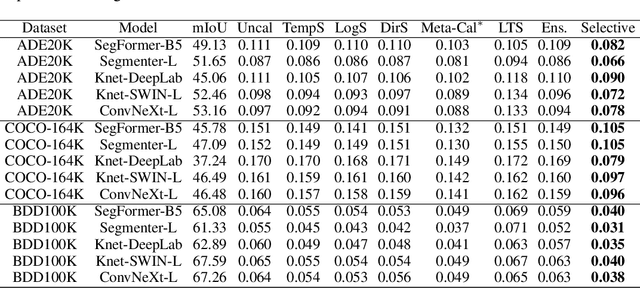
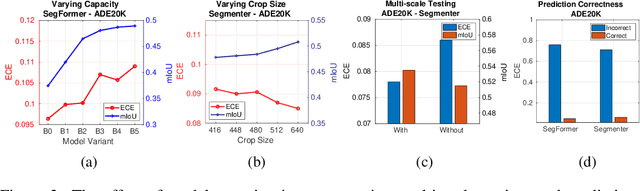
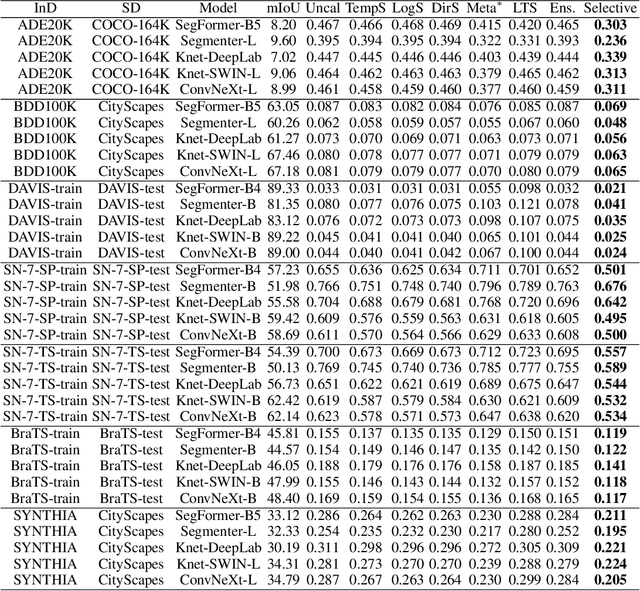
We study the problem of semantic segmentation calibration. For image classification, lots of existing solutions are proposed to alleviate model miscalibration of confidence. However, to date, confidence calibration research on semantic segmentation is still limited. We provide a systematic study on the calibration of semantic segmentation models and propose a simple yet effective approach. First, we find that model capacity, crop size, multi-scale testing, and prediction correctness have impact on calibration. Among them, prediction correctness, especially misprediction, is more important to miscalibration due to over-confidence. Next, we propose a simple, unifying, and effective approach, namely selective scaling, by separating correct/incorrect prediction for scaling and more focusing on misprediction logit smoothing. Then, we study popular existing calibration methods and compare them with selective scaling on semantic segmentation calibration. We conduct extensive experiments with a variety of benchmarks on both in-domain and domain-shift calibration, and show that selective scaling consistently outperforms other methods.
Moderately-Balanced Representation Learning for Treatment Effects with Orthogonality Information
Sep 05, 2022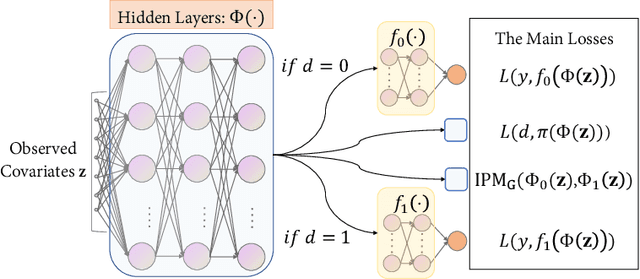
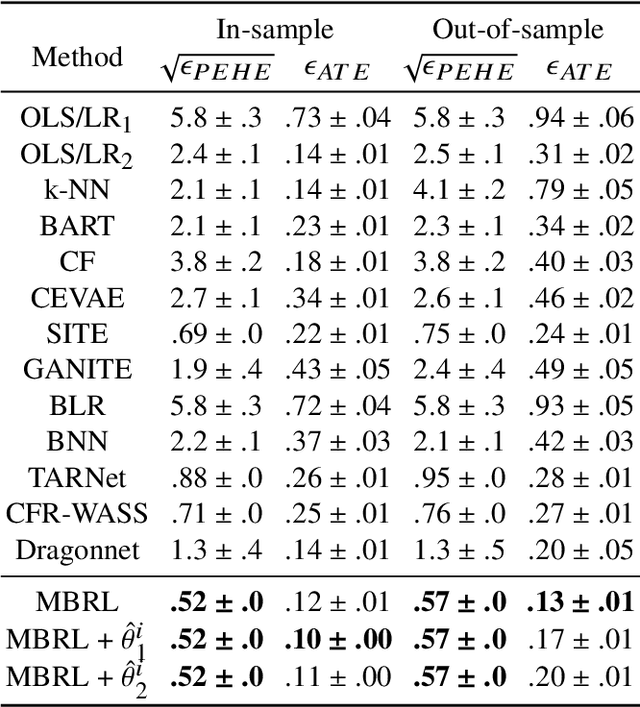

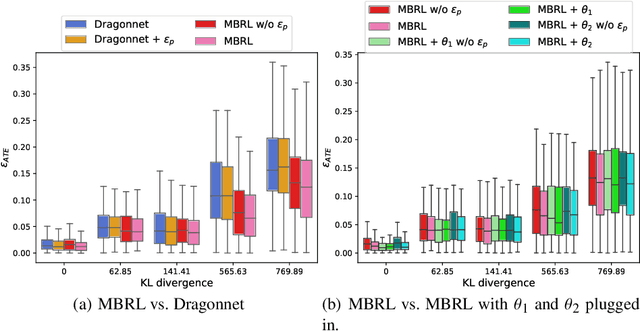
Estimating the average treatment effect (ATE) from observational data is challenging due to selection bias. Existing works mainly tackle this challenge in two ways. Some researchers propose constructing a score function that satisfies the orthogonal condition, which guarantees that the established ATE estimator is "orthogonal" to be more robust. The others explore representation learning models to achieve a balanced representation between the treated and the controlled groups. However, existing studies fail to 1) discriminate treated units from controlled ones in the representation space to avoid the over-balanced issue; 2) fully utilize the "orthogonality information". In this paper, we propose a moderately-balanced representation learning (MBRL) framework based on recent covariates balanced representation learning methods and orthogonal machine learning theory. This framework protects the representation from being over-balanced via multi-task learning. Simultaneously, MBRL incorporates the noise orthogonality information in the training and validation stages to achieve a better ATE estimation. The comprehensive experiments on benchmark and simulated datasets show the superiority and robustness of our method on treatment effect estimations compared with existing state-of-the-art methods.
Robust Causal Learning for the Estimation of Average Treatment Effects
Sep 05, 2022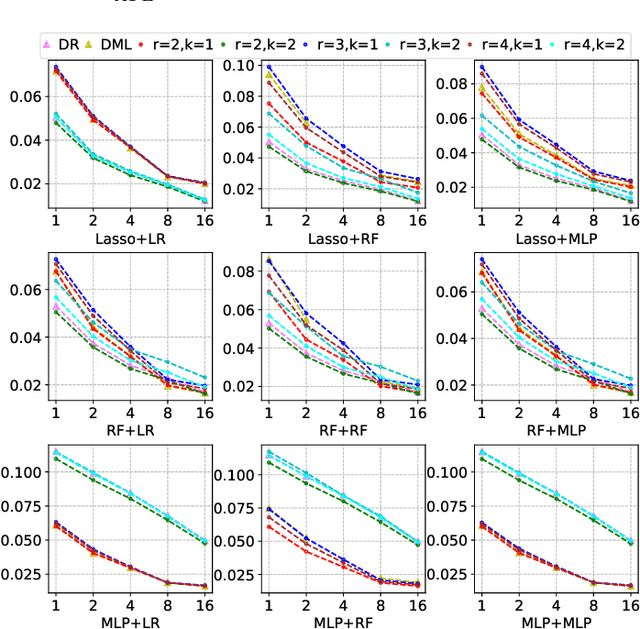
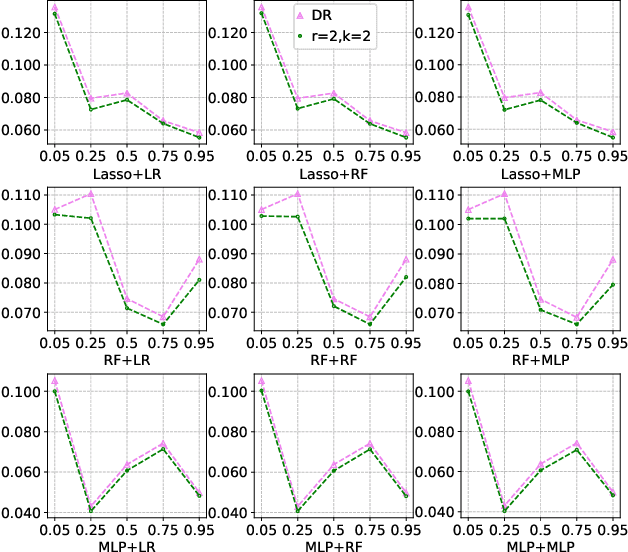
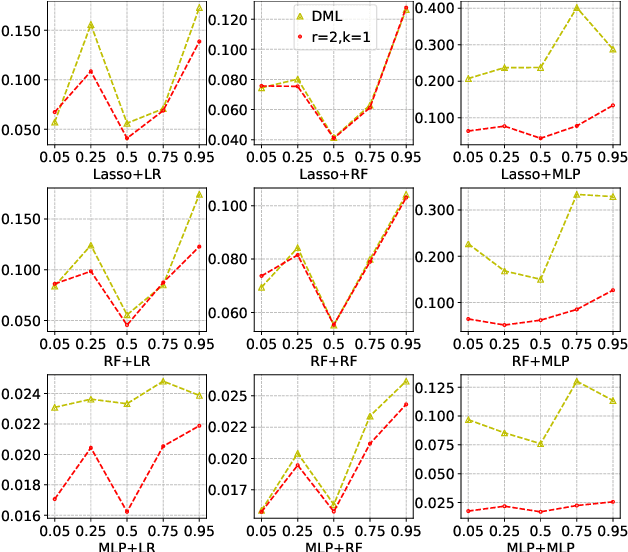
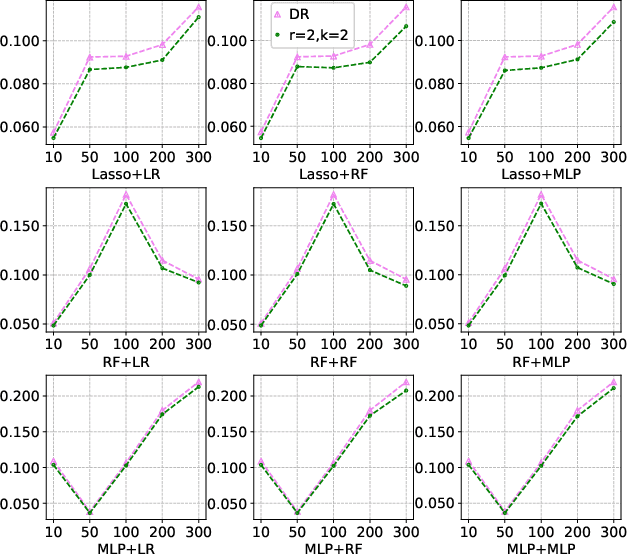
Many practical decision-making problems in economics and healthcare seek to estimate the average treatment effect (ATE) from observational data. The Double/Debiased Machine Learning (DML) is one of the prevalent methods to estimate ATE in the observational study. However, the DML estimators can suffer an error-compounding issue and even give an extreme estimate when the propensity scores are misspecified or very close to 0 or 1. Previous studies have overcome this issue through some empirical tricks such as propensity score trimming, yet none of the existing literature solves this problem from a theoretical standpoint. In this paper, we propose a Robust Causal Learning (RCL) method to offset the deficiencies of the DML estimators. Theoretically, the RCL estimators i) are as consistent and doubly robust as the DML estimators, and ii) can get rid of the error-compounding issue. Empirically, the comprehensive experiments show that i) the RCL estimators give more stable estimations of the causal parameters than the DML estimators, and ii) the RCL estimators outperform the traditional estimators and their variants when applying different machine learning models on both simulation and benchmark datasets.