 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDongjun Kim
Training Unbiased Diffusion Models From Biased Dataset
Mar 02, 2024
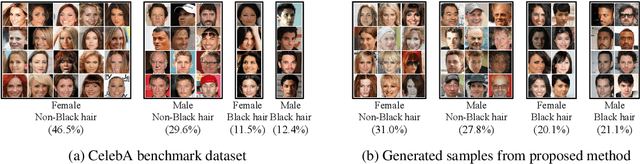

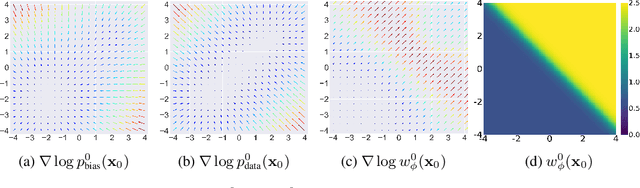
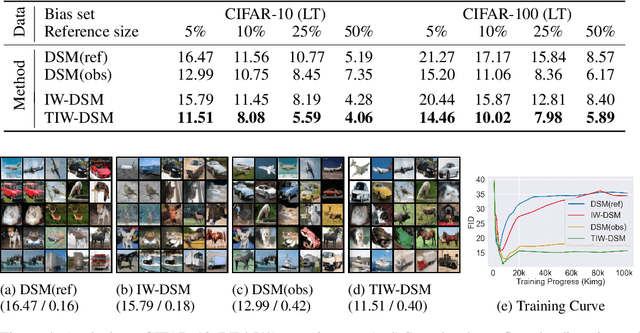
With significant advancements in diffusion models, addressing the potential risks of dataset bias becomes increasingly important. Since generated outputs directly suffer from dataset bias, mitigating latent bias becomes a key factor in improving sample quality and proportion. This paper proposes time-dependent importance reweighting to mitigate the bias for the diffusion models. We demonstrate that the time-dependent density ratio becomes more precise than previous approaches, thereby minimizing error propagation in generative learning. While directly applying it to score-matching is intractable, we discover that using the time-dependent density ratio both for reweighting and score correction can lead to a tractable form of the objective function to regenerate the unbiased data density. Furthermore, we theoretically establish a connection with traditional score-matching, and we demonstrate its convergence to an unbiased distribution. The experimental evidence supports the usefulness of the proposed method, which outperforms baselines including time-independent importance reweighting on CIFAR-10, CIFAR-100, FFHQ, and CelebA with various bias settings. Our code is available at https://github.com/alsdudrla10/TIW-DSM.
Manifold Preserving Guided Diffusion
Nov 28, 2023Despite the recent advancements, conditional image generation still faces challenges of cost, generalizability, and the need for task-specific training. In this paper, we propose Manifold Preserving Guided Diffusion (MPGD), a training-free conditional generation framework that leverages pretrained diffusion models and off-the-shelf neural networks with minimal additional inference cost for a broad range of tasks. Specifically, we leverage the manifold hypothesis to refine the guided diffusion steps and introduce a shortcut algorithm in the process. We then propose two methods for on-manifold training-free guidance using pre-trained autoencoders and demonstrate that our shortcut inherently preserves the manifolds when applied to latent diffusion models. Our experiments show that MPGD is efficient and effective for solving a variety of conditional generation applications in low-compute settings, and can consistently offer up to 3.8x speed-ups with the same number of diffusion steps while maintaining high sample quality compared to the baselines.
Consistency Trajectory Models: Learning Probability Flow ODE Trajectory of Diffusion
Oct 01, 2023
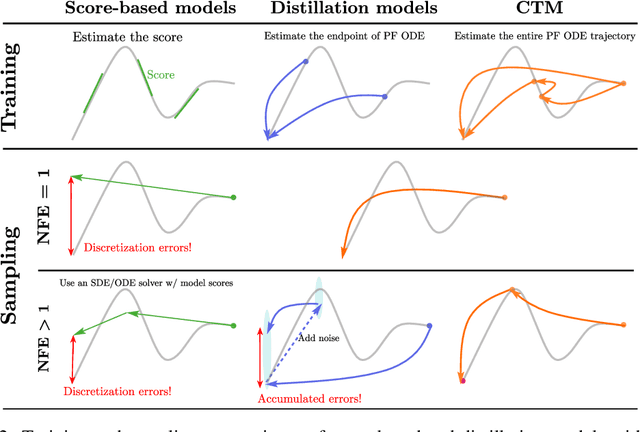

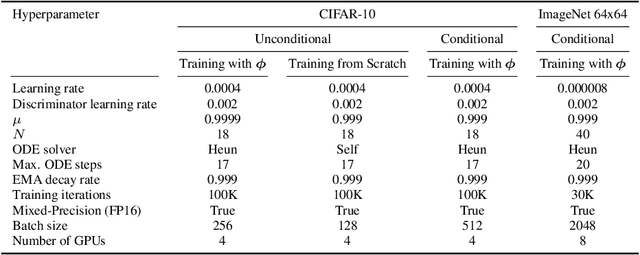
Consistency Models (CM) (Song et al., 2023) accelerate score-based diffusion model sampling at the cost of sample quality but lack a natural way to trade-off quality for speed. To address this limitation, we propose Consistency Trajectory Model (CTM), a generalization encompassing CM and score-based models as special cases. CTM trains a single neural network that can -- in a single forward pass -- output scores (i.e., gradients of log-density) and enables unrestricted traversal between any initial and final time along the Probability Flow Ordinary Differential Equation (ODE) in a diffusion process. CTM enables the efficient combination of adversarial training and denoising score matching loss to enhance performance and achieves new state-of-the-art FIDs for single-step diffusion model sampling on CIFAR-10 (FID 1.73) and ImageNet at 64X64 resolution (FID 2.06). CTM also enables a new family of sampling schemes, both deterministic and stochastic, involving long jumps along the ODE solution trajectories. It consistently improves sample quality as computational budgets increase, avoiding the degradation seen in CM. Furthermore, CTM's access to the score accommodates all diffusion model inference techniques, including exact likelihood computation.
Refining Generative Process with Discriminator Guidance in Score-based Diffusion Models
Nov 28, 2022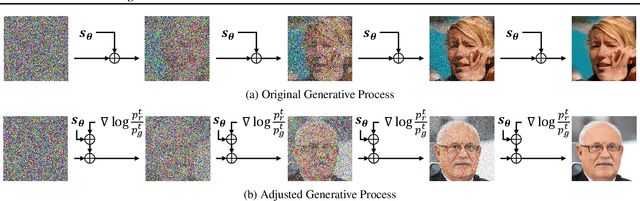
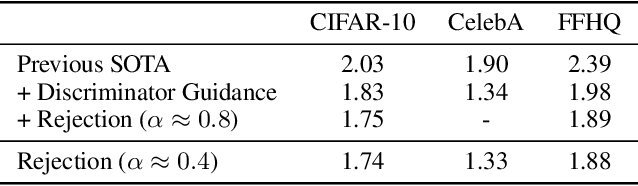

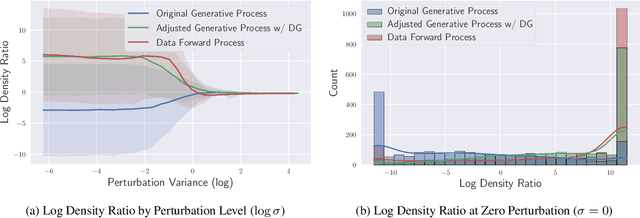
While the success of diffusion models has been witnessed in various domains, only a few works have investigated the variation of the generative process. In this paper, we introduce a new generative process that is closer to the reverse process than the original generative process, given the identical score checkpoint. Specifically, we adjust the generative process with the auxiliary discriminator between the real data and the generated data. Consequently, the adjusted generative process with the discriminator generates more realistic samples than the original process. In experiments, we achieve new SOTA FIDs of 1.74 on CIFAR-10, 1.33 on CelebA, and 1.88 on FFHQ in the unconditional generation.
Maximum Likelihood Training of Implicit Nonlinear Diffusion Models
May 27, 2022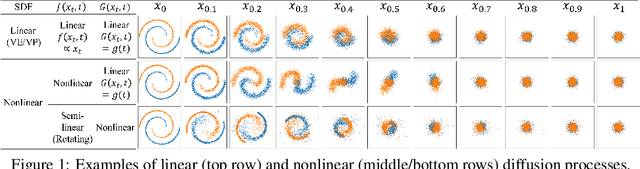

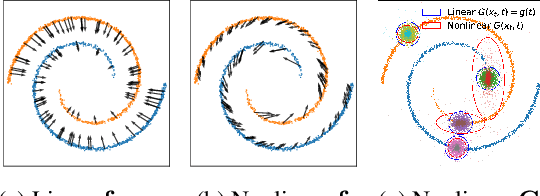
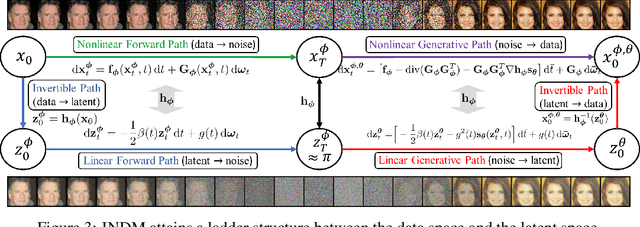
Whereas diverse variations of diffusion models exist, expanding the linear diffusion into a nonlinear diffusion process is investigated only by a few works. The nonlinearity effect has been hardly understood, but intuitively, there would be more promising diffusion patterns to optimally train the generative distribution towards the data distribution. This paper introduces such a data-adaptive and nonlinear diffusion process for score-based diffusion models. The proposed Implicit Nonlinear Diffusion Model (INDM) learns the nonlinear diffusion process by combining a normalizing flow and a diffusion process. Specifically, INDM implicitly constructs a nonlinear diffusion on the \textit{data space} by leveraging a linear diffusion on the \textit{latent space} through a flow network. This flow network is the key to forming a nonlinear diffusion as the nonlinearity fully depends on the flow network. This flexible nonlinearity is what improves the learning curve of INDM to nearly MLE training, compared against the non-MLE training of DDPM++, which turns out to be a special case of INDM with the identity flow. Also, training the nonlinear diffusion empirically yields a sampling-friendly latent diffusion that the sample trajectory of INDM is closer to an optimal transport than the trajectories of previous research. In experiments, INDM achieves the state-of-the-art FID on CelebA.
Automatic Calibration Framework of Agent-Based Models for Dynamic and Heterogeneous Parameters
Mar 07, 2022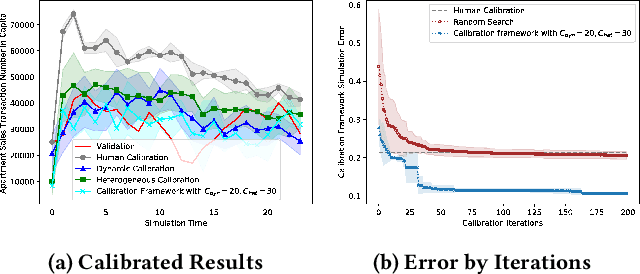
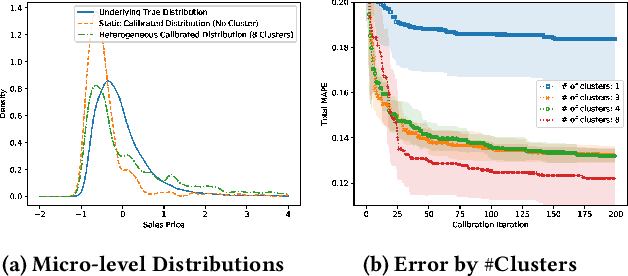
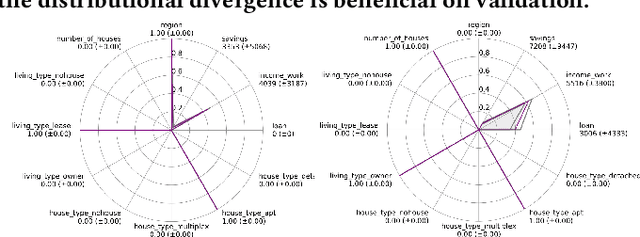
Agent-based models (ABMs) highlight the importance of simulation validation, such as qualitative face validation and quantitative empirical validation. In particular, we focused on quantitative validation by adjusting simulation input parameters of the ABM. This study introduces an automatic calibration framework that combines the suggested dynamic and heterogeneous calibration methods. Specifically, the dynamic calibration fits the simulation results to the real-world data by automatically capturing suitable simulation time to adjust the simulation parameters. Meanwhile, the heterogeneous calibration reduces the distributional discrepancy between individuals in the simulation and the real world by adjusting agent related parameters cluster-wisely.
Score Matching Model for Unbounded Data Score
Jun 10, 2021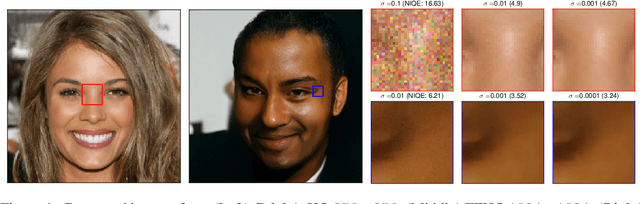
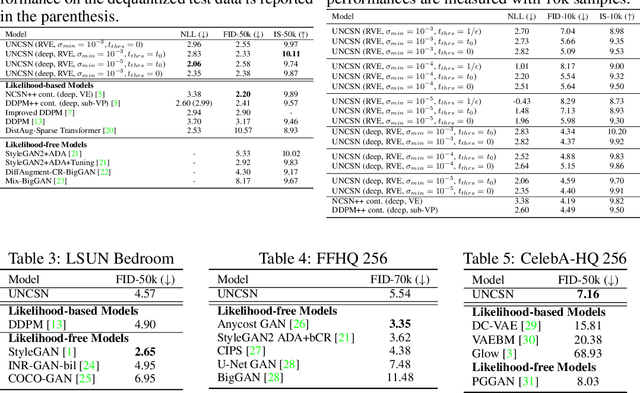


Recent advance in score-based models incorporates the stochastic differential equation (SDE), which brings the state-of-the art performance on image generation tasks. This paper improves such score-based models by analyzing the model at the zero perturbation noise. In real datasets, the score function diverges as the perturbation noise ($\sigma$) decreases to zero, and this observation leads an argument that the score estimation fails at $\sigma=0$ with any neural network structure. Subsequently, we introduce Unbounded Noise Conditional Score Network (UNCSN) that resolves the score diverging problem with an easily applicable modification to any noise conditional score-based models. Additionally, we introduce a new type of SDE, so the exact log likelihood can be calculated from the newly suggested SDE. On top of that, the associated loss function mitigates the loss imbalance issue in a mini-batch, and we present a theoretic analysis on the proposed loss to uncover the behind mechanism of the data distribution modeling by the score-based models.
Posterior-Aided Regularization for Likelihood-Free Inference
Feb 15, 2021
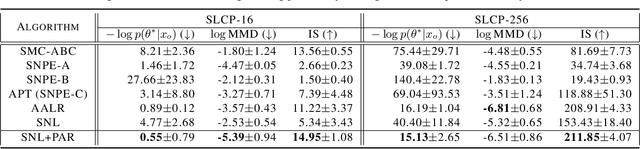
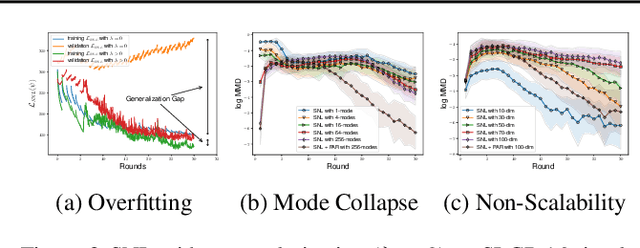
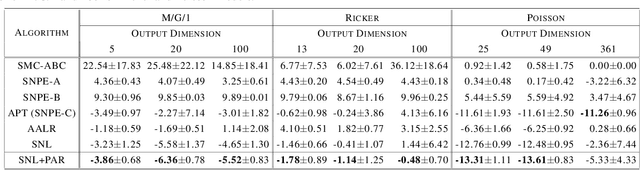
The recent development of likelihood-free inference aims training a flexible density estimator for the target posterior with a set of input-output pairs from simulation. Given the diversity of simulation structures, it is difficult to find a single unified inference method for each simulation model. This paper proposes a universally applicable regularization technique, called Posterior-Aided Regularization (PAR), which is applicable to learning the density estimator, regardless of the model structure. Particularly, PAR solves the mode collapse problem that arises as the output dimension of the simulation increases. PAR resolves this posterior mode degeneracy through a mixture of 1) the reverse KL divergence with the mode seeking property; and 2) the mutual information for the high quality representation on likelihood. Because of the estimation intractability of PAR, we provide a unified estimation method of PAR to estimate both reverse KL term and mutual information term with a single neural network. Afterwards, we theoretically prove the asymptotic convergence of the regularized optimal solution to the unregularized optimal solution as the regularization magnitude converges to zero. Additionally, we empirically show that past sequential neural likelihood inferences in conjunction with PAR present the statistically significant gains on diverse simulation tasks.
Sequential Likelihood-Free Inference with Implicit Surrogate Proposal
Oct 15, 2020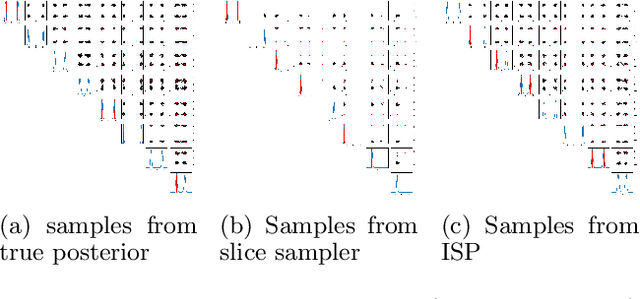
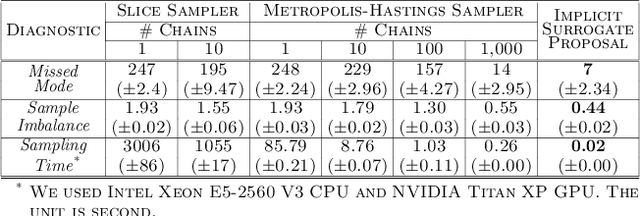


Bayesian inference without the access of likelihood, called likelihood-free inference, is highlighted in simulation to yield a more realistic simulation result. Recent research updates an approximate posterior sequentially with the cumulative simulation input-output pairs over inference rounds. This paper observes that previous algorithms with Monte-Carlo Markov Chain present low accuracy for inference on a simulation with a multi-modal posterior due to the mode collapse of MCMC. From the observation, we propose an implicit sampling method, Implicit Surrogate Proposal (ISP), to draw balanced simulation inputs at each round. The resolution of mode collapse comes from two mechanisms: 1) a flexible surrogate proposal density estimator and 2) a parallel explored samples to train the surrogate density model. We demonstrate that ISP outperforms the baseline algorithms in multi-modal simulations.
Implicit Kernel Attention
Jun 11, 2020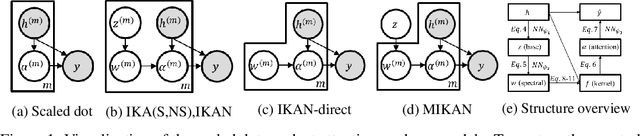
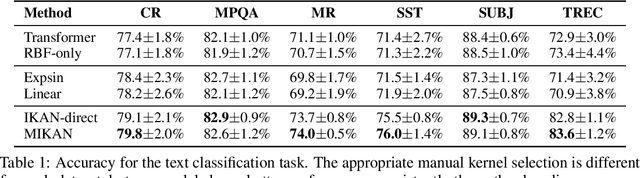


Attention compute the dependency between representations, and it encourages the model to focus on the important selective features. Among the attention methods, the scaled dot-product attention is widely utilized in many models. This paper suggests a generalized structure of the scaled dot-product attention with similarity and magnitude terms. We derive that the scaled dot-product attention is a product of two parts: 1) the RBF kernel to measure the similarity of two instances and 2) the exponential $L^{2}$ norm to compute the importance of individual instances. From this decomposition, we improve the attention in two ways: implicit modeling on the kernel spectral density and generalized $L^{p}$ norm, which results in a learnable and flexible attention structure. First, we estimate the spectral density of kernel with implicit probabilistic models to estimate the appropriate kernel for a given dataset without kernel selection manually. Second, we introduce a generalized $L^p$ norm on the hidden feature space, where $p$ is a hyper-parameter that affects the scale of individual importance and the sparsity of attention weights. Also, we show how to expand this implicit kernel modeling to multi-head attention in conjunction with a copula augmentation. Our generalized attention shows better performance on text classification, translation, regression, and node classification tasks.