 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDongyoon Han
HYPE: Hyperbolic Entailment Filtering for Underspecified Images and Texts
Apr 26, 2024
In an era where the volume of data drives the effectiveness of self-supervised learning, the specificity and clarity of data semantics play a crucial role in model training. Addressing this, we introduce HYPerbolic Entailment filtering (HYPE), a novel methodology designed to meticulously extract modality-wise meaningful and well-aligned data from extensive, noisy image-text pair datasets. Our approach leverages hyperbolic embeddings and the concept of entailment cones to evaluate and filter out samples with meaningless or underspecified semantics, focusing on enhancing the specificity of each data sample. HYPE not only demonstrates a significant improvement in filtering efficiency but also sets a new state-of-the-art in the DataComp benchmark when combined with existing filtering techniques. This breakthrough showcases the potential of HYPE to refine the data selection process, thereby contributing to the development of more accurate and efficient self-supervised learning models. Additionally, the image specificity $\epsilon_{i}$ can be independently applied to induce an image-only dataset from an image-text or image-only data pool for training image-only self-supervised models and showed superior performance when compared to the dataset induced by CLIP score.
Leveraging Temporal Contextualization for Video Action Recognition
Apr 15, 2024Pretrained vision-language models have shown effectiveness in video understanding. However, recent studies have not sufficiently leveraged essential temporal information from videos, simply averaging frame-wise representations or referencing consecutive frames. We introduce Temporally Contextualized CLIP (TC-CLIP), a pioneering framework for video understanding that effectively and efficiently leverages comprehensive video information. We propose Temporal Contextualization (TC), a novel layer-wise temporal information infusion mechanism for video that extracts core information from each frame, interconnects relevant information across the video to summarize into context tokens, and ultimately leverages the context tokens during the feature encoding process. Furthermore, our Video-conditional Prompting (VP) module manufactures context tokens to generate informative prompts in text modality. We conduct extensive experiments in zero-shot, few-shot, base-to-novel, and fully-supervised action recognition to validate the superiority of our TC-CLIP. Ablation studies for TC and VP guarantee our design choices. Code is available at https://github.com/naver-ai/tc-clip
Model Stock: All we need is just a few fine-tuned models
Mar 28, 2024



This paper introduces an efficient fine-tuning method for large pre-trained models, offering strong in-distribution (ID) and out-of-distribution (OOD) performance. Breaking away from traditional practices that need a multitude of fine-tuned models for averaging, our approach employs significantly fewer models to achieve final weights yet yield superior accuracy. Drawing from key insights in the weight space of fine-tuned weights, we uncover a strong link between the performance and proximity to the center of weight space. Based on this, we introduce a method that approximates a center-close weight using only two fine-tuned models, applicable during or after training. Our innovative layer-wise weight averaging technique surpasses state-of-the-art model methods such as Model Soup, utilizing only two fine-tuned models. This strategy can be aptly coined Model Stock, highlighting its reliance on selecting a minimal number of models to draw a more optimized-averaged model. We demonstrate the efficacy of Model Stock with fine-tuned models based upon pre-trained CLIP architectures, achieving remarkable performance on both ID and OOD tasks on the standard benchmarks, all while barely bringing extra computational demands. Our code and pre-trained models are available at https://github.com/naver-ai/model-stock.
DenseNets Reloaded: Paradigm Shift Beyond ResNets and ViTs
Mar 28, 2024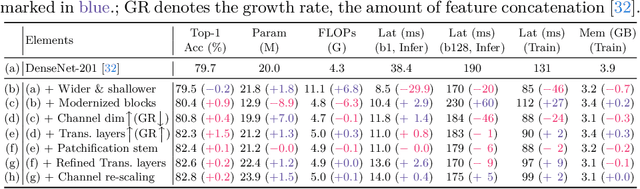
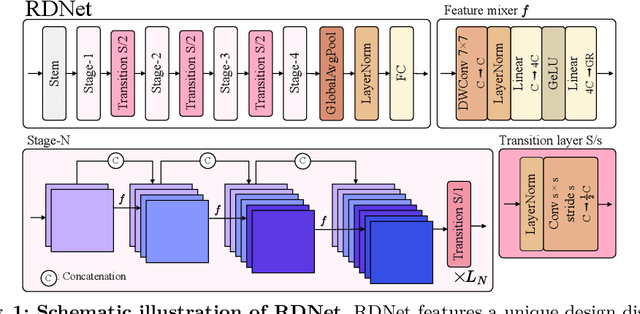
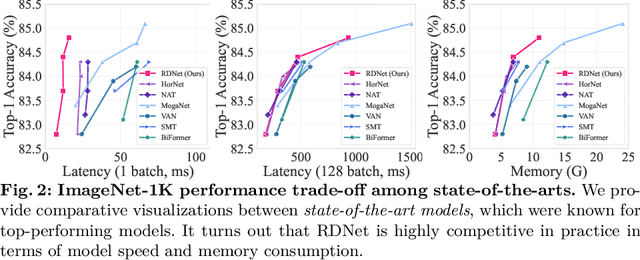
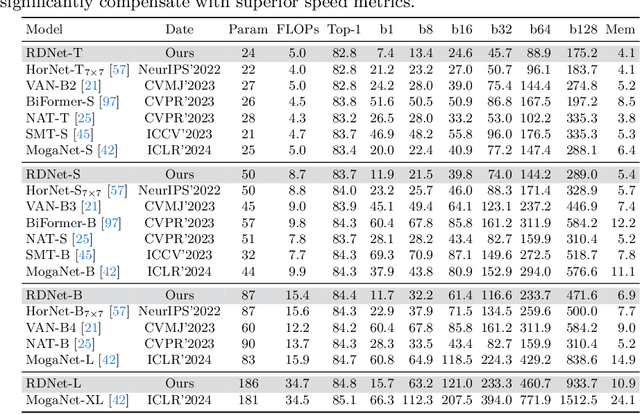
This paper revives Densely Connected Convolutional Networks (DenseNets) and reveals the underrated effectiveness over predominant ResNet-style architectures. We believe DenseNets' potential was overlooked due to untouched training methods and traditional design elements not fully revealing their capabilities. Our pilot study shows dense connections through concatenation are strong, demonstrating that DenseNets can be revitalized to compete with modern architectures. We methodically refine suboptimal components - architectural adjustments, block redesign, and improved training recipes towards widening DenseNets and boosting memory efficiency while keeping concatenation shortcuts. Our models, employing simple architectural elements, ultimately surpass Swin Transformer, ConvNeXt, and DeiT-III - key architectures in the residual learning lineage. Furthermore, our models exhibit near state-of-the-art performance on ImageNet-1K, competing with the very recent models and downstream tasks, ADE20k semantic segmentation, and COCO object detection/instance segmentation. Finally, we provide empirical analyses that uncover the merits of the concatenation over additive shortcuts, steering a renewed preference towards DenseNet-style designs. Our code is available at https://github.com/naver-ai/rdnet.
Rotary Position Embedding for Vision Transformer
Mar 20, 2024
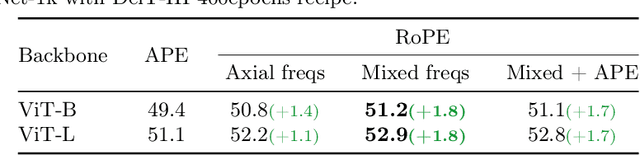
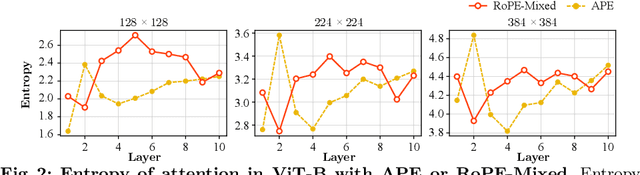
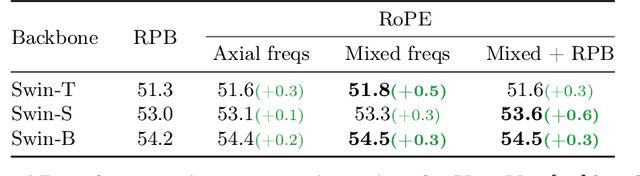
Rotary Position Embedding (RoPE) performs remarkably on language models, especially for length extrapolation of Transformers. However, the impacts of RoPE on computer vision domains have been underexplored, even though RoPE appears capable of enhancing Vision Transformer (ViT) performance in a way similar to the language domain. This study provides a comprehensive analysis of RoPE when applied to ViTs, utilizing practical implementations of RoPE for 2D vision data. The analysis reveals that RoPE demonstrates impressive extrapolation performance, i.e., maintaining precision while increasing image resolution at inference. It eventually leads to performance improvement for ImageNet-1k, COCO detection, and ADE-20k segmentation. We believe this study provides thorough guidelines to apply RoPE into ViT, promising improved backbone performance with minimal extra computational overhead. Our code and pre-trained models are available at https://github.com/naver-ai/rope-vit
Masked Image Modeling via Dynamic Token Morphing
Dec 30, 2023Masked Image Modeling (MIM) arises as a promising option for Vision Transformers among various self-supervised learning (SSL) methods. The essence of MIM lies in token-wise masked patch predictions, with targets patchified from images; or generated by pre-trained tokenizers or models. We argue targets from the pre-trained models usually exhibit spatial inconsistency, which makes it excessively challenging for the model to follow to learn more discriminative representations. To mitigate the issue, we introduce a novel self-supervision signal based on Dynamic Token Morphing (DTM), which dynamically aggregates contextually related tokens. DTM can be generally applied to various SSL frameworks, yet we propose a simple MIM that employs DTM to effectively improve the performance barely introducing extra training costs. Our experiments on ImageNet-1K and ADE20K evidently demonstrate the superiority of our methods. Furthermore, the comparative evaluation of iNaturalist and Fine-grained Visual Classification datasets further validates the transferability of our method on various downstream tasks. Our code will be released publicly.
Forging Tokens for Improved Storage-efficient Training
Dec 15, 2023Recent advancements in Deep Neural Network (DNN) models have significantly improved performance across computer vision tasks. However, achieving highly generalizable and high-performing vision models requires extensive datasets, leading to large storage requirements. This storage challenge poses a critical bottleneck for scaling up vision models. Motivated by the success of discrete representations, SeiT proposes to use Vector-Quantized (VQ) feature vectors (i.e., tokens) as network inputs for vision classification. However, applying traditional data augmentations to tokens faces challenges due to input domain shift. To address this issue, we introduce TokenAdapt and ColorAdapt, simple yet effective token-based augmentation strategies. TokenAdapt realigns token embedding space for compatibility with spatial augmentations, preserving the model's efficiency without requiring fine-tuning. Additionally, ColorAdapt addresses color-based augmentations for tokens inspired by Adaptive Instance Normalization (AdaIN). We evaluate our approach across various scenarios, including storage-efficient ImageNet-1k classification, fine-grained classification, robustness benchmarks, and ADE-20k semantic segmentation. Experimental results demonstrate consistent performance improvement in diverse experiments. Code is available at https://github.com/naver-ai/tokenadapt.
Match me if you can: Semantic Correspondence Learning with Unpaired Images
Nov 30, 2023Recent approaches for semantic correspondence have focused on obtaining high-quality correspondences using a complicated network, refining the ambiguous or noisy matching points. Despite their performance improvements, they remain constrained by the limited training pairs due to costly point-level annotations. This paper proposes a simple yet effective method that performs training with unlabeled pairs to complement both limited image pairs and sparse point pairs, requiring neither extra labeled keypoints nor trainable modules. We fundamentally extend the data quantity and variety by augmenting new unannotated pairs not primitively provided as training pairs in benchmarks. Using a simple teacher-student framework, we offer reliable pseudo correspondences to the student network via machine supervision. Finally, the performance of our network is steadily improved by the proposed iterative training, putting back the student as a teacher to generate refined labels and train a new student repeatedly. Our models outperform the milestone baselines, including state-of-the-art methods on semantic correspondence benchmarks.
Switching Temporary Teachers for Semi-Supervised Semantic Segmentation
Oct 28, 2023The teacher-student framework, prevalent in semi-supervised semantic segmentation, mainly employs the exponential moving average (EMA) to update a single teacher's weights based on the student's. However, EMA updates raise a problem in that the weights of the teacher and student are getting coupled, causing a potential performance bottleneck. Furthermore, this problem may become more severe when training with more complicated labels such as segmentation masks but with few annotated data. This paper introduces Dual Teacher, a simple yet effective approach that employs dual temporary teachers aiming to alleviate the coupling problem for the student. The temporary teachers work in shifts and are progressively improved, so consistently prevent the teacher and student from becoming excessively close. Specifically, the temporary teachers periodically take turns generating pseudo-labels to train a student model and maintain the distinct characteristics of the student model for each epoch. Consequently, Dual Teacher achieves competitive performance on the PASCAL VOC, Cityscapes, and ADE20K benchmarks with remarkably shorter training times than state-of-the-art methods. Moreover, we demonstrate that our approach is model-agnostic and compatible with both CNN- and Transformer-based models. Code is available at \url{https://github.com/naver-ai/dual-teacher}.
Gramian Attention Heads are Strong yet Efficient Vision Learners
Oct 25, 2023We introduce a novel architecture design that enhances expressiveness by incorporating multiple head classifiers (\ie, classification heads) instead of relying on channel expansion or additional building blocks. Our approach employs attention-based aggregation, utilizing pairwise feature similarity to enhance multiple lightweight heads with minimal resource overhead. We compute the Gramian matrices to reinforce class tokens in an attention layer for each head. This enables the heads to learn more discriminative representations, enhancing their aggregation capabilities. Furthermore, we propose a learning algorithm that encourages heads to complement each other by reducing correlation for aggregation. Our models eventually surpass state-of-the-art CNNs and ViTs regarding the accuracy-throughput trade-off on ImageNet-1K and deliver remarkable performance across various downstream tasks, such as COCO object instance segmentation, ADE20k semantic segmentation, and fine-grained visual classification datasets. The effectiveness of our framework is substantiated by practical experimental results and further underpinned by generalization error bound. We release the code publicly at: https://github.com/Lab-LVM/imagenet-models.