 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEduardo F. Mendes
Generalized Information Criteria for Structured Sparse Models
Sep 04, 2023
Regularized m-estimators are widely used due to their ability of recovering a low-dimensional model in high-dimensional scenarios. Some recent efforts on this subject focused on creating a unified framework for establishing oracle bounds, and deriving conditions for support recovery. Under this same framework, we propose a new Generalized Information Criteria (GIC) that takes into consideration the sparsity pattern one wishes to recover. We obtain non-asymptotic model selection bounds and sufficient conditions for model selection consistency of the GIC. Furthermore, we show that the GIC can also be used for selecting the regularization parameter within a regularized $m$-estimation framework, which allows practical use of the GIC for model selection in high-dimensional scenarios. We provide examples of group LASSO in the context of generalized linear regression and low rank matrix regression.
Machine Learning Advances for Time Series Forecasting
Jan 18, 2021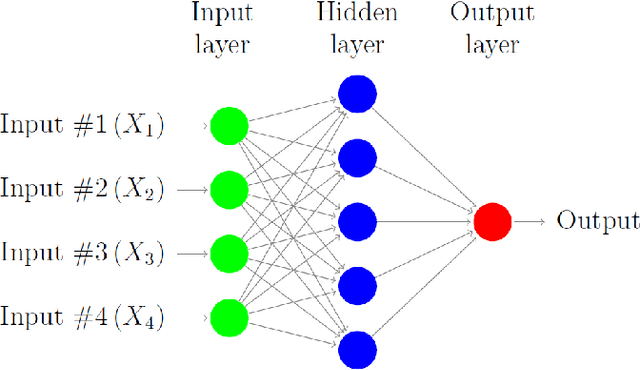
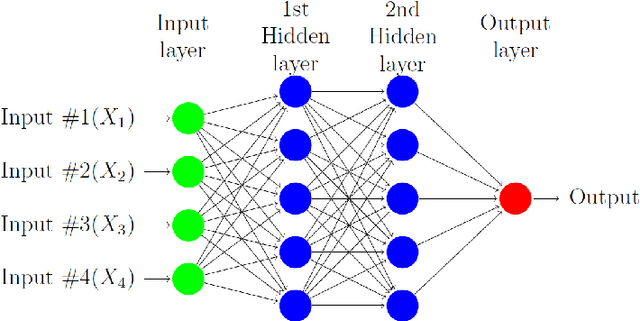
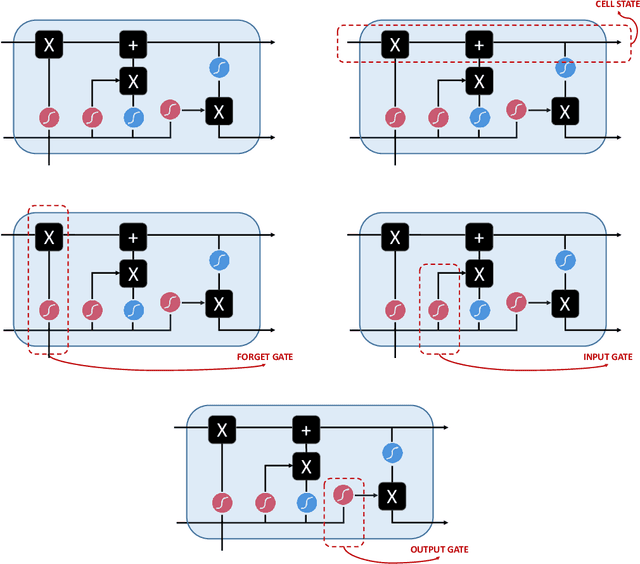
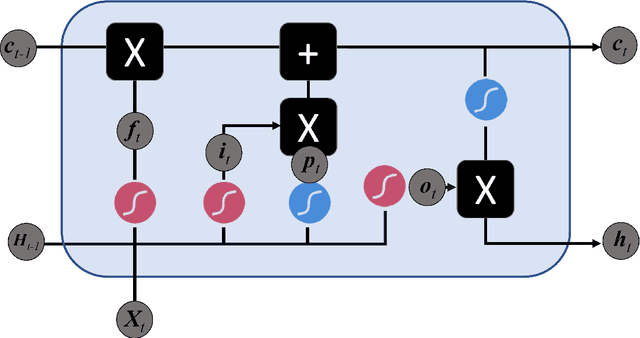
In this paper we survey the most recent advances in supervised machine learning and high-dimensional models for time series forecasting. We consider both linear and nonlinear alternatives. Among the linear methods we pay special attention to penalized regressions and ensemble of models. The nonlinear methods considered in the paper include shallow and deep neural networks, in their feed-forward and recurrent versions, and tree-based methods, such as random forests and boosted trees. We also consider ensemble and hybrid models by combining ingredients from different alternatives. Tests for superior predictive ability are briefly reviewed. Finally, we discuss application of machine learning in economics and finance and provide an illustration with high-frequency financial data.
Regularized Estimation of High-Dimensional Vector AutoRegressions with Weakly Dependent Innovations
Dec 19, 2019
There has been considerable advance in understanding the properties of sparse regularization procedures in high-dimensional models. Most of the work is limited to either independent and identically distributed setting, or time series with independent and/or (sub-)Gaussian innovations. We extend current literature to a broader set of innovation processes, by assuming that the error process is non-sub-Gaussian and conditionally heteroscedastic, and the generating process is not necessarily sparse. This setting covers fat tailed, conditionally dependent innovations which is of particular interest for financial risk modeling. It covers several multivariate-GARCH specifications, such as the BEKK model, and other factor stochastic volatility specifications.
Convergence Rates for Mixture-of-Experts
Nov 01, 2011
In mixtures-of-experts (ME) model, where a number of submodels (experts) are combined, there have been two longstanding problems: (i) how many experts should be chosen, given the size of the training data? (ii) given the total number of parameters, is it better to use a few very complex experts, or is it better to combine many simple experts? In this paper, we try to provide some insights to these problems through a theoretic study on a ME structure where $m$ experts are mixed, with each expert being related to a polynomial regression model of order $k$. We study the convergence rate of the maximum likelihood estimator (MLE), in terms of how fast the Kullback-Leibler divergence of the estimated density converges to the true density, when the sample size $n$ increases. The convergence rate is found to be dependent on both $m$ and $k$, and certain choices of $m$ and $k$ are found to produce optimal convergence rates. Therefore, these results shed light on the two aforementioned important problems: on how to choose $m$, and on how $m$ and $k$ should be compromised, for achieving good convergence rates.
Model Selection Consistency for Cointegrating Regressions
Oct 10, 2011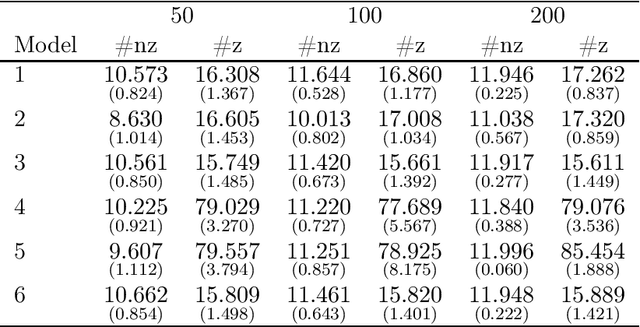
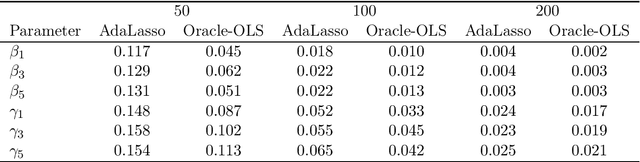
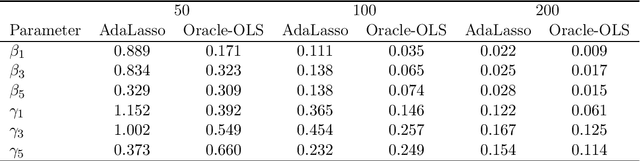

We study the asymptotic properties of the adaptive Lasso in cointegration regressions in the case where all covariates are weakly exogenous. We assume the number of candidate I(1) variables is sub-linear with respect to the sample size (but possibly larger) and the number of candidate I(0) variables is polynomial with respect to the sample size. We show that, under classical conditions used in cointegration analysis, this estimator asymptotically chooses the correct subset of variables in the model and its asymptotic distribution is the same as the distribution of the OLS estimate given the variables in the model were known in beforehand (oracle property). We also derive an algorithm based on the local quadratic approximation and present a numerical study to show the adequacy of the method in finite samples.