 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEero P. Simoncelli
Layerwise complexity-matched learning yields an improved model of cortical area V2
Dec 18, 2023
Human ability to recognize complex visual patterns arises through transformations performed by successive areas in the ventral visual cortex. Deep neural networks trained end-to-end for object recognition approach human capabilities, and offer the best descriptions to date of neural responses in the late stages of the hierarchy. But these networks provide a poor account of the early stages, compared to traditional hand-engineered models, or models optimized for coding efficiency or prediction. Moreover, the gradient backpropagation used in end-to-end learning is generally considered to be biologically implausible. Here, we overcome both of these limitations by developing a bottom-up self-supervised training methodology that operates independently on successive layers. Specifically, we maximize feature similarity between pairs of locally-deformed natural image patches, while decorrelating features across patches sampled from other images. Crucially, the deformation amplitudes are adjusted proportionally to receptive field sizes in each layer, thus matching the task complexity to the capacity at each stage of processing. In comparison with architecture-matched versions of previous models, we demonstrate that our layerwise complexity-matched learning (LCL) formulation produces a two-stage model (LCL-V2) that is better aligned with selectivity properties and neural activity in primate area V2. We demonstrate that the complexity-matched learning paradigm is critical for the emergence of the improved biological alignment. Finally, when the two-stage model is used as a fixed front-end for a deep network trained to perform object recognition, the resultant model (LCL-V2Net) is significantly better than standard end-to-end self-supervised, supervised, and adversarially-trained models in terms of generalization to out-of-distribution tasks and alignment with human behavior.
Generalization in diffusion models arises from geometry-adaptive harmonic representation
Oct 04, 2023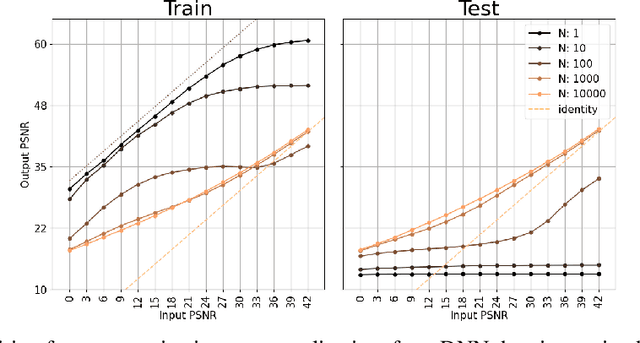
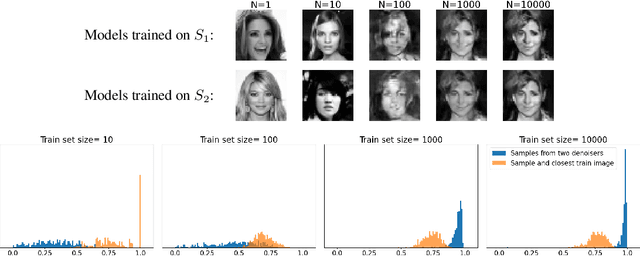
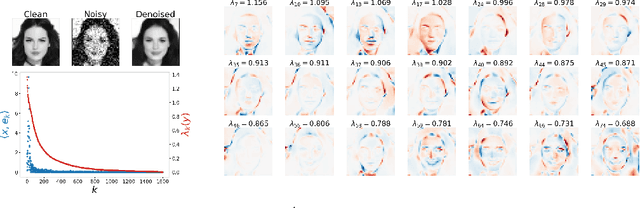
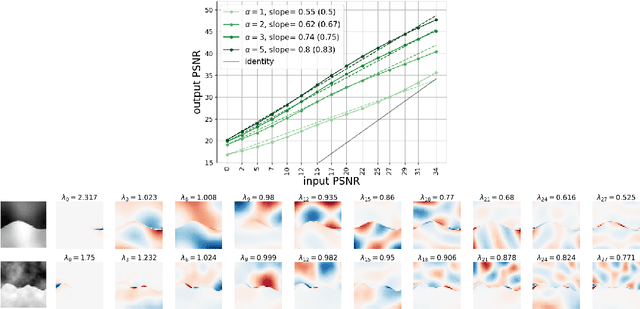
High-quality samples generated with score-based reverse diffusion algorithms provide evidence that deep neural networks (DNN) trained for denoising can learn high-dimensional densities, despite the curse of dimensionality. However, recent reports of memorization of the training set raise the question of whether these networks are learning the "true" continuous density of the data. Here, we show that two denoising DNNs trained on non-overlapping subsets of a dataset learn nearly the same score function, and thus the same density, with a surprisingly small number of training images. This strong generalization demonstrates an alignment of powerful inductive biases in the DNN architecture and/or training algorithm with properties of the data distribution. We analyze these, demonstrating that the denoiser performs a shrinkage operation in a basis adapted to the underlying image. Examination of these bases reveals oscillating harmonic structures along contours and in homogeneous image regions. We show that trained denoisers are inductively biased towards these geometry-adaptive harmonic representations by demonstrating that they arise even when the network is trained on image classes such as low-dimensional manifolds, for which the harmonic basis is suboptimal. Additionally, we show that the denoising performance of the networks is near-optimal when trained on regular image classes for which the optimal basis is known to be geometry-adaptive and harmonic.
Adaptive whitening with fast gain modulation and slow synaptic plasticity
Aug 25, 2023Neurons in early sensory areas rapidly adapt to changing sensory statistics, both by normalizing the variance of their individual responses and by reducing correlations between their responses. Together, these transformations may be viewed as an adaptive form of statistical whitening. Existing mechanistic models of adaptive whitening exclusively use either synaptic plasticity or gain modulation as the biological substrate for adaptation; however, on their own, each of these models has significant limitations. In this work, we unify these approaches in a normative multi-timescale mechanistic model that adaptively whitens its responses with complementary computational roles for synaptic plasticity and gain modulation. Gains are modified on a fast timescale to adapt to the current statistical context, whereas synapses are modified on a slow timescale to learn structural properties of the input statistics that are invariant across contexts. Our model is derived from a novel multi-timescale whitening objective that factorizes the inverse whitening matrix into basis vectors, which correspond to synaptic weights, and a diagonal matrix, which corresponds to neuronal gains. We test our model on synthetic and natural datasets and find that the synapses learn optimal configurations over long timescales that enable the circuit to adaptively whiten neural responses on short timescales exclusively using gain modulation.
Polar Prediction of Natural Videos
Mar 06, 2023
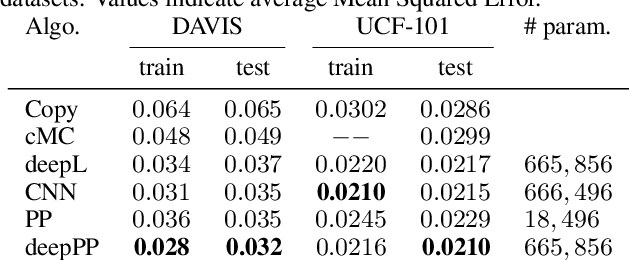
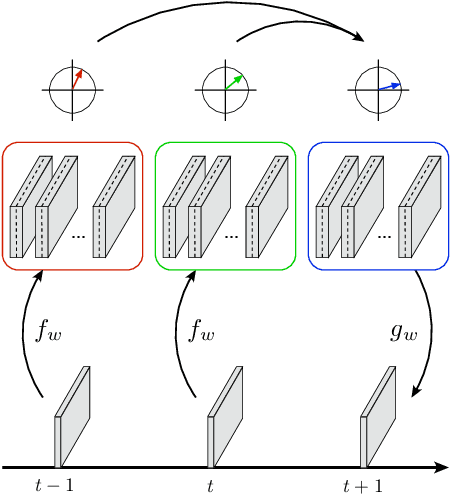
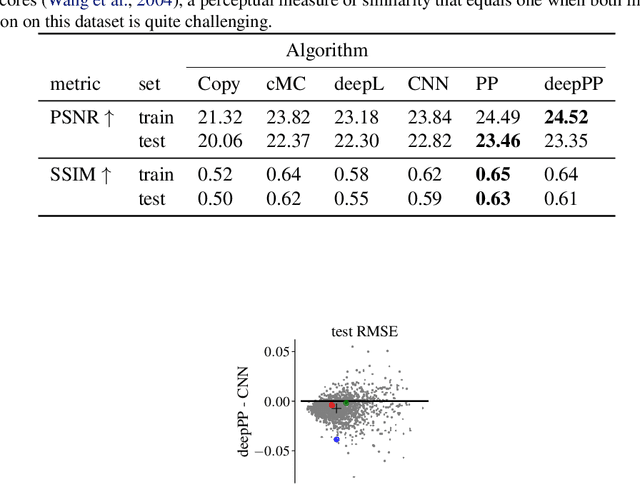
Observer motion and continuous deformations of objects and surfaces imbue natural videos with distinct temporal structures, enabling partial prediction of future frames from past ones. Conventional methods first estimate local motion, or optic flow, and then use it to predict future frames by warping or copying content. Here, we explore a more direct methodology, in which each frame is mapped into a learned representation space where the structure of temporal evolution is more readily accessible. Motivated by the geometry of the Fourier shift theorem and its group-theoretic generalization, we formulate a simple architecture that represents video frames in learned local polar coordinates. Specifically, we construct networks in which pairs of convolutional channel coefficients are treated as complex-valued, and are optimized to evolve with slowly varying amplitudes and linearly advancing phases. We train these models on next-frame prediction in natural videos, and compare their performance with that of conventional methods using optic flow as well as predictive neural networks. We find that the polar predictor achieves better performance while remaining interpretable and fast, thereby demonstrating the potential of a flow-free video processing methodology that is trained end-to-end to predict natural video content.
Statistical whitening of neural populations with gain-modulating interneurons
Jan 27, 2023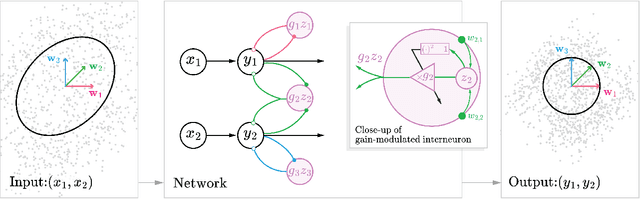
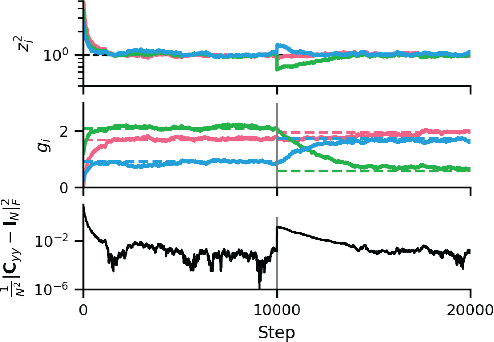
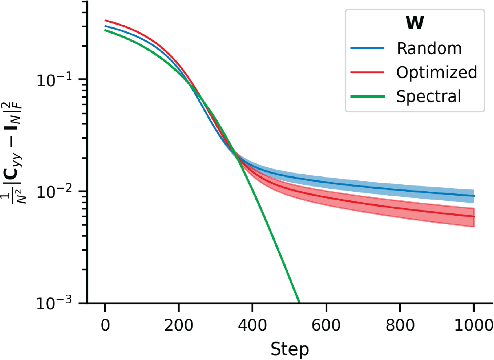
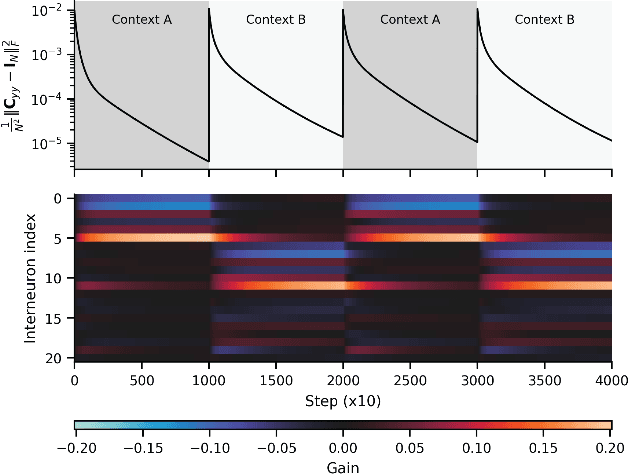
Statistical whitening transformations play a fundamental role in many computational systems, and may also play an important role in biological sensory systems. Individual neurons appear to rapidly and reversibly alter their input-output gains, approximately normalizing the variance of their responses. Populations of neurons appear to regulate their joint responses, reducing correlations between neural activities. It is natural to see whitening as the objective that guides these behaviors, but the mechanism for such joint changes is unknown, and direct adjustment of synaptic interactions would seem to be both too slow, and insufficiently reversible. Motivated by the extensive neuroscience literature on rapid gain modulation, we propose a recurrent network architecture in which joint whitening is achieved through modulation of gains within the circuit. Specifically, we derive an online statistical whitening algorithm that regulates the joint second-order statistics of a multi-dimensional input by adjusting the marginal variances of an overcomplete set of interneuron projections. The gains of these interneurons are adjusted individually, using only local signals, and feed back onto the primary neurons. The network converges to a state in which the responses of the primary neurons are whitened. We demonstrate through simulations that the behavior of the network is robust to poor conditioning or noise when the gains are sign-constrained, and can be generalized to achieve a form of local whitening in convolutional populations, such as those found throughout the visual or auditory system.
Adaptive Denoising via GainTuning
Jul 27, 2021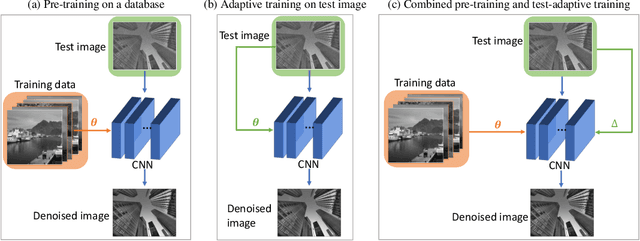
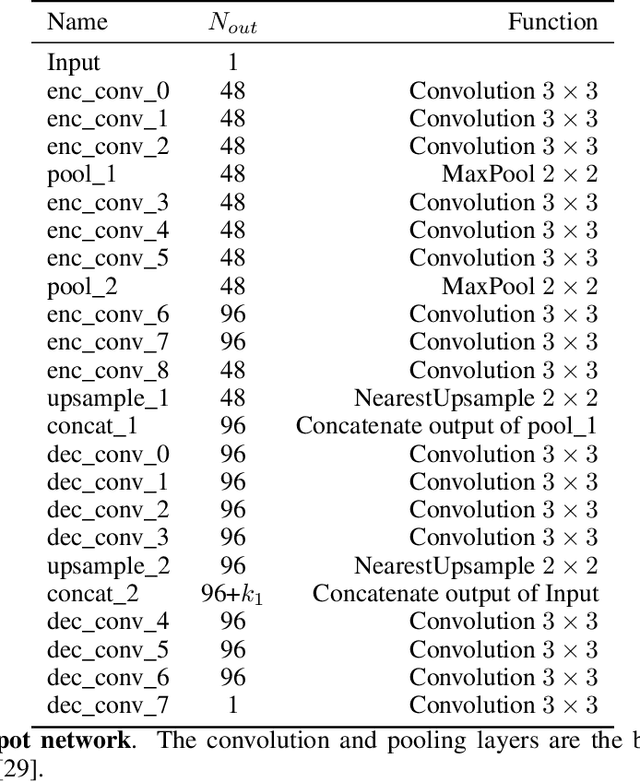
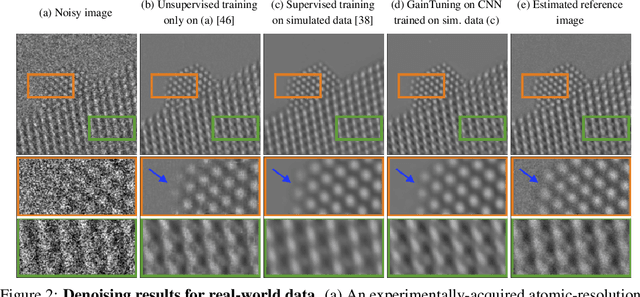

Deep convolutional neural networks (CNNs) for image denoising are usually trained on large datasets. These models achieve the current state of the art, but they have difficulties generalizing when applied to data that deviate from the training distribution. Recent work has shown that it is possible to train denoisers on a single noisy image. These models adapt to the features of the test image, but their performance is limited by the small amount of information used to train them. Here we propose "GainTuning", in which CNN models pre-trained on large datasets are adaptively and selectively adjusted for individual test images. To avoid overfitting, GainTuning optimizes a single multiplicative scaling parameter (the "Gain") of each channel in the convolutional layers of the CNN. We show that GainTuning improves state-of-the-art CNNs on standard image-denoising benchmarks, boosting their denoising performance on nearly every image in a held-out test set. These adaptive improvements are even more substantial for test images differing systematically from the training data, either in noise level or image type. We illustrate the potential of adaptive denoising in a scientific application, in which a CNN is trained on synthetic data, and tested on real transmission-electron-microscope images. In contrast to the existing methodology, GainTuning is able to faithfully reconstruct the structure of catalytic nanoparticles from these data at extremely low signal-to-noise ratios.
Developing a Deep Neural Network to Denoise Time-Resolved In Situ ETEM Movies of Catalyst Nanoparticles
Jan 19, 2021
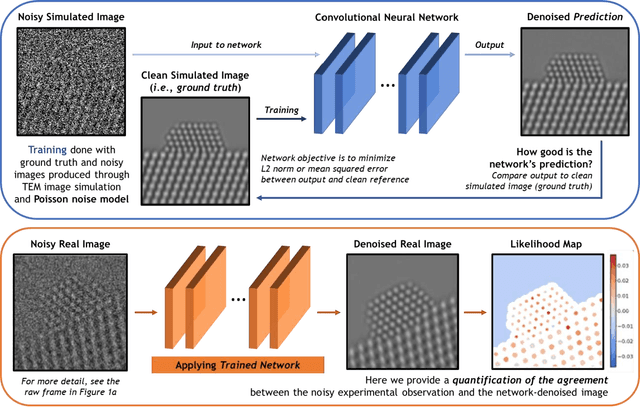
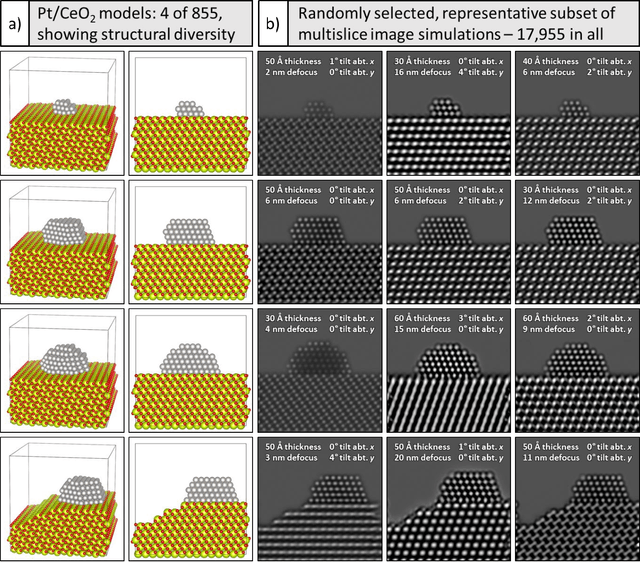

A deep learning-based convolutional neural network has been developed to denoise atomic-resolution in situ TEM image datasets of catalyst nanoparticles acquired on high speed, direct electron counting detectors, where the signal is severely limited by shot noise. The network was applied to a model catalyst of CeO2-supported Pt nanoparticles. We leverage multislice simulation to generate a large and flexible dataset for training and testing the network. The proposed network outperforms state-of-the-art denoising methods by a significant margin both on simulated and experimental test data. Factors contributing to the performance are identified, including most importantly (a) the geometry of the images used during training and (b) the size of the network's receptive field. Through a gradient-based analysis, we investigate the mechanisms used by the network to denoise experimental images. This shows the network exploits information on the surrounding structure and that it adapts its filtering approach when it encounters atomic-level defects at the catalyst surface. Extensive analysis has been done to characterize the network's ability to correctly predict the exact atomic structure at the catalyst surface. Finally, we develop an approach based on the log-likelihood ratio test that provides an quantitative measure of uncertainty regarding the atomic-level structure in the network-denoised image.
Unsupervised Deep Video Denoising
Dec 01, 2020
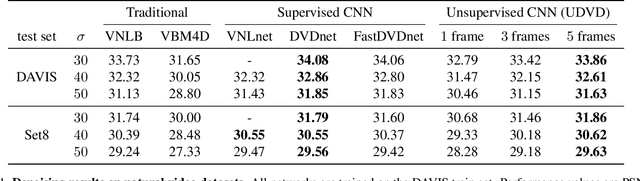
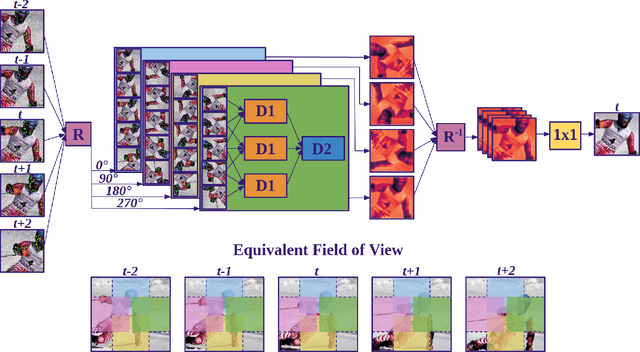
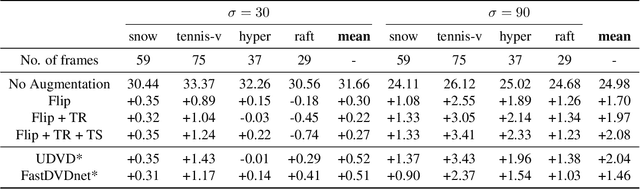
Deep convolutional neural networks (CNNs) currently achieve state-of-the-art performance in denoising videos. They are typically trained with supervision, minimizing the error between the network output and ground-truth clean videos. However, in many applications, such as microscopy, noiseless videos are not available. To address these cases, we build on recent advances in unsupervised still image denoising to develop an Unsupervised Deep Video Denoiser (UDVD). UDVD is shown to perform competitively with current state-of-the-art supervised methods on benchmark datasets, even when trained only on a single short noisy video sequence. Experiments on fluorescence-microscopy and electron-microscopy data illustrate the promise of our approach for imaging modalities where ground-truth clean data is generally not available. In addition, we study the mechanisms used by trained CNNs to perform video denoising. An analysis of the gradient of the network output with respect to its input reveals that these networks perform spatio-temporal filtering that is adapted to the particular spatial structures and motion of the underlying content. We interpret this as an implicit and highly effective form of motion compensation, a widely used paradigm in traditional video denoising, compression, and analysis. Code and iPython notebooks for our analysis are available in https://sreyas-mohan.github.io/udvd/ .
Deep Denoising For Scientific Discovery: A Case Study In Electron Microscopy
Oct 24, 2020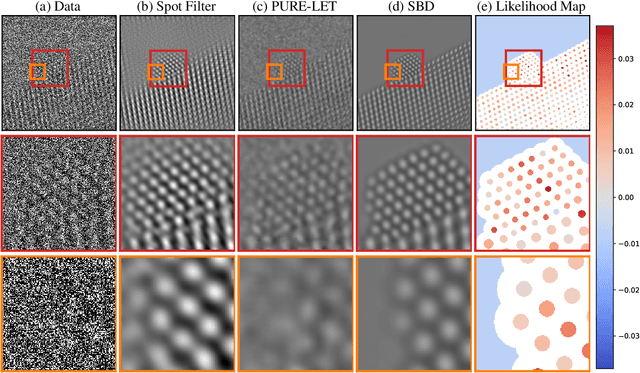
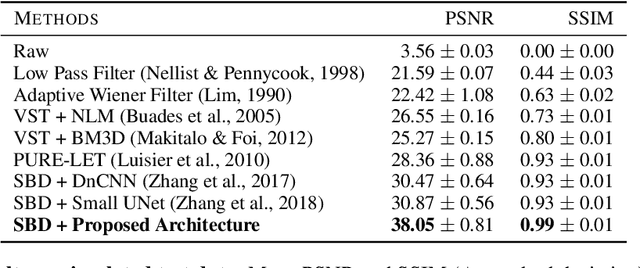
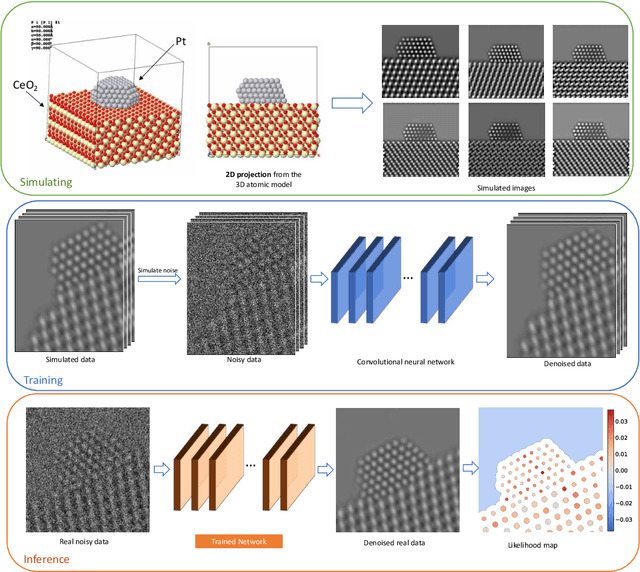
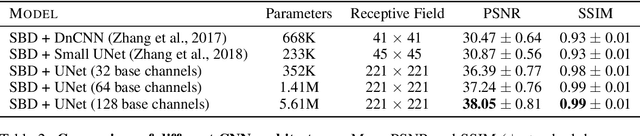
Denoising is a fundamental challenge in scientific imaging. Deep convolutional neural networks (CNNs) provide the current state of the art in denoising natural images, where they produce impressive results. However, their potential has barely been explored in the context of scientific imaging. Denoising CNNs are typically trained on real natural images artificially corrupted with simulated noise. In contrast, in scientific applications, noiseless ground-truth images are usually not available. To address this issue, we propose a simulation-based denoising (SBD) framework, in which CNNs are trained on simulated images. We test the framework on data obtained from transmission electron microscopy (TEM), an imaging technique with widespread applications in material science, biology, and medicine. SBD outperforms existing techniques by a wide margin on a simulated benchmark dataset, as well as on real data. Apart from the denoised images, SBD generates likelihood maps to visualize the agreement between the structure of the denoised image and the observed data. Our results reveal shortcomings of state-of-the-art denoising architectures, such as their small field-of-view: substantially increasing the field-of-view of the CNNs allows them to exploit non-local periodic patterns in the data, which is crucial at high noise levels. In addition, we analyze the generalization capability of SBD, demonstrating that the trained networks are robust to variations of imaging parameters and of the underlying signal structure. Finally, we release the first publicly available benchmark dataset of TEM images, containing 18,000 examples.
Solving Linear Inverse Problems Using the Prior Implicit in a Denoiser
Jul 27, 2020



Prior probability models are a central component of many image processing problems, but density estimation is notoriously difficult for high-dimensional signals such as photographic images. Deep neural networks have provided state-of-the-art solutions for problems such as denoising, which implicitly rely on a prior probability model of natural images. Here, we develop a robust and general methodology for making use of this implicit prior. We rely on a little-known statistical result due to Miyasawa (1961), who showed that the least-squares solution for removing additive Gaussian noise can be written directly in terms of the gradient of the log of the noisy signal density. We use this fact to develop a stochastic coarse-to-fine gradient ascent procedure for drawing high-probability samples from the implicit prior embedded within a CNN trained to perform blind (i.e., unknown noise level) least-squares denoising. A generalization of this algorithm to constrained sampling provides a method for using the implicit prior to solve any linear inverse problem, with no additional training. We demonstrate this general form of transfer learning in multiple applications, using the same algorithm to produce high-quality solutions for deblurring, super-resolution, inpainting, and compressive sensing.