 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfthymia Tsamoura
Parallel Neurosymbolic Integration with Concordia
Jun 14, 2023
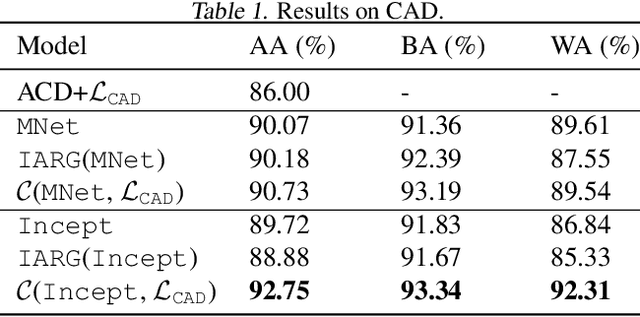
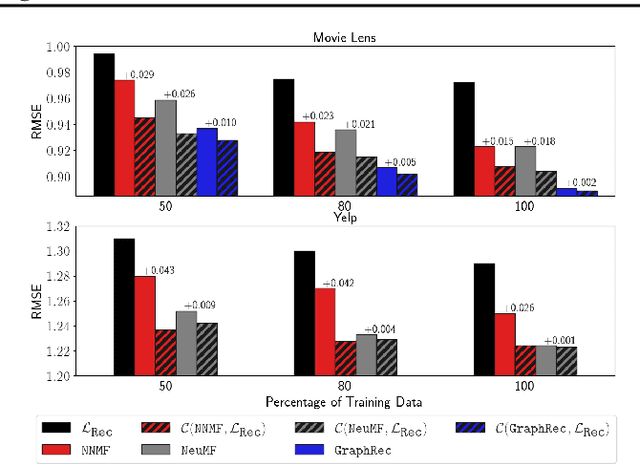
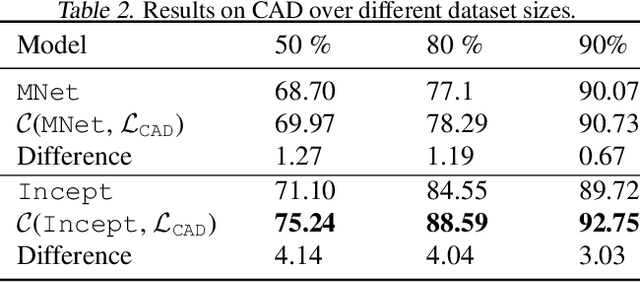
Parallel neurosymbolic architectures have been applied effectively in NLP by distilling knowledge from a logic theory into a deep model.However, prior art faces several limitations including supporting restricted forms of logic theories and relying on the assumption of independence between the logic and the deep network. We present Concordia, a framework overcoming the limitations of prior art. Concordia is agnostic both to the deep network and the logic theory offering support for a wide range of probabilistic theories. Our framework can support supervised training of both components and unsupervised training of the neural component. Concordia has been successfully applied to tasks beyond NLP and data classification, improving the accuracy of state-of-the-art on collective activity detection, entity linking and recommendation tasks.
Principled and Efficient Motif Finding for Structure Learning in Lifted Graphical Models
Feb 09, 2023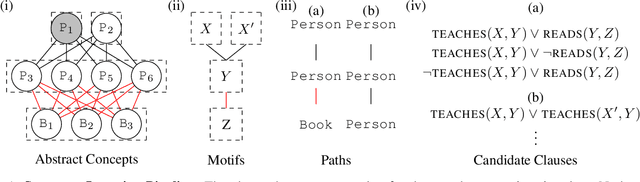
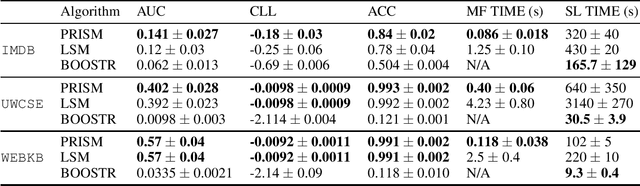
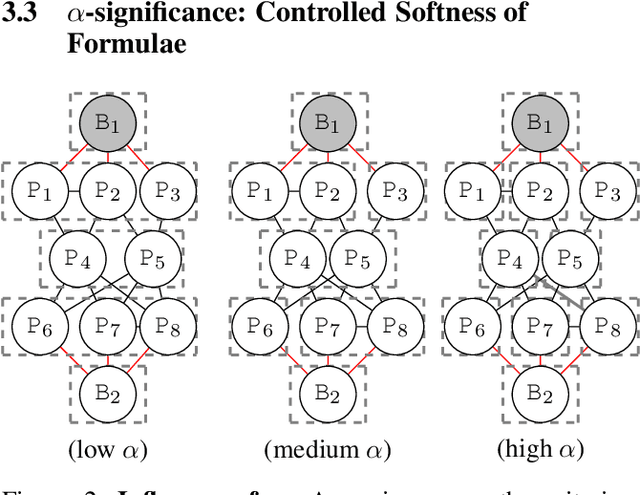
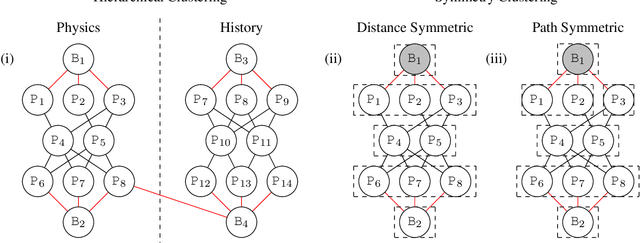
Structure learning is a core problem in AI central to the fields of neuro-symbolic AI and statistical relational learning. It consists in automatically learning a logical theory from data. The basis for structure learning is mining repeating patterns in the data, known as structural motifs. Finding these patterns reduces the exponential search space and therefore guides the learning of formulas. Despite the importance of motif learning, it is still not well understood. We present the first principled approach for mining structural motifs in lifted graphical models, languages that blend first-order logic with probabilistic models, which uses a stochastic process to measure the similarity of entities in the data. Our first contribution is an algorithm, which depends on two intuitive hyperparameters: one controlling the uncertainty in the entity similarity measure, and one controlling the softness of the resulting rules. Our second contribution is a preprocessing step where we perform hierarchical clustering on the data to reduce the search space to the most relevant data. Our third contribution is to introduce an O(n ln n) (in the size of the entities in the data) algorithm for clustering structurally-related data. We evaluate our approach using standard benchmarks and show that we outperform state-of-the-art structure learning approaches by up to 6% in terms of accuracy and up to 80% in terms of runtime.
Scalable Regularization of Scene Graph Generation Models using Symbolic Theories
Sep 06, 2022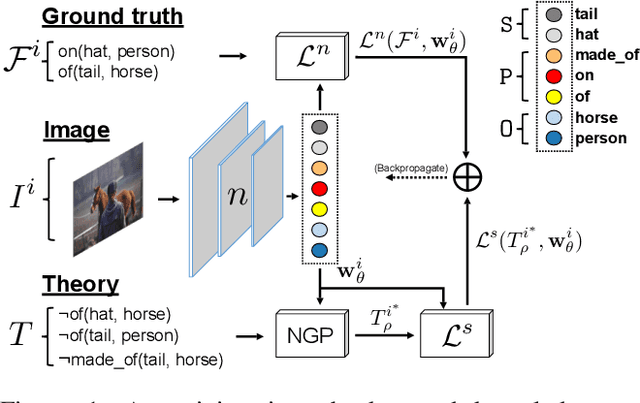

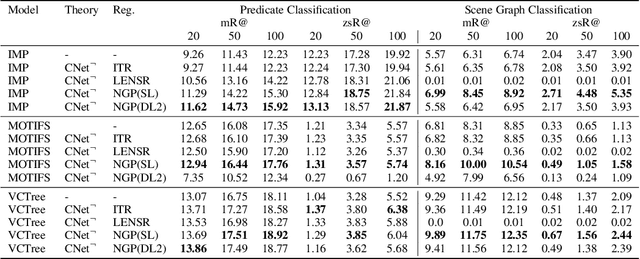
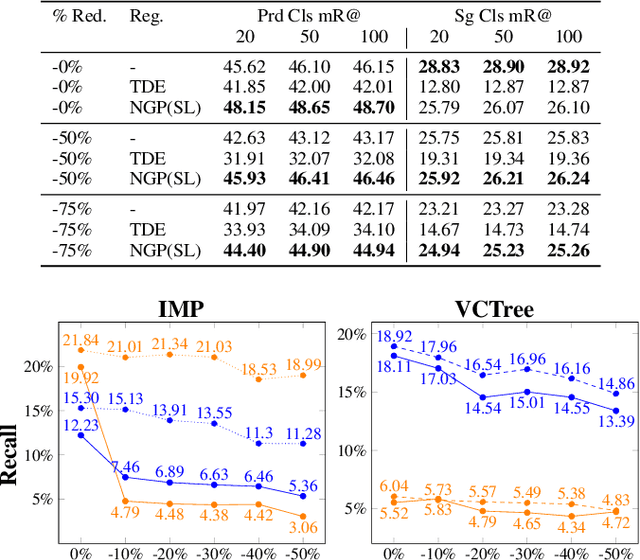
Several techniques have recently aimed to improve the performance of deep learning models for Scene Graph Generation (SGG) by incorporating background knowledge. State-of-the-art techniques can be divided into two families: one where the background knowledge is incorporated into the model in a subsymbolic fashion, and another in which the background knowledge is maintained in symbolic form. Despite promising results, both families of techniques face several shortcomings: the first one requires ad-hoc, more complex neural architectures increasing the training or inference cost; the second one suffers from limited scalability w.r.t. the size of the background knowledge. Our work introduces a regularization technique for injecting symbolic background knowledge into neural SGG models that overcomes the limitations of prior art. Our technique is model-agnostic, does not incur any cost at inference time, and scales to previously unmanageable background knowledge sizes. We demonstrate that our technique can improve the accuracy of state-of-the-art SGG models, by up to 33%.
Materializing Knowledge Bases via Trigger Graphs
Feb 04, 2021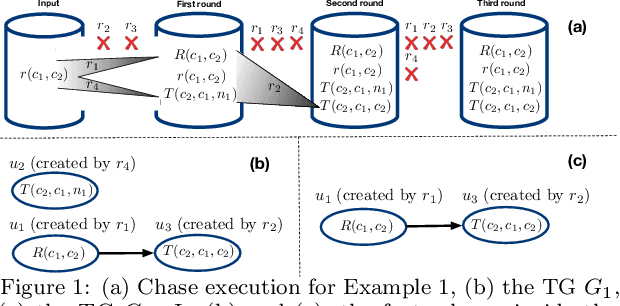
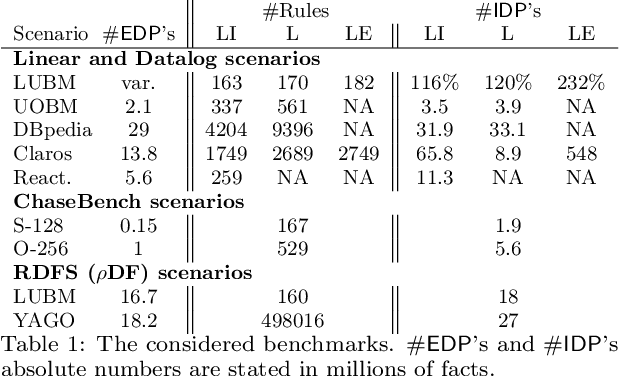
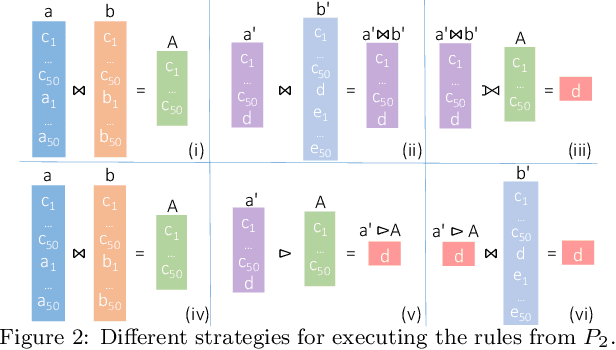

The chase is a well-established family of algorithms used to materialize Knowledge Bases (KBs), like Knowledge Graphs (KGs), to tackle important tasks like query answering under dependencies or data cleaning. A general problem of chase algorithms is that they might perform redundant computations. To counter this problem, we introduce the notion of Trigger Graphs (TGs), which guide the execution of the rules avoiding redundant computations. We present the results of an extensive theoretical and empirical study that seeks to answer when and how TGs can be computed and what are the benefits of TGs when applied over real-world KBs. Our results include introducing algorithms that compute (minimal) TGs. We implemented our approach in a new engine, and our experiments show that it can be significantly more efficient than the chase enabling us to materialize KBs with 17B facts in less than 40 min on commodity machines.
Neural-Symbolic Integration: A Compositional Perspective
Oct 22, 2020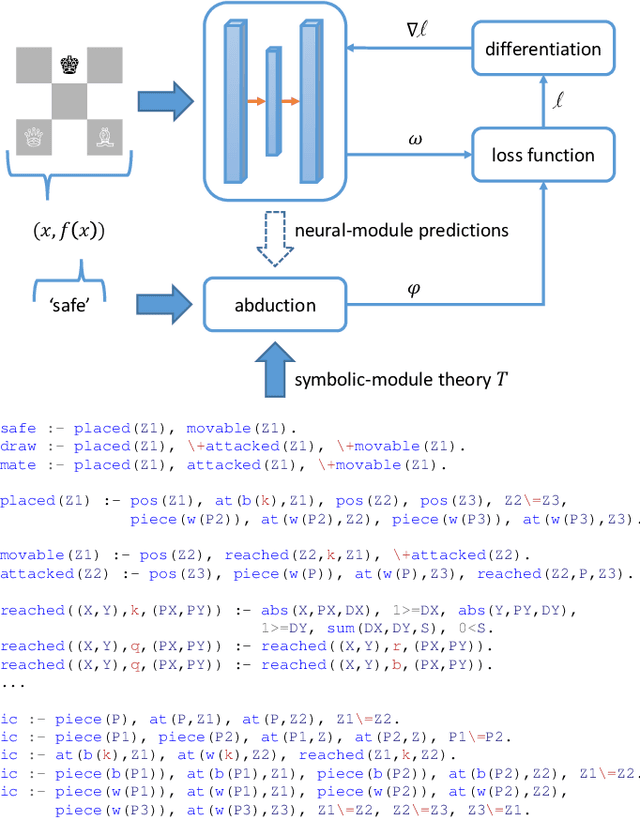
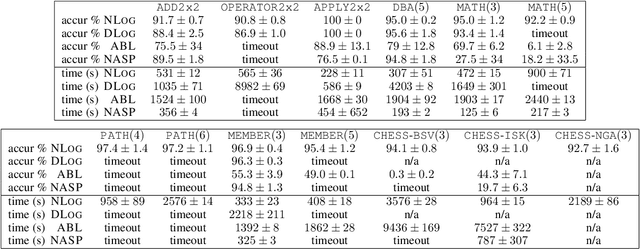
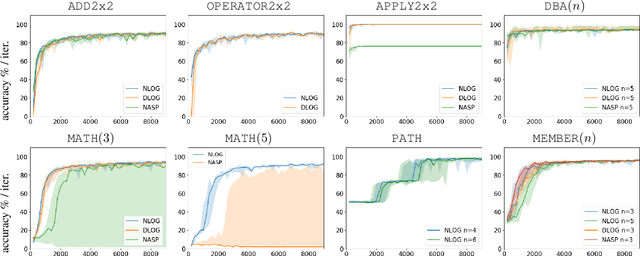
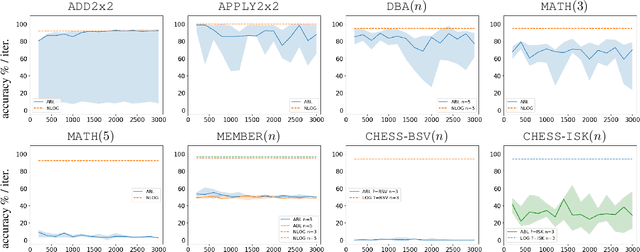
Despite significant progress in the development of neural-symbolic frameworks, the question of how to integrate a neural and a symbolic system in a \emph{compositional} manner remains open. Our work seeks to fill this gap by treating these two systems as black boxes to be integrated as modules into a single architecture, without making assumptions on their internal structure and semantics. Instead, we expect only that each module exposes certain methods for accessing the functions that the module implements: the symbolic module exposes a deduction method for computing the function's output on a given input, and an abduction method for computing the function's inputs for a given output; the neural module exposes a deduction method for computing the function's output on a given input, and an induction method for updating the function given input-output training instances. We are, then, able to show that a symbolic module --- with any choice for syntax and semantics, as long as the deduction and abduction methods are exposed --- can be cleanly integrated with a neural module, and facilitate the latter's efficient training, achieving empirical performance that exceeds that of previous work.
Beyond the Grounding Bottleneck: Datalog Techniques for Inference in Probabilistic Logic Programs (Technical Report)
Nov 18, 2019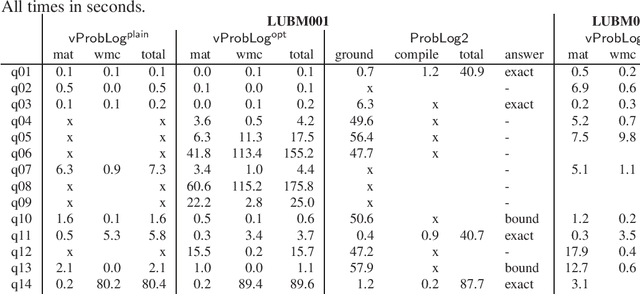
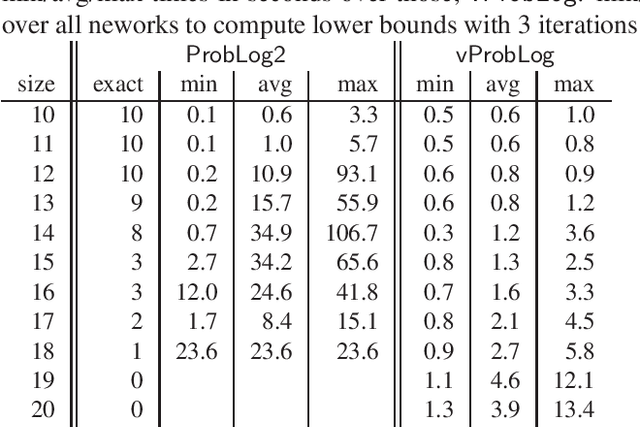
State-of-the-art inference approaches in probabilistic logic programming typically start by computing the relevant ground program with respect to the queries of interest, and then use this program for probabilistic inference using knowledge compilation and weighted model counting. We propose an alternative approach that uses efficient Datalog techniques to integrate knowledge compilation with forward reasoning with a non-ground program. This effectively eliminates the grounding bottleneck that so far has prohibited the application of probabilistic logic programming in query answering scenarios over knowledge graphs, while also providing fast approximations on classical benchmarks in the field.
Goal-Driven Query Answering for Existential Rules with Equality
Nov 20, 2017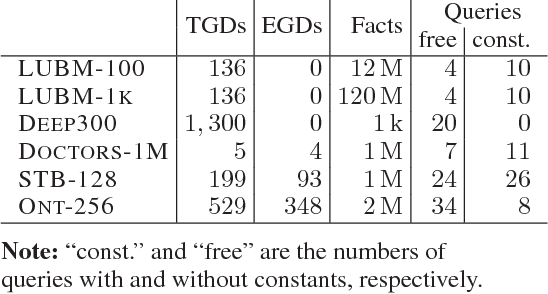
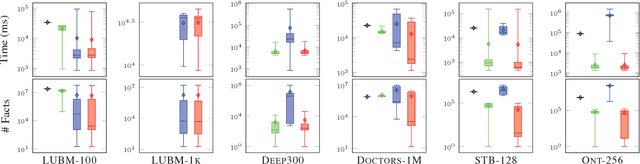
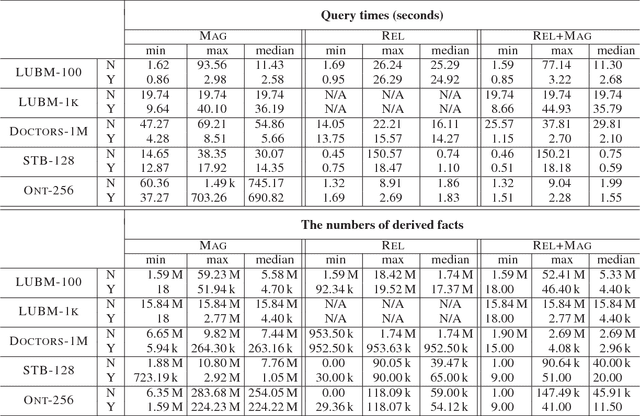
Inspired by the magic sets for Datalog, we present a novel goal-driven approach for answering queries over terminating existential rules with equality (aka TGDs and EGDs). Our technique improves the performance of query answering by pruning the consequences that are not relevant for the query. This is challenging in our setting because equalities can potentially affect all predicates in a dataset. We address this problem by combining the existing singularization technique with two new ingredients: an algorithm for identifying the rules relevant to a query and a new magic sets algorithm. We show empirically that our technique can significantly improve the performance of query answering, and that it can mean the difference between answering a query in a few seconds or not being able to process the query at all.