 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEkaterina Kochmar
Harnessing the Power of Multiple Minds: Lessons Learned from LLM Routing
May 01, 2024
With the rapid development of LLMs, it is natural to ask how to harness their capabilities efficiently. In this paper, we explore whether it is feasible to direct each input query to a single most suitable LLM. To this end, we propose LLM routing for challenging reasoning tasks. Our extensive experiments suggest that such routing shows promise but is not feasible in all scenarios, so more robust approaches should be investigated to fill this gap.
PetKaz at SemEval-2024 Task 8: Can Linguistics Capture the Specifics of LLM-generated Text?
Apr 08, 2024



In this paper, we present our submission to the SemEval-2024 Task 8 "Multigenerator, Multidomain, and Multilingual Black-Box Machine-Generated Text Detection", focusing on the detection of machine-generated texts (MGTs) in English. Specifically, our approach relies on combining embeddings from the RoBERTa-base with diversity features and uses a resampled training set. We score 12th from 124 in the ranking for Subtask A (monolingual track), and our results show that our approach is generalizable across unseen models and domains, achieving an accuracy of 0.91.
PetKaz at SemEval-2024 Task 3: Advancing Emotion Classification with an LLM for Emotion-Cause Pair Extraction in Conversations
Apr 08, 2024In this paper, we present our submission to the SemEval-2023 Task~3 "The Competition of Multimodal Emotion Cause Analysis in Conversations", focusing on extracting emotion-cause pairs from dialogs. Specifically, our approach relies on combining fine-tuned GPT-3.5 for emotion classification and a BiLSTM-based neural network to detect causes. We score 2nd in the ranking for Subtask 1, demonstrating the effectiveness of our approach through one of the highest weighted-average proportional F1 scores recorded at 0.264.
What Makes Math Word Problems Challenging for LLMs?
Apr 01, 2024



This paper investigates the question of what makes math word problems (MWPs) in English challenging for large language models (LLMs). We conduct an in-depth analysis of the key linguistic and mathematical characteristics of MWPs. In addition, we train feature-based classifiers to better understand the impact of each feature on the overall difficulty of MWPs for prominent LLMs and investigate whether this helps predict how well LLMs fare against specific categories of MWPs.
REFeREE: A REference-FREE Model-Based Metric for Text Simplification
Mar 26, 2024



Text simplification lacks a universal standard of quality, and annotated reference simplifications are scarce and costly. We propose to alleviate such limitations by introducing REFeREE, a reference-free model-based metric with a 3-stage curriculum. REFeREE leverages an arbitrarily scalable pretraining stage and can be applied to any quality standard as long as a small number of human annotations are available. Our experiments show that our metric outperforms existing reference-based metrics in predicting overall ratings and reaches competitive and consistent performance in predicting specific ratings while requiring no reference simplifications at inference time.
Are LLMs Good Cryptic Crossword Solvers?
Mar 15, 2024



Cryptic crosswords are puzzles that rely not only on general knowledge but also on the solver's ability to manipulate language on different levels and deal with various types of wordplay. Previous research suggests that solving such puzzles is a challenge even for modern NLP models. However, the abilities of large language models (LLMs) have not yet been tested on this task. In this paper, we establish the benchmark results for three popular LLMs -- LLaMA2, Mistral, and ChatGPT -- showing that their performance on this task is still far from that of humans.
How Teachers Can Use Large Language Models and Bloom's Taxonomy to Create Educational Quizzes
Jan 11, 2024Question generation (QG) is a natural language processing task with an abundance of potential benefits and use cases in the educational domain. In order for this potential to be realized, QG systems must be designed and validated with pedagogical needs in mind. However, little research has assessed or designed QG approaches with the input from real teachers or students. This paper applies a large language model-based QG approach where questions are generated with learning goals derived from Bloom's taxonomy. The automatically generated questions are used in multiple experiments designed to assess how teachers use them in practice. The results demonstrate that teachers prefer to write quizzes with automatically generated questions, and that such quizzes have no loss in quality compared to handwritten versions. Further, several metrics indicate that automatically generated questions can even improve the quality of the quizzes created, showing the promise for large scale use of QG in the classroom setting.
BasahaCorpus: An Expanded Linguistic Resource for Readability Assessment in Central Philippine Languages
Oct 17, 2023Current research on automatic readability assessment (ARA) has focused on improving the performance of models in high-resource languages such as English. In this work, we introduce and release BasahaCorpus as part of an initiative aimed at expanding available corpora and baseline models for readability assessment in lower resource languages in the Philippines. We compiled a corpus of short fictional narratives written in Hiligaynon, Minasbate, Karay-a, and Rinconada -- languages belonging to the Central Philippine family tree subgroup -- to train ARA models using surface-level, syllable-pattern, and n-gram overlap features. We also propose a new hierarchical cross-lingual modeling approach that takes advantage of a language's placement in the family tree to increase the amount of available training data. Our study yields encouraging results that support previous work showcasing the efficacy of cross-lingual models in low-resource settings, as well as similarities in highly informative linguistic features for mutually intelligible languages.
The BEA 2023 Shared Task on Generating AI Teacher Responses in Educational Dialogues
Jun 12, 2023


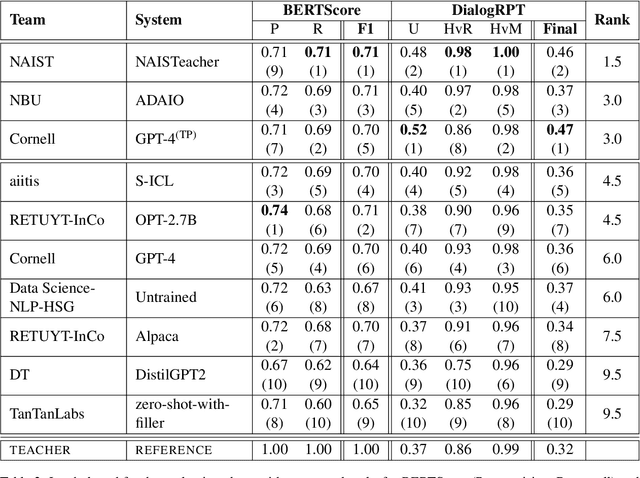
This paper describes the results of the first shared task on the generation of teacher responses in educational dialogues. The goal of the task was to benchmark the ability of generative language models to act as AI teachers, replying to a student in a teacher-student dialogue. Eight teams participated in the competition hosted on CodaLab. They experimented with a wide variety of state-of-the-art models, including Alpaca, Bloom, DialoGPT, DistilGPT-2, Flan-T5, GPT-2, GPT-3, GPT- 4, LLaMA, OPT-2.7B, and T5-base. Their submissions were automatically scored using BERTScore and DialogRPT metrics, and the top three among them were further manually evaluated in terms of pedagogical ability based on Tack and Piech (2022). The NAISTeacher system, which ranked first in both automated and human evaluation, generated responses with GPT-3.5 using an ensemble of prompts and a DialogRPT-based ranking of responses for given dialogue contexts. Despite the promising achievements of the participating teams, the results also highlight the need for evaluation metrics better suited to educational contexts.
Automatic Readability Assessment for Closely Related Languages
May 25, 2023
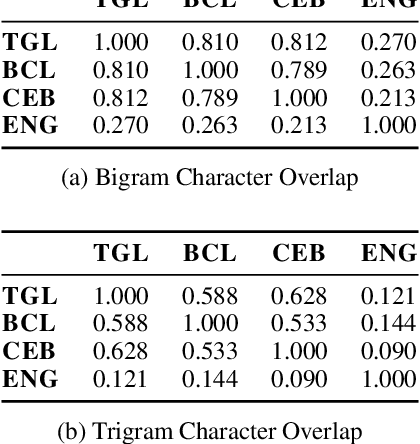
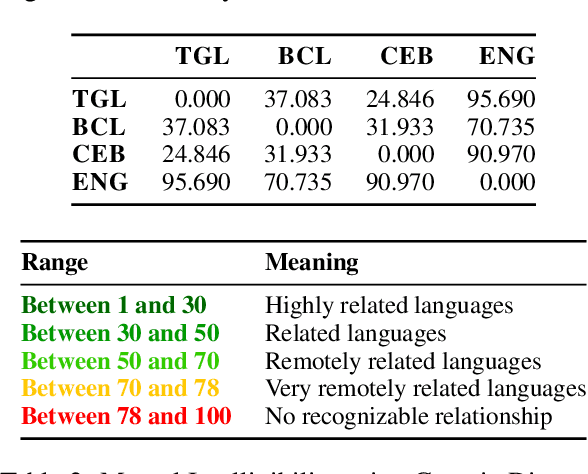
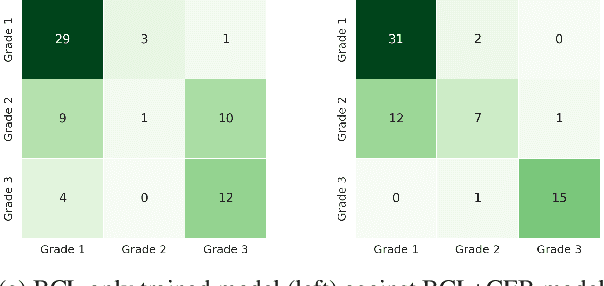
In recent years, the main focus of research on automatic readability assessment (ARA) has shifted towards using expensive deep learning-based methods with the primary goal of increasing models' accuracy. This, however, is rarely applicable for low-resource languages where traditional handcrafted features are still widely used due to the lack of existing NLP tools to extract deeper linguistic representations. In this work, we take a step back from the technical component and focus on how linguistic aspects such as mutual intelligibility or degree of language relatedness can improve ARA in a low-resource setting. We collect short stories written in three languages in the Philippines-Tagalog, Bikol, and Cebuano-to train readability assessment models and explore the interaction of data and features in various cross-lingual setups. Our results show that the inclusion of CrossNGO, a novel specialized feature exploiting n-gram overlap applied to languages with high mutual intelligibility, significantly improves the performance of ARA models compared to the use of off-the-shelf large multilingual language models alone. Consequently, when both linguistic representations are combined, we achieve state-of-the-art results for Tagalog and Cebuano, and baseline scores for ARA in Bikol.