 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeElie Aljalbout
Guided Decoding for Robot Motion Generation and Adaption
Mar 22, 2024
We address motion generation for high-DoF robot arms in complex settings with obstacles, via points, etc. A significant advancement in this domain is achieved by integrating Learning from Demonstration (LfD) into the motion generation process. This integration facilitates rapid adaptation to new tasks and optimizes the utilization of accumulated expertise by allowing robots to learn and generalize from demonstrated trajectories. We train a transformer architecture on a large dataset of simulated trajectories. This architecture, based on a conditional variational autoencoder transformer, learns essential motion generation skills and adapts these to meet auxiliary tasks and constraints. Our auto-regressive approach enables real-time integration of feedback from the physical system, enhancing the adaptability and efficiency of motion generation. We show that our model can generate motion from initial and target points, but also that it can adapt trajectories in navigating complex tasks, including obstacle avoidance, via points, and meeting velocity and acceleration constraints, across platforms.
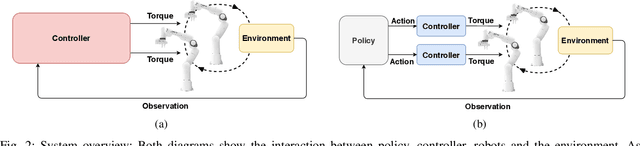
On the Role of the Action Space in Robot Manipulation Learning and Sim-to-Real Transfer
Dec 06, 2023We study the choice of action space in robot manipulation learning and sim-to-real transfer. We define metrics that assess the performance, and examine the emerging properties in the different action spaces. We train over 250 reinforcement learning~(RL) agents in simulated reaching and pushing tasks, using 13 different control spaces. The choice of action spaces spans popular choices in the literature as well as novel combinations of common design characteristics. We evaluate the training performance in simulation and the transfer to a real-world environment. We identify good and bad characteristics of robotic action spaces and make recommendations for future designs. Our findings have important implications for the design of RL algorithms for robot manipulation tasks, and highlight the need for careful consideration of action spaces when training and transferring RL agents for real-world robotics.
CLAS: Coordinating Multi-Robot Manipulation with Central Latent Action Spaces
Nov 28, 2022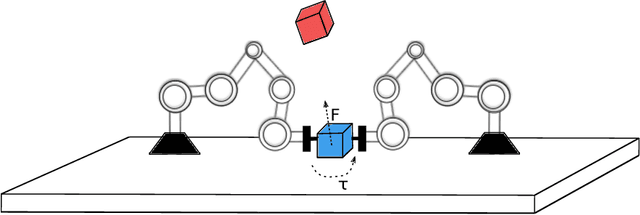
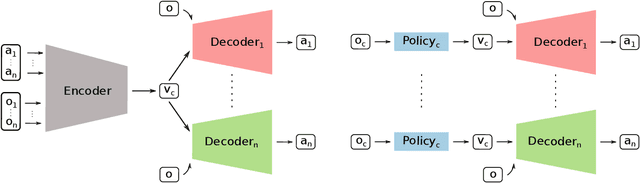
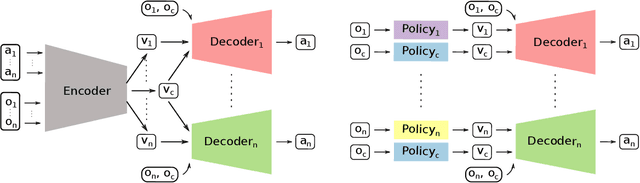

Multi-robot manipulation tasks involve various control entities that can be separated into dynamically independent parts. A typical example of such real-world tasks is dual-arm manipulation. Learning to naively solve such tasks with reinforcement learning is often unfeasible due to the sample complexity and exploration requirements growing with the dimensionality of the action and state spaces. Instead, we would like to handle such environments as multi-agent systems and have several agents control parts of the whole. However, decentralizing the generation of actions requires coordination across agents through a channel limited to information central to the task. This paper proposes an approach to coordinating multi-robot manipulation through learned latent action spaces that are shared across different agents. We validate our method in simulated multi-robot manipulation tasks and demonstrate improvement over previous baselines in terms of sample efficiency and learning performance.
Learning Robotic Manipulation Skills Using an Adaptive Force-Impedance Action Space
Oct 20, 2021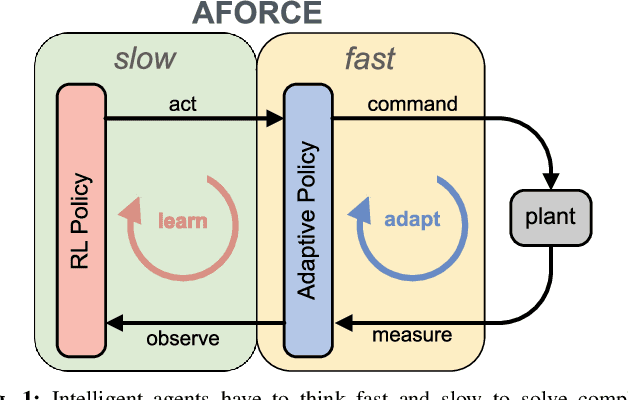
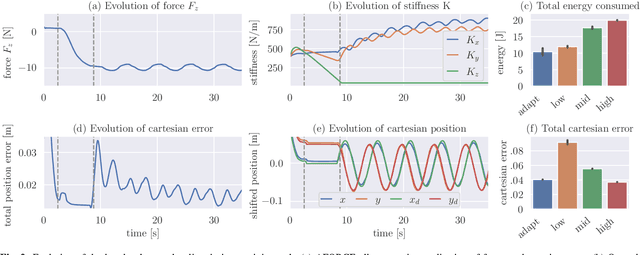
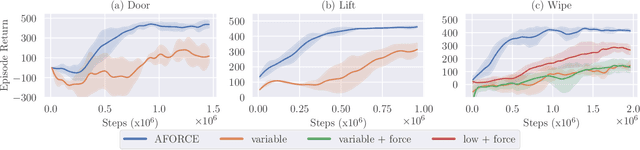
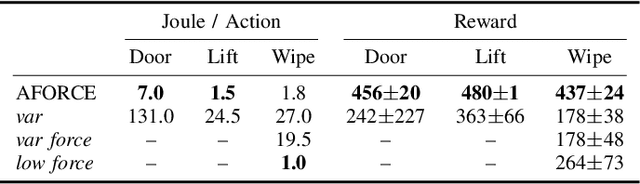
Intelligent agents must be able to think fast and slow to perform elaborate manipulation tasks. Reinforcement Learning (RL) has led to many promising results on a range of challenging decision-making tasks. However, in real-world robotics, these methods still struggle, as they require large amounts of expensive interactions and have slow feedback loops. On the other hand, fast human-like adaptive control methods can optimize complex robotic interactions, yet fail to integrate multimodal feedback needed for unstructured tasks. In this work, we propose to factor the learning problem in a hierarchical learning and adaption architecture to get the best of both worlds. The framework consists of two components, a slow reinforcement learning policy optimizing the task strategy given multimodal observations, and a fast, real-time adaptive control policy continuously optimizing the motion, stability, and effort of the manipulator. We combine these components through a bio-inspired action space that we call AFORCE. We demonstrate the new action space on a contact-rich manipulation task on real hardware and evaluate its performance on three simulated manipulation tasks. Our experiments show that AFORCE drastically improves sample efficiency while reducing energy consumption and improving safety.
Dual-Arm Adversarial Robot Learning
Oct 15, 2021
Robot learning is a very promising topic for the future of automation and machine intelligence. Future robots should be able to autonomously acquire skills, learn to represent their environment, and interact with it. While these topics have been explored in simulation, real-world robot learning research seems to be still limited. This is due to the additional challenges encountered in the real-world, such as noisy sensors and actuators, safe exploration, non-stationary dynamics, autonomous environment resetting as well as the cost of running experiments for long periods of time. Unless we develop scalable solutions to these problems, learning complex tasks involving hand-eye coordination and rich contacts will remain an untouched vision that is only feasible in controlled lab environments. We propose dual-arm settings as platforms for robot learning. Such settings enable safe data collection for acquiring manipulation skills as well as training perception modules in a robot-supervised manner. They also ease the processes of resetting the environment. Furthermore, adversarial learning could potentially boost the generalization capability of robot learning methods by maximizing the exploration based on game-theoretic objectives while ensuring safety based on collaborative task spaces. In this paper, we will discuss the potential benefits of this setup as well as the challenges and research directions that can be pursued.
Learning to Centralize Dual-Arm Assembly
Oct 08, 2021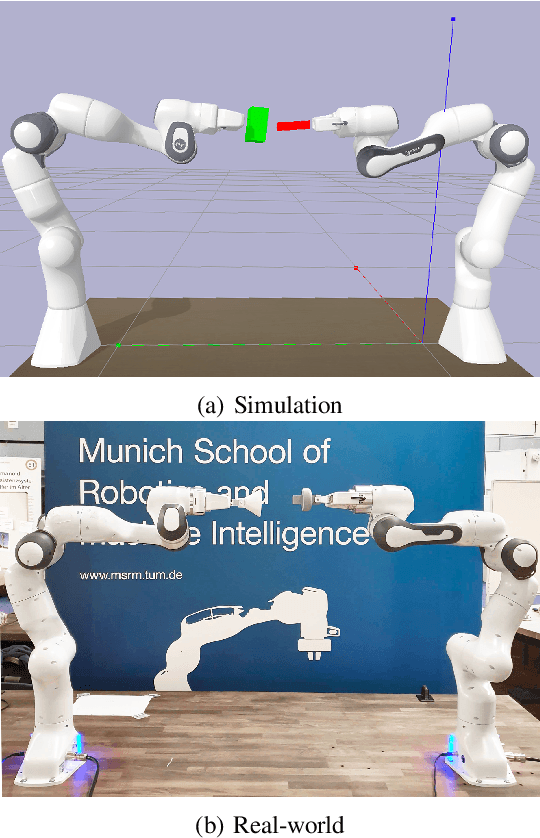
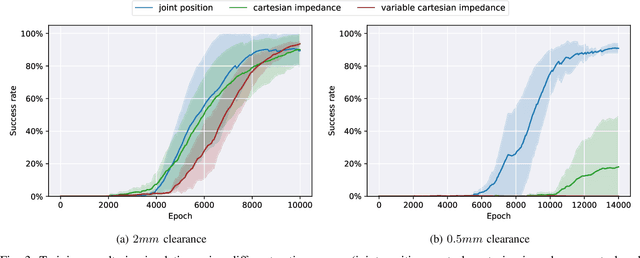
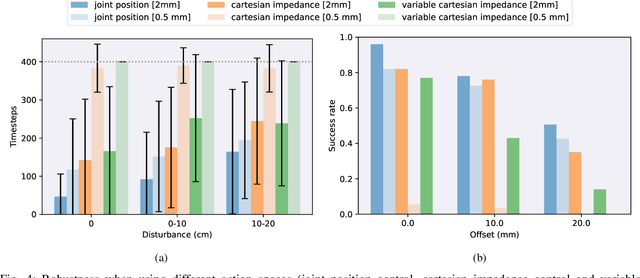
Even though industrial manipulators are widely used in modern manufacturing processes, deployment in unstructured environments remains an open problem. To deal with variety, complexity and uncertainty of real world manipulation tasks a general framework is essential. In this work we want to focus on assembly with humanoid robots by providing a framework for dual-arm peg-in-hole manipulation. As we aim to contribute towards an approach which is not limited to dual-arm peg-in-hole, but dual-arm manipulation in general, we keep modeling effort at a minimum. While reinforcement learning has shown great results for single-arm robotic manipulation in recent years, research focusing on dual-arm manipulation is still rare. Solving such tasks often involves complex modeling of interaction between two manipulators and their coupling at a control level. In this paper, we explore the applicability of model-free reinforcement learning to dual-arm manipulation based on a modular approach with two decentralized single-arm controllers and a single centralized policy. We reduce modeling effort to a minimum by using sparse rewards only. We demonstrate the effectiveness of the framework on dual-arm peg-in-hole and analyze sample efficiency and success rates for different action spaces. Moreover, we compare results on different clearances and showcase disturbance recovery and robustness, when dealing with position uncertainties. Finally we zero-shot transfer policies trained in simulation to the real-world and evaluate their performance.
Seeking Visual Discomfort: Curiosity-driven Representations for Reinforcement Learning
Oct 02, 2021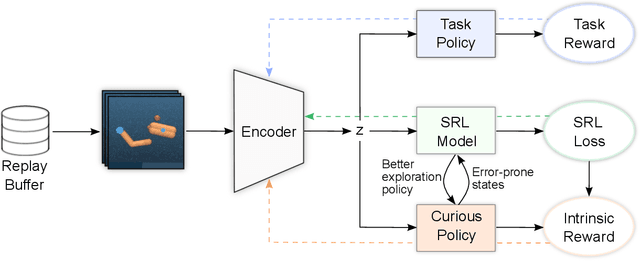
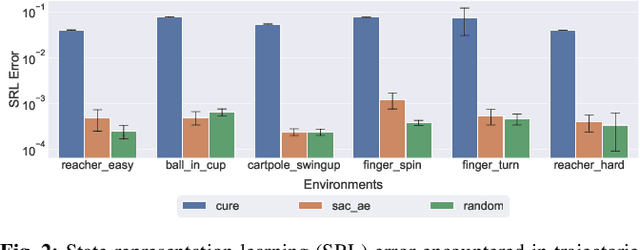
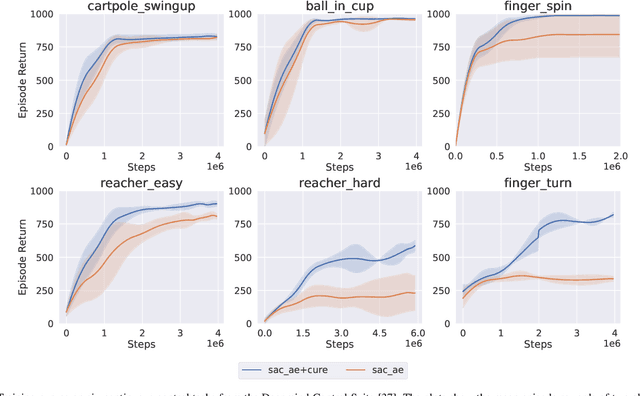
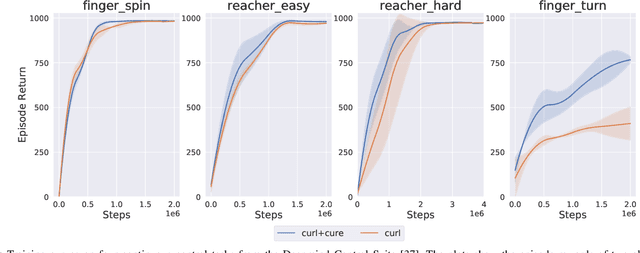
Vision-based reinforcement learning (RL) is a promising approach to solve control tasks involving images as the main observation. State-of-the-art RL algorithms still struggle in terms of sample efficiency, especially when using image observations. This has led to increased attention on integrating state representation learning (SRL) techniques into the RL pipeline. Work in this field demonstrates a substantial improvement in sample efficiency among other benefits. However, to take full advantage of this paradigm, the quality of samples used for training plays a crucial role. More importantly, the diversity of these samples could affect the sample efficiency of vision-based RL, but also its generalization capability. In this work, we present an approach to improve sample diversity for state representation learning. Our method enhances the exploration capability of RL algorithms, by taking advantage of the SRL setup. Our experiments show that our proposed approach boosts the visitation of problematic states, improves the learned state representation, and outperforms the baselines for all tested environments. These results are most apparent for environments where the baseline methods struggle. Even in simple environments, our method stabilizes the training, reduces the reward variance, and promotes sample efficiency.
Making Curiosity Explicit in Vision-based RL
Sep 28, 2021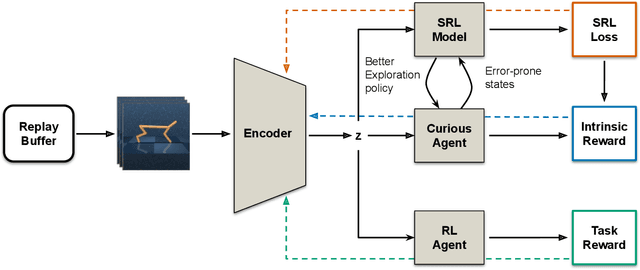
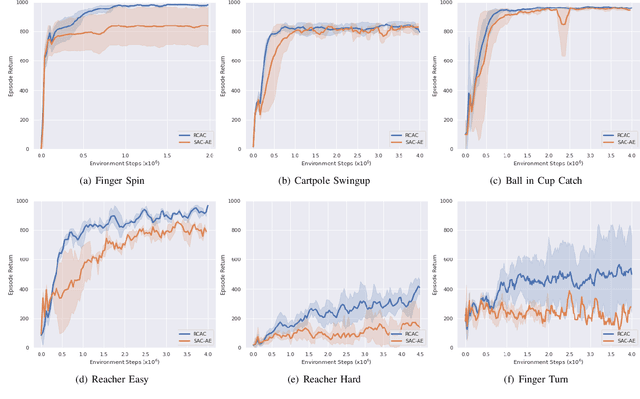
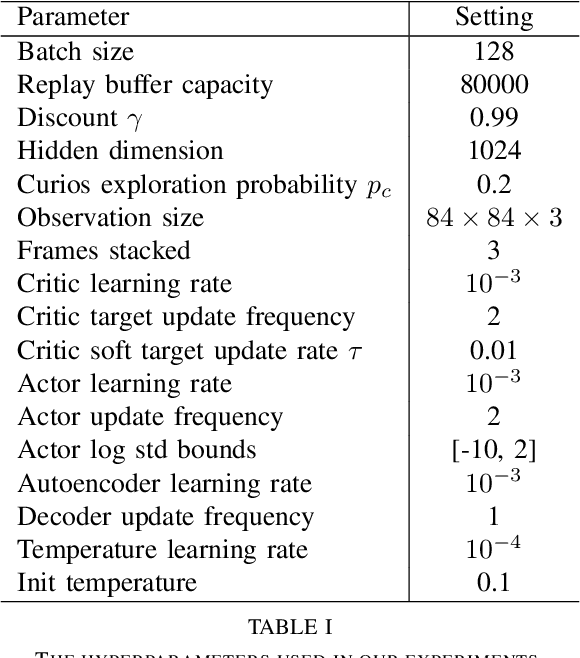
Vision-based reinforcement learning (RL) is a promising technique to solve control tasks involving images as the main observation. State-of-the-art RL algorithms still struggle in terms of sample efficiency, especially when using image observations. This has led to an increased attention on integrating state representation learning (SRL) techniques into the RL pipeline. Work in this field demonstrates a substantial improvement in sample efficiency among other benefits. However, to take full advantage of this paradigm, the quality of samples used for training plays a crucial role. More importantly, the diversity of these samples could affect the sample efficiency of vision-based RL, but also its generalization capability. In this work, we present an approach to improve the sample diversity. Our method enhances the exploration capability of the RL algorithms by taking advantage of the SRL setup. Our experiments show that the presented approach outperforms the baseline for all tested environments. These results are most apparent for environments where the baseline method struggles. Even in simple environments, our method stabilizes the training, reduces the reward variance and boosts sample efficiency.
How to Make Deep RL Work in Practice
Nov 10, 2020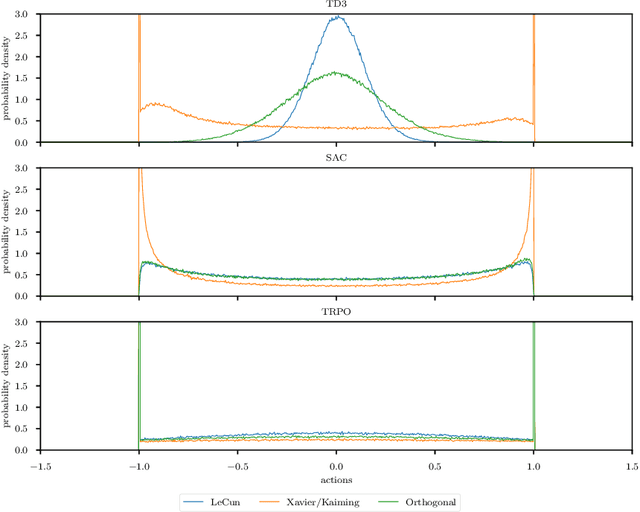



In recent years, challenging control problems became solvable with deep reinforcement learning (RL). To be able to use RL for large-scale real-world applications, a certain degree of reliability in their performance is necessary. Reported results of state-of-the-art algorithms are often difficult to reproduce. One reason for this is that certain implementation details influence the performance significantly. Commonly, these details are not highlighted as important techniques to achieve state-of-the-art performance. Additionally, techniques from supervised learning are often used by default but influence the algorithms in a reinforcement learning setting in different and not well-understood ways. In this paper, we investigate the influence of certain initialization, input normalization, and adaptive learning techniques on the performance of state-of-the-art RL algorithms. We make suggestions which of those techniques to use by default and highlight areas that could benefit from a solution specifically tailored to RL.
Learning Vision-based Reactive Policies for Obstacle Avoidance
Oct 30, 2020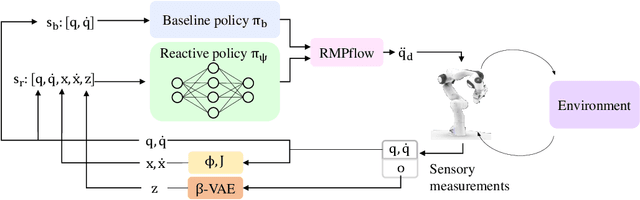
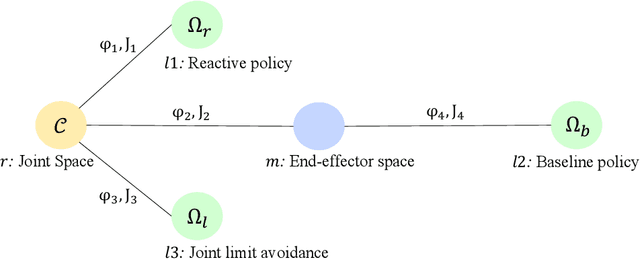

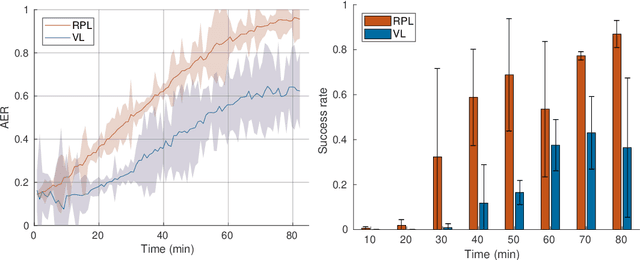
In this paper, we address the problem of vision-based obstacle avoidance for robotic manipulators. This topic poses challenges for both perception and motion generation. While most work in the field aims at improving one of those aspects, we provide a unified framework for approaching this problem. The main goal of this framework is to connect perception and motion by identifying the relationship between the visual input and the corresponding motion representation. To this end, we propose a method for learning reactive obstacle avoidance policies. We evaluate our method on goal-reaching tasks for single and multiple obstacles scenarios. We show the ability of the proposed method to efficiently learn stable obstacle avoidance strategies at a high success rate, while maintaining closed-loop responsiveness required for critical applications like human-robot interaction.