 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeElizabeth Daly
Ranking Large Language Models without Ground Truth
Feb 21, 2024
Evaluation and ranking of large language models (LLMs) has become an important problem with the proliferation of these models and their impact. Evaluation methods either require human responses which are expensive to acquire or use pairs of LLMs to evaluate each other which can be unreliable. In this paper, we provide a novel perspective where, given a dataset of prompts (viz. questions, instructions, etc.) and a set of LLMs, we rank them without access to any ground truth or reference responses. Inspired by real life where both an expert and a knowledgeable person can identify a novice our main idea is to consider triplets of models, where each one of them evaluates the other two, correctly identifying the worst model in the triplet with high probability. We also analyze our idea and provide sufficient conditions for it to succeed. Applying this idea repeatedly, we propose two methods to rank LLMs. In experiments on different generative tasks (summarization, multiple-choice, and dialog), our methods reliably recover close to true rankings without reference data. This points to a viable low-resource mechanism for practical use.
Explaining Knock-on Effects of Bias Mitigation
Dec 01, 2023In machine learning systems, bias mitigation approaches aim to make outcomes fairer across privileged and unprivileged groups. Bias mitigation methods work in different ways and have known "waterfall" effects, e.g., mitigating bias at one place may manifest bias elsewhere. In this paper, we aim to characterise impacted cohorts when mitigation interventions are applied. To do so, we treat intervention effects as a classification task and learn an explainable meta-classifier to identify cohorts that have altered outcomes. We examine a range of bias mitigation strategies that work at various stages of the model life cycle. We empirically demonstrate that our meta-classifier is able to uncover impacted cohorts. Further, we show that all tested mitigation strategies negatively impact a non-trivial fraction of cases, i.e., people who receive unfavourable outcomes solely on account of mitigation efforts. This is despite improvement in fairness metrics. We use these results as a basis to argue for more careful audits of static mitigation interventions that go beyond aggregate metrics.
Iterative Reward Shaping using Human Feedback for Correcting Reward Misspecification
Aug 30, 2023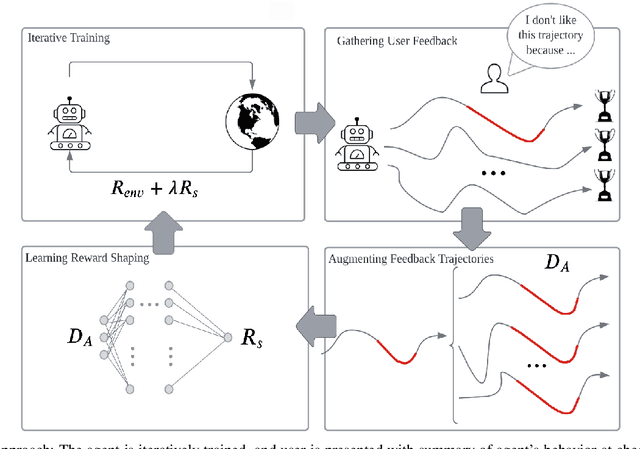

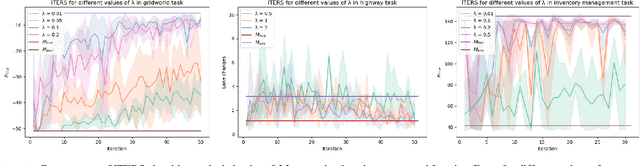
A well-defined reward function is crucial for successful training of an reinforcement learning (RL) agent. However, defining a suitable reward function is a notoriously challenging task, especially in complex, multi-objective environments. Developers often have to resort to starting with an initial, potentially misspecified reward function, and iteratively adjusting its parameters, based on observed learned behavior. In this work, we aim to automate this process by proposing ITERS, an iterative reward shaping approach using human feedback for mitigating the effects of a misspecified reward function. Our approach allows the user to provide trajectory-level feedback on agent's behavior during training, which can be integrated as a reward shaping signal in the following training iteration. We also allow the user to provide explanations of their feedback, which are used to augment the feedback and reduce user effort and feedback frequency. We evaluate ITERS in three environments and show that it can successfully correct misspecified reward functions.
Leveraging Explanations in Interactive Machine Learning: An Overview
Jul 29, 2022



Explanations have gained an increasing level of interest in the AI and Machine Learning (ML) communities in order to improve model transparency and allow users to form a mental model of a trained ML model. However, explanations can go beyond this one way communication as a mechanism to elicit user control, because once users understand, they can then provide feedback. The goal of this paper is to present an overview of research where explanations are combined with interactive capabilities as a mean to learn new models from scratch and to edit and debug existing ones. To this end, we draw a conceptual map of the state-of-the-art, grouping relevant approaches based on their intended purpose and on how they structure the interaction, highlighting similarities and differences between them. We also discuss open research issues and outline possible directions forward, with the hope of spurring further research on this blooming research topic.
Boolean Decision Rules for Reinforcement Learning Policy Summarisation
Jul 18, 2022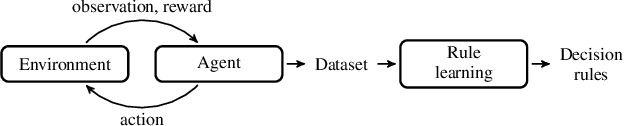

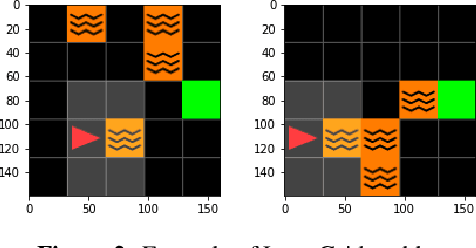

Explainability of Reinforcement Learning (RL) policies remains a challenging research problem, particularly when considering RL in a safety context. Understanding the decisions and intentions of an RL policy offer avenues to incorporate safety into the policy by limiting undesirable actions. We propose the use of a Boolean Decision Rules model to create a post-hoc rule-based summary of an agent's policy. We evaluate our proposed approach using a DQN agent trained on an implementation of a lava gridworld and show that, given a hand-crafted feature representation of this gridworld, simple generalised rules can be created, giving a post-hoc explainable summary of the agent's policy. We discuss possible avenues to introduce safety into a RL agent's policy by using rules generated by this rule-based model as constraints imposed on the agent's policy, as well as discuss how creating simple rule summaries of an agent's policy may help in the debugging process of RL agents.
Contrastive Explanations for Comparing Preferences of Reinforcement Learning Agents
Dec 17, 2021


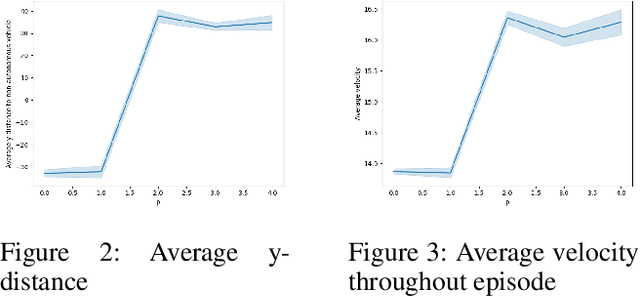
In complex tasks where the reward function is not straightforward and consists of a set of objectives, multiple reinforcement learning (RL) policies that perform task adequately, but employ different strategies can be trained by adjusting the impact of individual objectives on reward function. Understanding the differences in strategies between policies is necessary to enable users to choose between offered policies, and can help developers understand different behaviors that emerge from various reward functions and training hyperparameters in RL systems. In this work we compare behavior of two policies trained on the same task, but with different preferences in objectives. We propose a method for distinguishing between differences in behavior that stem from different abilities from those that are a consequence of opposing preferences of two RL agents. Furthermore, we use only data on preference-based differences in order to generate contrasting explanations about agents' preferences. Finally, we test and evaluate our approach on an autonomous driving task and compare the behavior of a safety-oriented policy and one that prefers speed.
Designing Machine Learning Pipeline Toolkit for AutoML Surrogate Modeling Optimization
Jul 14, 2021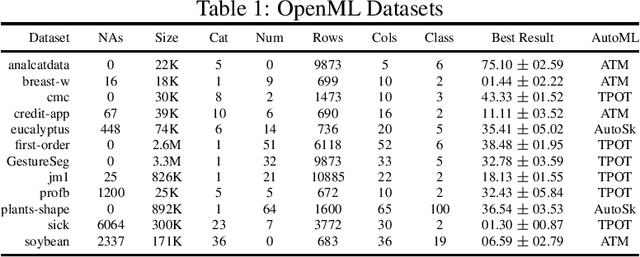
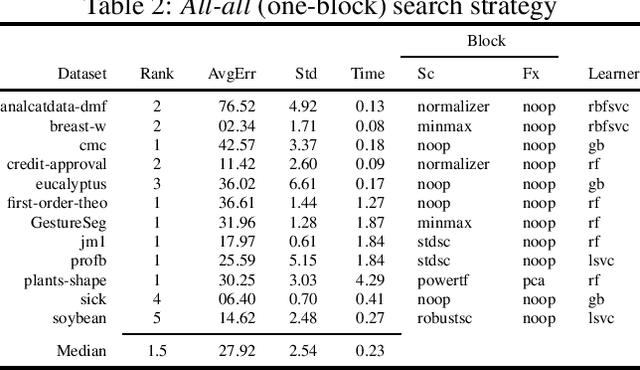
The pipeline optimization problem in machine learning requires simultaneous optimization of pipeline structures and parameter adaptation of their elements. Having an elegant way to express these structures can help lessen the complexity in the management and analysis of their performances together with the different choices of optimization strategies. With these issues in mind, we created the AutoMLPipeline (AMLP) toolkit which facilitates the creation and evaluation of complex machine learning pipeline structures using simple expressions. We use AMLP to find optimal pipeline signatures, datamine them, and use these datamined features to speed-up learning and prediction. We formulated a two-stage pipeline optimization with surrogate modeling in AMLP which outperforms other AutoML approaches with a 4-hour time budget in less than 5 minutes of AMLP computation time.
Generating Dialogue Agents via Automated Planning
Feb 02, 2019
Dialogue systems have many applications such as customer support or question answering. Typically they have been limited to shallow single turn interactions. However more advanced applications such as career coaching or planning a trip require a much more complex multi-turn dialogue. Current limitations of conversational systems have made it difficult to support applications that require personalization, customization and context dependent interactions. We tackle this challenging problem by using domain-independent AI planning to automatically create dialogue plans, customized to guide a dialogue towards achieving a given goal. The input includes a library of atomic dialogue actions, an initial state of the dialogue, and a goal. Dialogue plans are plugged into a dialogue system capable to orchestrate their execution. Use cases demonstrate the viability of the approach. Our work on dialogue planning has been integrated into a product, and it is in the process of being deployed into another.